Классификация арматура и маркировка: Класс арматуры — соответствие старой и новой маркировки (таблица)
Содержание
маркировка, таблица классификации марок арматурной стали, характеристики и их применение.
Без арматуры сегодня не обходится ни один крупный строительный объект, на котором используется бетон. Ведь последний, несмотря на высокую прочность, легко повреждается при работе на изгиб и растяжение. Благодаря металлическим прутам этот недостаток устраняется, и набравший достаточную прочность материал способен выдерживать значительные нагрузки всех типов без вреда для себя. Но для каждого строительного объекта подходящим выбором станут разные материалы и, соответственно, разный класс арматуры. В одном случае стоит отдать предпочтение тонкой арматуре одной марки стали, способной без вреда для себя годами работать в агрессивной окружающей среде. А в другом понадобится толстая арматура из другой марки стали. Расскажем об этом.
Зачем используются классы арматуры?
Сегодня изготавливаются металлические пруты, различающиеся между собой по ряду факторов. Чтобы отобразить характеристики материала, являющиеся важнейшими при выборе для конкретного строительного объекта, была разработана специальная классификация арматуры. Опытному строителю или проектировщику достаточно взглянуть на марку материала, чтобы точно узнать всю необходимую информацию:
Чтобы отобразить характеристики материала, являющиеся важнейшими при выборе для конкретного строительного объекта, была разработана специальная классификация арматуры. Опытному строителю или проектировщику достаточно взглянуть на марку материала, чтобы точно узнать всю необходимую информацию:
- метод изготовления;
- класс;
- диаметр;
- особые свойства.
Точно также, выполняя работы по проектированию или строительству, профессионал может легко представить все нагрузки, какие должен будет выдерживать материал и точно назвать класса арматуры, которые понадобятся для конкретного объекта. Начнем расшифровку с самого начала.
Необходимость применения
Арматура нужна для прочности и выносливости бетона и используется в процессе любого строительства. Устойчивость бетона к растяжению, намного меньше чем к фактору сжатия. Благодаря рифленой поверхности арматура хорошо закрепляется в бетоне и уменьшает его деформацию.
Арматура – это металлическое изделия в виде стержня
Чистый бетон не имеет высокого свойства прочности, и чтобы увеличить его долговечность, бетон и арматуру соединили в железобетоне. Железобетонные конструкции предназначены надежному укреплению постройки в сравнении с обычным бетоном:
Железобетонные конструкции предназначены надежному укреплению постройки в сравнении с обычным бетоном:
- арматура защищает бетон от резких перепадов температуры;
- повышается прочность при одновременном воздействии факторов сдавливания и растяжения;
- арматура препятствует образованию бетонных трещин.
Арматура используется и в фундаменте. Он берет на себя любые виды нагрузок от вышестоящих конструкций и потому должен быть максимально прочным. Дополнительно на фундамент воздействуют движения грунтов и морозное пучение. Арматура в фундаменте работает как эффективная защита и помогает сопротивляться разрушению бетона.
Как изготавливается арматура?
В первую очередь в маркировке арматуры упоминается метод изготовления. Например, в марке А240 литера “А” обозначает, что материал является горячекатаным или же холоднокатаным.
Ещё одна литера – “Ат”. Она обозначает, что вы имеете дело с термоупрочненной арматурой. Её стоимость выше, так как в производстве она сложнее.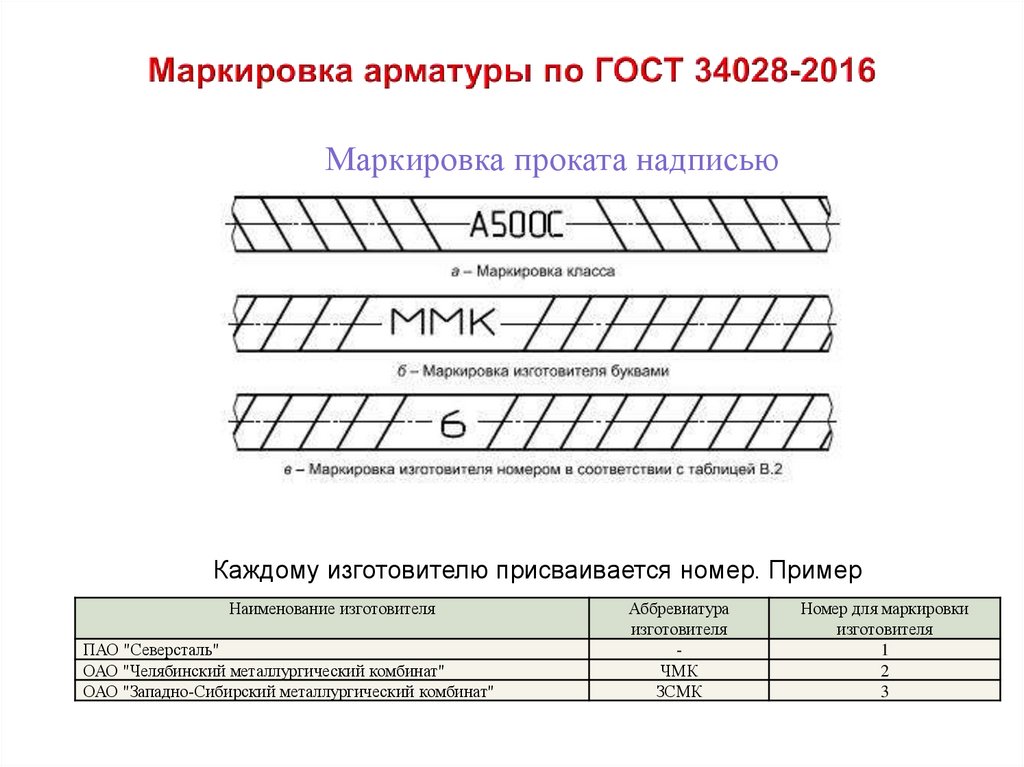 Сначала прут разогревается до температуры в 1000 градусов по Цельсию, после чего за считанные секунды охлаждается до +500 градусов. Благодаря этому прут обладает куда большей прочностью. Поэтому он находит применение в разных сферах, начиная от строительства, когда на железобетон приходится большая нагрузка, и заканчивая машиностроением и изготовлением мебели.
Сначала прут разогревается до температуры в 1000 градусов по Цельсию, после чего за считанные секунды охлаждается до +500 градусов. Благодаря этому прут обладает куда большей прочностью. Поэтому он находит применение в разных сферах, начиная от строительства, когда на железобетон приходится большая нагрузка, и заканчивая машиностроением и изготовлением мебели.
Также в некоторых случаях встречается литера “В”. Она указывает, что арматура является холоднодеформированной. Кроме того, существует литера “К” – канаты. Это уже другая специализация, но чтобы иметь возможность легко и быстро расшифровать класс, эту литеру также будет полезно запомнить.
Функциональность
Для армирования сборного железобетона используется арматура до класса А600. Классы выше этого закладываются в напряжённые ЖБ конструкции.
Виды арматуры по назначению.
- Рабочая (продольная и поперечная): принимает основные типы нагрузок в железобетонном изделии, диаметр определяется расчётами.
- Монтажная (распределительная и конструктивная): для формирования объёмных каркасов, сеток.

- Распределительная: обеспечивает правильное расположение рабочих стержней.
- Конструкционная: не рассчитывается; устанавливается в местах, которые могут подвергаться случайным нагрузкам.
- Анкерная: для формирования закладных элементов, в том числе захватных петель.
Расход арматуры всех видов в железобетонных конструкциях составляет от 50 до 80 кг на кубометр бетона, но не менее 8 кг. Расчёт необходимого количества для ленточного фундамента приведён ниже.
Основные виды арматуры
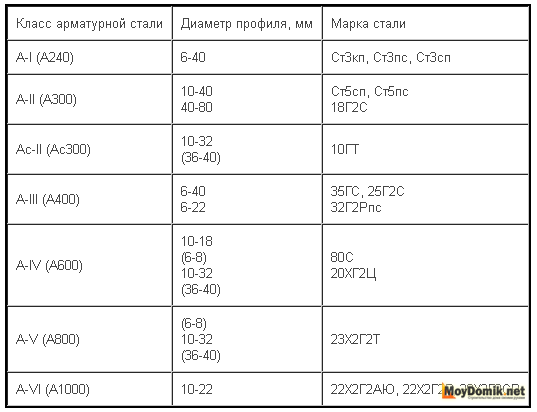
Следующим упоминается сам класс арматурной стали. Всего существует шесть классов:
- А240;
- А300;
- А400;
- А600;
- А800;
- А1000.
Кроме того, в некоторых случаях встречается иное обозначение – А1, А2 … А6. Но это обозначение считается устаревшим – оно применялось в Совестком Союзе и именно его использовал действующий на тот момент ГОСТ. Сегодня большинство производителей и покупателей использует иную классификацию сортамента арматуры.
А240 – единственная марка, которая выпускается с гладким сечением. Её диаметр может колебаться от 6 до 40 миллиметров. Простота изготовления снижает стоимость материала, но его нельзя использовать в качестве основного рабочего – только в качестве вспомогательного, например, при изготовлении каркаса. Гладкая поверхность ухудшает сцепление с бетоном, в результате ухудшая свойства железобетона. Временно может сопротивляться растяжению до 380 мегапаскалей.
Класс арматуры А-I(А240)
Все остальные классы имеют периодическое сечение, то есть, на поверхности находятся ребра, улучшающие качество сцепления с бетоном. Для большей наглядности сведем все их характеристики воедино – таблица позволит легко подобрать подходящий материал, а также понять значение маркировки:
| Класс | Диаметр, мм | Временное сопротивление растяжению, МПа | Предел текучести, не менее, МПа |
| А-2 | 10—80 | 500 | 300 |
| А-3 | 6—40 | 600 | 400 |
| A-4 | 10—22 | 900 | 600 |
| A-5 | 10—22 | 1050 | 800 |
| Aт-4 | 10—40 | 900 | 600 |
| Aт-5 | 10—40 | 1000 | 800 |
| Aт-6 | 10—22 | 1200 | 1000 |
| Aт-7 | 10—32 | 1400 | 1200 |
Как видите, диаметр может различаться, что позволяет подобрать подходящий материал для каждого конкретного строительного объекта.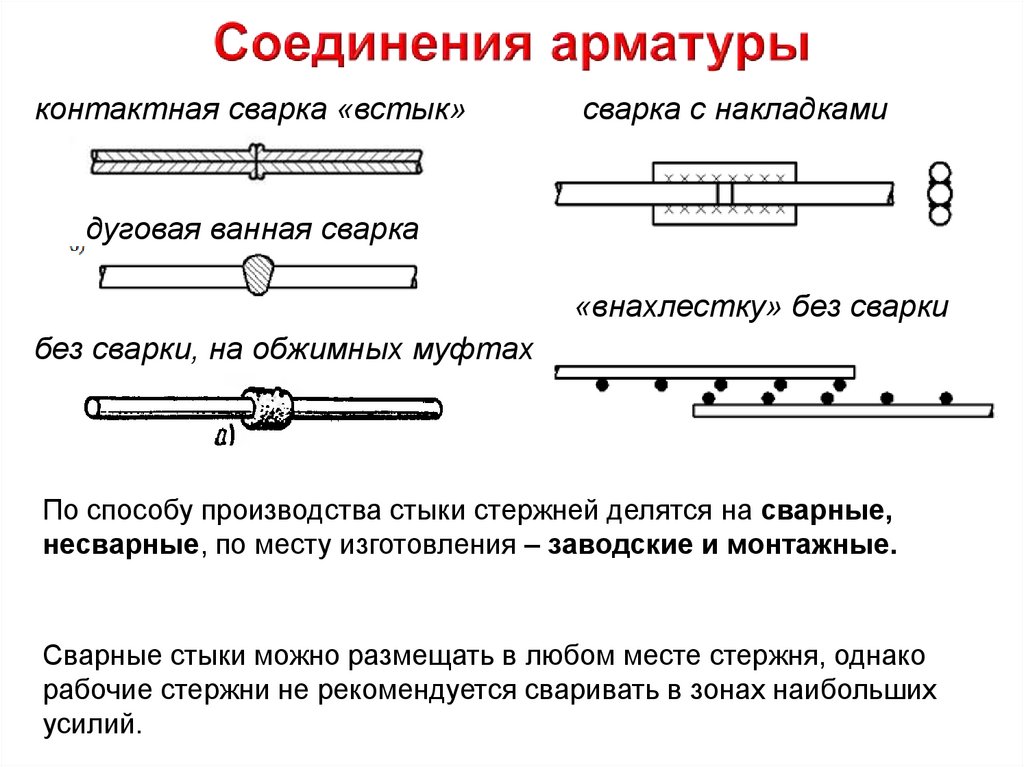
Классификация
В строительстве существует огромное количество операций, где присутствие арматуры обязательно. Все процессы разные, каждому предъявляются свои требования. Поэтому даже профессионалы не всегда могут сказать, где и какая арматура должна использоваться. Поэтому и была проведена классификация арматурных стержней, цель которой – упростить выбор и провести унификацию продукции.
Горячекатаная арматура
Стальная арматура делится на классы в зависимости от разных параметров.
- По технологии изготовления она относится к категориям горячекатаной, холоднодеформированной и катаной.
- По типу профиля: рифленая и гладкая. К первой относятся классы А2, А3, А4 и А5, ко второй А1.
- По эксплуатационным условиям: напрягаемая и ненапрягаемая. В первом случае сооружения каркаса или армирующей сетки арматуру натягивают, заливают бетоном, а после его высыхания освобождают. Происходит сжатие стали, которая сжимает и бетонную конструкцию.
- По ориентации в арматурных каркасах она может быть продольной или поперечной.
 В продольных рядах арматурные стержни класса А1 устанавливать не рекомендуется. И подвергать ее сварке нельзя.
В продольных рядах арматурные стержни класса А1 устанавливать не рекомендуется. И подвергать ее сварке нельзя.
Технология производства холоднодеформированной арматуры
Отдельно в классификации стоит разделение по химическому составу металла (стали). Три позиции:
- В основе лежит класс прочности. Он разделяется на несколько позиций. Существует разные обозначения типов арматуры, поэтому иногда потребители путаются. К примеру, класс А1, он же АI или А240. Соответственно А2-AII-А300; А3-АIII-А400; А4-АIV-А500; А5-АV-А600 и так далее.
- Производители выпускают термически упрочненную арматуру, в маркировку которой входит буква «т». Здесь шесть классов. Ат400, Ат500, Ат600, Ат800, Ат1000, Ат1200. Если просто, то в процессе производства арматурных стержней при горячей деформации производят дополнительное быстрое охлаждение, за счет чего увеличиваются прочностные характеристики металла.
- По степени окисления: СП – спокойная, КП – кипящая, ПС – полуспокойная.
 В основе разделения лежит технология производства. К примеру, кипящая сталь получила название, потому что в процессе заливки из нее бурно выделяются газы, она кипит. Это самая низкосортная сталь за счет образования внутри большого количества пор от выделяющегося газа. Из трех групп при сооружении арматурных каркасов и сеток лучше выбирать спокойную.
В основе разделения лежит технология производства. К примеру, кипящая сталь получила название, потому что в процессе заливки из нее бурно выделяются газы, она кипит. Это самая низкосортная сталь за счет образования внутри большого количества пор от выделяющегося газа. Из трех групп при сооружении арматурных каркасов и сеток лучше выбирать спокойную.
При выборе обращайте внимание на арматурные классы. Они определяют в какую конструкцию какую арматуру надо укладывать. По классам четко проведено разделение основных параметров и характеристик стального профиля. А именно диаметра, предела прочности на разрыв и исходного материала, из которого изделие выпускается. Ниже приведена упрощенная таблица, в которой параметры разбросаны в зависимости от класса арматурных стержней.
Таблица арматурных классов
Как определить диаметр?
Важнейшим параметром является именно диаметр. От него зависит, какую нагрузку он сможет выдержать, предел тягучести и ряд других. Поэтому при обозначении марки арматуры обязательно указывается её диаметр. Целиком классификация выглядит следующим образом: А200 D30. Именно последнее число, идущее после буквы D или символа Ø показывает толщину прута.
Целиком классификация выглядит следующим образом: А200 D30. Именно последнее число, идущее после буквы D или символа Ø показывает толщину прута.
Некоторые дотошные покупатели, выбирая подходящий материал, сверяют его реальную толщину с указанной в паспорте, используя штангенциркуль. Им нередко приходится удивляться серьёзному несоответствию – различие может составлять несколько миллиметров. Однако, стоит учитывать, что при периодическом сечении (то есть, наличии рёбер на пруте) замерить номинальный диаметр невозможно. В узких местах он будет меньше указанного значения, а на ребрах – больше. Поэтому специалисты используют усредненное значение. Его характеристики и указывают в таблицах.
Область применения
Арматура очень широко применяется в строительстве:
- гражданские здания;
- мосты, гидроэлектростанции и плотины;
Арматура в строительстве
- заводы и фабрики;
- применяется в закладке фундаментов;
- шахты, аэродромы и портовые сооружения.

Арматуру используют в изготовлении ломов и штифтов, кроме того, прутья популярны в частном применении на дачных участках (в пристройках, заборах и сараях).
Особые свойства
Также арматуру различают по назначению. В сравнительно редких случаях металлический прут должен иметь ряд свойств, делающих его подходящим для применения. Этого добиваются разными способами – путем добавления специальных примесей в сплав или же особой обработкой. В любом случае, арматура приобретает уникальные характеристики. На наличие особых свойств указывает литера, стоящая в конце кодировки. Обычно встречаются следующие обозначения:
- С – свариваемая. Обычно при сборке из арматуры каркаса использование сварки крайне нежелательно – перегрев снижает прочность, а кроме того, снижает устойчивость перед коррозией. Но существует специальный металл, в состав которого входят добавки, повышающим его возможность противостоять негативным последствиям;
- К – устойчивая перед коррозией.
 Благодаря специальным добавкам (хром, вольфрам и прочие), арматура способна на протяжении многих лет работать не только в условиях повышенной влажности, но и при контакте с агрессивной средой – щелочной, кислой, обладающей повышенным содержанием кислорода;
Благодаря специальным добавкам (хром, вольфрам и прочие), арматура способна на протяжении многих лет работать не только в условиях повышенной влажности, но и при контакте с агрессивной средой – щелочной, кислой, обладающей повышенным содержанием кислорода; - СК – арматура, обладающая обоими вышеперечисленными свойствами. Имеет высокую стоимость, поэтому используется сравнительно редко, только когда обычная не справляется со сложными условиями эксплуатации.
Конечно, на эту продукцию существует специальный ГОСТ, предъявляющий к ней особые требования.
Дополнительная маркировка
Так, согласно ГОСТ класс арматуры с индексом «Т» относится к металлопрокату с термообработкой прутка. Буква «К» указывает на противокоррозионный цинковый слой, а «СК» — возможность его сварки при сборке конструкций. Такое обозначение нужно для выбора способа монтажа, например, оцинкованные стержни предназначены для крепления «вязкой».
Цветовая маркировка арматуры из низколегированной стали:
- А-IV – красный;
- A-V – красный с зеленым;
- A-VI – красный с синим.

Если стержни произведены из термоупрочненного металла, обозначение несколько иное:
- АТ-III – белый с синим;
- AT-IV – белый с желтым;
- AT-4K – зеленый;
- AT-V – синий;
- AT-V-CK – белый с зеленым;
- AT-VK – желтый с зеленым;
- AT-VI – желтый;
- AT – VIK – желтый с синим.
Если прутья изготовлены с соблюдением требований по маркировке различить их выйдет по виду. Визуально важен и рисунок профиля, он считается ключевым признаком после свойств материала. Правда, без буквенно-цифровой маркировки не обойтись. Например, для сварочных работ берут арматуру с индексом «С», тогда как остальные модификации подходят лишь для связки проволокой или соединения специальными муфтами.
Классификация арматуры и маркировка по назначению
✅ Дата публикации: 06.11.2021 | 📒 Полезные советы | 🕵 Комментариев нет
Классификация арматуры
Содержание статьи:
- 1 Классификация арматуры
- 1.
 1 Арматура по условию применения
1 Арматура по условию применения - 1.2 Классы прочности арматуры
- 1.
- 2 Композитная арматура: плюсы и минусы
Арматура представляет собой длинномерный сортовой металлопрокат, который широко используется в строительстве. Основная функция арматуры связана с армированием конструкций и перераспределением нагрузок от строения.
Бывает арматура периодического и постоянного сечения, легкой и тяжелой, если её диаметр составляет 12 или 40 мм. На сегодняшнее время существуют различные виды арматуры, которые делятся на монтажную, рабочую и распределительную арматуру.
К отдельным видам относится арматурная сетка, которая применяется для заливки фундамента и стяжки пола.
Классификация арматуры
Классификация арматуры происходит не только по назначению, но и внешнем виду, а также, условиям применения: https://budkombinat.com.ua/tovar_nedeli.php.
Арматура по назначению бывает:
- Рабочей и конструктивной;
- Монтажной;
- Анкерной в виде закладных деталей.

Что касается ориентации в конструкции, то чаще всего, арматура здесь применяется в качестве поперечных и продольных элементов. Подобного рода элементы призваны для того, чтобы препятствовать разрушению конструкции.
Арматура по условию применения
По условиям применения бывает напрягаемая и ненапрягаемая арматура. Также данный металлопрокат классифицируется по методу производства. Арматура бывает горячекатаная и холоднотянутая.
Не менее значимым в классификации арматуры является и её внешний вид.
Кольцевидная арматура имеет повышенное сцепление с бетоном. Гладкая матовая арматура не имеет такого свойства и применяется соответственно совсем для других целей в строительстве.
Классы прочности арматуры
За предел текучести отвечают классы прочности арматуры:
- А-I, А-II, А-III, А-IV, А-V, А-VI старая маркировка;
- А240, А300, А400, А500, А600, А800, А1000 новая маркировка арматуры;
- Ат400, Ат500, Ат600, Ат800, Ат1000, Ат1200 данная арматура применяется для изготовления различных железобетонных изделий и конструкций из бетона.
Буква «А» в маркировке арматуры означает вид. В данном случае это стержневая арматура. Буква «В» указывает на проволоку, а «К» на канат. Важна в маркировке арматуры и буква «С», указывающая на то, что арматуру допускается варить.
Композитная арматура: плюсы и минусы
Сегодня на смену стальной арматуры приходит композитная арматура, которая имеет как преимущества, так и недостатки.
Плюсы пластиковой композитной арматуры связаны вот с чем:
- Малый вес;
- Высокая прочность на разрыв;
- Устойчивость к химической и антикоррозийной активности;
- В низкой теплопроводности;
- В диэлектрических свойствах.
Композитная арматура не проводит электричество, однако она боится высоких температур. Пожалуй, это самый большой недостаток композитной арматуры, который существенно ограничивает сферы её применения в строительстве.
Оценить статью и поделиться ссылкой:
Обучение с подкреплением: современная классификация методов машинного обучения (часть 3) | Донни Сох
В этой третьей части серии под названием «Обучение машинному обучению» мы обсудим последний класс методов машинного обучения: обучение с подкреплением. Если вы хотите прочитать мой взгляд на контролируемое/неконтролируемое обучение, вы можете прочитать его здесь и здесь .
Если вы хотите прочитать мой взгляд на контролируемое/неконтролируемое обучение, вы можете прочитать его здесь и здесь .
Как уже упоминалось, современные алгоритмы машинного обучения можно разделить на один из трех классов: обучение с учителем, обучение без учителя и обучение с подкреплением. Это разделение выбрано из-за того, как эти алгоритмы изучают модель машинного обучения. В частности:
Стремительный рост индустрии машинного обучения возродил интерес людей к искусственному…
Во время наших предыдущих обсуждений мы упоминали, что обучение с учителем обычно состоит из помеченных данных, тогда как обучение без учителя работает с данными без меток обучения.
Вы можете считать обучение с подкреплением (RL) другим, потому что вы не начинаете с каких-либо данных. Скорее вы начинаете с понимания проблемы, которую пытаетесь решить. Например, если вы хотите решить навигационную задачу о перемещении из пункта А в пункт Б с помощью обучения с подкреплением, вам необходимо определить следующее:
- Агент
- в точку B.
 Это может включать различные промежуточные этапы вознаграждения между точками A и B.
Это может включать различные промежуточные этапы вознаграждения между точками A и B. - Окружающая среда ( состояние ) и то, как агент наблюдает среду, в которой находятся точки A и B. двигаться вверх, вниз, влево, вправо)
В этом навигационном примере агент находится в среде, и его цель состоит в том, чтобы добраться из точки A в точку B. Агент достигает этой цели, выполняя действий . Эти действия агента могут привести к вознаграждает , чтобы мотивировать агента, когда он делает правильный выбор. Эти действия также могут изменить состояние среды. Наконец, это новое состояние среды наблюдает агент, который затем решает, какое следующее наилучшее действие следует предпринять. Это резюмируется изображением ниже.
Рисунок 1: Взаимодействие между агентом и средой. Источник: http://rll.berkeley.edu/deeprlcourse-fa15/
Давайте используем этот пример маршрутизации в качестве простой иллюстрации того, как может работать RL. Мы начинаем без данных, но агент будет генерировать несколько вариантов маршрутизации, чтобы добраться из точки А в точку Б методом проб и ошибок. Предполагая, что действия, которые мы можем предпринять, следующие:
- Вверх
- Вниз
- Влево
- Вправо
Награда выдается при достижении точки B. Предположим также, что в этой ситуации агент может сделать только четыре шага, прежде чем игра закончится. Затем агент выполняет ряд действий, которые могут выглядеть следующим образом:
Каким должен быть результат строки 3? Ну, это действительно зависит. Если предположить, что агент находится в лабиринте только с тремя горизонтальными квадратами, а состояние окружающей среды до Действия 1 всегда следующее:
Тогда становится ясно, что важнее всего то, что агенту нужно два раза переместиться вправо, чтобы достичь точки B (Действия агента, движущегося вверх или вниз, становятся несущественными). Действия, предпринятые для ID 3, приводят агента к точке B.
Предположим, что у нас есть альтернативная среда лабиринта как таковая:
Тогда важнее всего то, что агенту нужно спуститься один раз и дважды пройти вправо, чтобы добраться до Точка B. Действия, предпринятые для ID 3, приводят агента к точке B.
В другой альтернативной среде предположим, что теперь у нас есть области в лабиринте, куда агент не может попасть (затемненные области). В этом случае ID 0 и ID 2 перемещают Агента из точки A в точку B, а ID 3 не может. (Вам потребуется, чтобы агент сначала переместился вправо, прежде чем двигаться вниз.)
В задачах RL мы не знаем об окружающей среде. Проблема в RL заключается в том, как мы узнаем, какое следующее наилучшее действие следует предпринять, чтобы максимизировать вознаграждение. Это делается путем генерации данных посредством этого итеративного процесса проб и ошибок, когда агент наблюдает за окружающей средой и предпринимает следующее наилучшее действие.
Существует два основных метода, которые можно изучить из сгенерированных данных, и это методы Q Learning (обучение на основе ценности) и градиенты политики.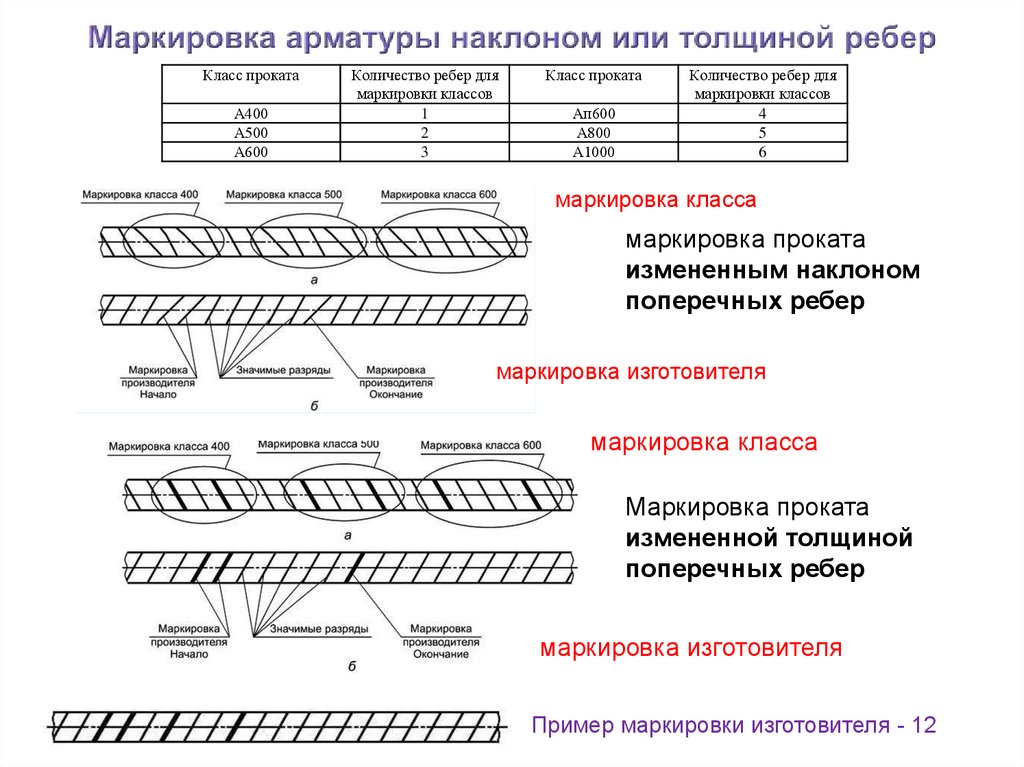 Чтобы объяснить эти два метода, я буду решать вводную игру из тренажерного зала OpenAI, известную как CartPole-v0. Мой подход будет заключаться в том, чтобы попытаться объяснить эти методы с точки зрения программирования, и, надеюсь, оттуда мы получим интуицию для любого метода.
Чтобы объяснить эти два метода, я буду решать вводную игру из тренажерного зала OpenAI, известную как CartPole-v0. Мой подход будет заключаться в том, чтобы попытаться объяснить эти методы с точки зрения программирования, и, надеюсь, оттуда мы получим интуицию для любого метода.
Стойка прикреплена к тележке. Когда начинается игровой эпизод, шест находится в вертикальном положении. Тележка может двигаться как влево, так и вправо. В каждый момент времени тележка должна двигаться либо влево, либо вправо. Перемещение тележки влияет на шест. Цель состоит в том, чтобы удерживать шест под определенным углом более 19 секунд.5 моментов времени более 100 серий подряд. Интуиция такова, что если алгоритм RL способен сбалансировать полюс более чем на 195 моментов времени в 100 эпизодах, это означает, что алгоритм RL понял, как правильно играть в игру.
Рисунок 2: CartPole-v0
Вкратце:
Награда: Агент получает награду +1 каждый раз, когда шест остается в вертикальном положении.
Действия: Тележка может двигаться только влево или вправо.
Наблюдения: Агент наблюдает за окружающей средой с помощью этих четырех значений:
Дополнительную информацию можно найти здесь.
Интуиция для Q Learning следующая: учитывая определенные наблюдения, какова ожидаемая награда за каждое действие, которое может предпринять агент. Следовательно, Q Learning сродни созданию огромной таблицы поиска, где в каждой точке наблюдения таблица сообщает вам ожидаемые награды за выполнение любого из возможных действий. Давайте разберем это на эти пять деталей:
По сути, основной цикл Q-обучения выглядит просто так:
- Выберите следующее наилучшее действие для выполнения
- Выполните действие в среде
- Наблюдайте/дискретизируйте новое состояние в среде
- Обновите Q-таблицы
- Повторяйте до завершения
В RL есть концепция известный как эксплуатация против разведки. Это означает, что на каждом временном шаге агент может либо выполнить действие, которое в настоящее время он считает лучшим ходом (эксплуатация), либо агент может выполнить новый ход (исследование).
Это можно сделать с помощью жадного эпсилон-метода. Жадный эпсилон генерирует случайное число и проверяет, меньше ли оно переменной (эпсилон). Если это так, используется случайное действие (исследование). В противном случае используется лучшее действие для наблюдения (эксплуатация).
И последнее замечание: в самом начале Q-таблицы в основном пусты, поэтому вам нужно, чтобы агент выполнял больше исследовательских действий. Однако вы хотели бы, чтобы агент становился все более и более эксплуатирующим, поскольку Q-таблицы начинают заполняться, увеличивая эпсилон с течением времени.
Как мы видели ранее, наблюдения, возвращаемые из окружающей среды, идут непрерывно. Однако при создании Q-таблиц эти числа проще преобразовать в дискретную форму. Это достигается с помощью следующей функции:
Этот элегантный способ дискретизации приписывается этой статье.
Наконец, мы обновляем Q-таблицы, используя формулу:
Полученное значение представляет собой ожидаемую будущую награду за новое действие. Полученная ценность состоит из двух частей: текущей награды и дисконтированной будущей награды. Это обесцененное будущее вознаграждение является оценкой оптимальной будущей стоимости после совершения действия, умноженной на коэффициент дисконтирования (чтобы учесть, что это будущее вознаграждение).
Полученная ценность состоит из двух частей: текущей награды и дисконтированной будущей награды. Это обесцененное будущее вознаграждение является оценкой оптимальной будущей стоимости после совершения действия, умноженной на коэффициент дисконтирования (чтобы учесть, что это будущее вознаграждение).
Переменная альфа управляет скоростью обновления существующих значений Q-таблицы.
Последний шаг обновляет альфа-скорость обучения. Как и в случае с epsilon, вначале вы можете захотеть, чтобы обновления были более агрессивными. Однако со временем вы, вероятно, захотите сократить количество обновлений, чтобы сделать вашу таблицу более стабильной.
Интуиция для градиентов политики такова: при определенных наблюдениях какая политика является наилучшей для агента. Градиенты политики немного сложнее, но стоит отметить, что недавние достижения в области RL относятся к градиентам политики.
Программно вы можете представить, что существует основной цикл, который определяет, какими должны быть политики.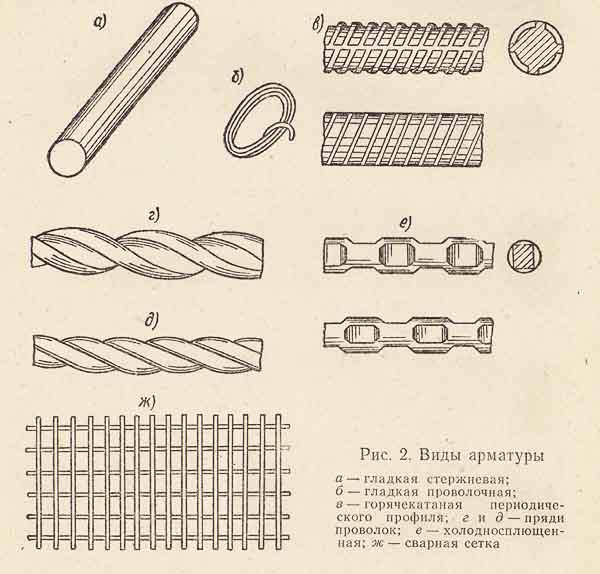 В этом случае мы будем использовать нейронную сеть и основной цикл, чтобы узнать эти политики. Следовательно, мы будем описывать нейронную сеть и три основные детали в этом цикле:
В этом случае мы будем использовать нейронную сеть и основной цикл, чтобы узнать эти политики. Следовательно, мы будем описывать нейронную сеть и три основные детали в этом цикле:
- Нейронная сеть
- Прямой проход (вычисление выходных действий из нейронной сети) нейронная сеть)
- Функция потерь
- Обратный проход (обновление весов нейронной сети)
Мы показываем построенную нами нейронную сеть. Он состоит из двух скрытых слоев по 32 узла.
Detail two передает в нейронную сеть текущее состояние окружающей среды и генерирует вероятности действий. Мы вызываем случайный выбор (на основе вероятностей действий, предоставляемых нейронной сетью), чтобы решить, какое действие мы предпримем.
Во-вторых, мы генерируем список действий из прямых проходов для передачи в среду. Когда мы скармливаем эти действия окружающей среде, мы получаем список вознаграждений благодаря этому списку действий.
Из списка действий мы вычисляем вектор, известный как текущее вознаграждение. Это постоянное вознаграждение рассчитывается с учетом вознаграждений, полученных от этой текущей временной метки до конечной точки. Однако награды, заработанные дальше, будут обесценены.
Это постоянное вознаграждение рассчитывается с учетом вознаграждений, полученных от этой текущей временной метки до конечной точки. Однако награды, заработанные дальше, будут обесценены.
Чтобы описать функцию потерь градиентов политики, мы сначала опишем функцию отрицательного логарифмического правдоподобия контролируемого обучения как
Это похоже на максимизацию вероятностного члена в левой части уравнения. Для градиентов политики формула аналогична, но с добавлением члена A , который известен как преимущество. В RL преимущество заменяется кумулятивным вознаграждением со скидкой.
Следовательно, это дает нам следующую реализацию, где мы берем журнал:
- выход модели (вероятность предпринятого действия) умножается на
- фактическое действие предпринято
Этот логарифмический член далее умножается по льготному вознаграждению.
Наконец, мы используем оптимизатор Adam для обновления весов нейронной сети на основе функции потерь журнала.
Эндрю Нг сказал, что ажиотаж и рекламная шумиха вокруг обучения с подкреплением немного непропорциональны экономической ценности, которую оно создает сегодня (источник). Сказав это, были некоторые конкретные отрасли, которые добились успеха в применении RL. Примеры:
- Финансы (Оформление сделок в JP Morgan Chase)
- Проблемы управления/робототехники (управление светофором, навигация по охлаждению центра обработки данных)
- Спонсируемые поисковые торги в режиме реального времени (Alibaba)
Вы можете сказать, что все эти приложения имеют общую черту RL. А именно способ определения проблемы в качестве агента, наблюдения и выполнения действий в среде с очень четкими результатами вознаграждения (например, охлаждение центра обработки данных вознаграждает экономию затрат; управление светофором снижает вознаграждение за задержки / перегрузки).
Сопутствующую серию коротких видеолекций можно найти на YouTube здесь.
На этом завершается вводная серия из трех частей, посвященная современным классификациям машинного обучения. Надеюсь, вам было так же интересно их читать, как мне их писать!
Надеюсь, вам было так же интересно их читать, как мне их писать!
Автор является доцентом Сингапурского технологического института (SIT). Он имеет степень доктора компьютерных наук Имперского колледжа. Он также имеет степень магистра компьютерных наук NUS по программе Singapore MIT Alliance (SMA).
Мнения, изложенные в этой статье, принадлежат автору и не обязательно отражают официальную политику или позицию каких-либо организаций, с которыми связан автор. Автор также не имеет аффилированных лиц и не получает никаких вознаграждений от каких-либо продуктов, курсов или книг, упомянутых в этой статье.
Суть решения CartPole с Q-Learning можно найти здесь:
Суть решения CartPole с градиентами политик можно найти здесь:
Классификация вне политики — новый метод выбора модели обучения с подкреплением — блог Google AI
Автор: Алекс Ирпан, инженер-программист, робототехника, Google
Обучение с подкреплением (RL) — это структура, которая позволяет агентам учиться принимать решения на основе своего опыта. Один из многих вариантов RL — вне политики RL 9.0004 , где агент обучается с использованием комбинации данных, собранных другими агентами (данные вне политики), и данных, которые он собирает сам, для изучения обобщаемых навыков, таких как роботизированная ходьба и хватание. В отличие от этого, полностью не соответствует политике RL — это вариант, в котором агент изучает полностью из более старых данных, что привлекательно, поскольку позволяет выполнять итерацию модели, не требуя физического робота. С полностью внеполитическим RL можно обучить несколько моделей на одном и том же фиксированном наборе данных, собранном предыдущими агентами, а затем выбрать лучшую. Тем не менее, полностью вне политики RL имеет подвох: в то время как обучение может происходить без реального робота, оценка моделей не может. Кроме того, наземная оценка с помощью физического робота слишком неэффективна для тестирования многообещающих подходов, требующих оценки большого количества моделей, таких как автоматический поиск архитектуры с помощью AutoML.
Один из многих вариантов RL — вне политики RL 9.0004 , где агент обучается с использованием комбинации данных, собранных другими агентами (данные вне политики), и данных, которые он собирает сам, для изучения обобщаемых навыков, таких как роботизированная ходьба и хватание. В отличие от этого, полностью не соответствует политике RL — это вариант, в котором агент изучает полностью из более старых данных, что привлекательно, поскольку позволяет выполнять итерацию модели, не требуя физического робота. С полностью внеполитическим RL можно обучить несколько моделей на одном и том же фиксированном наборе данных, собранном предыдущими агентами, а затем выбрать лучшую. Тем не менее, полностью вне политики RL имеет подвох: в то время как обучение может происходить без реального робота, оценка моделей не может. Кроме того, наземная оценка с помощью физического робота слишком неэффективна для тестирования многообещающих подходов, требующих оценки большого количества моделей, таких как автоматический поиск архитектуры с помощью AutoML.
Эта проблема мотивирует o ff-оценка политики (OPE), методы изучения качества новых агентов с использованием данных от других агентов. С помощью рейтингов OPE мы можем выборочно тестировать только самые многообещающие модели на реальных роботах, значительно расширяя масштабы экспериментов при том же фиксированном бюджете реальных роботов.
| Диаграмма для разработки реальных моделей. Если предположить, что мы можем оценивать 10 моделей в день без оценки вне политики, нам потребуется в 100 раз больше дней для оценки наших моделей. |
Хотя структура OPE выглядит многообещающе, она предполагает наличие нестандартного метода оценки, который точно ранжирует производительность по старым данным. Однако агенты, накопившие прошлый опыт, могут действовать совершенно иначе, чем агенты, получившие новые знания, что затрудняет получение точных оценок производительности.
В разделе «Оценка вне политики с помощью классификации вне политики» мы предлагаем новый метод оценки вне политики, называемый классификацией вне политики (OPC), который оценивает производительность агентов на основе прошлых данных, рассматривая оценку как проблема классификации, в которой действия помечаются либо как потенциально ведущие к успеху, либо как гарантированно приводящие к неудаче. Наш метод работает для входных изображений (камер) и не требует повторного взвешивания данных с выборкой важности или использования точных моделей целевой среды — двух подходов, которые обычно использовались в предыдущей работе. Мы показываем, что OPC масштабируется для решения более крупных задач, включая роботизированную задачу захвата на основе зрения в реальном мире.
Как работает OPC
OPC основан на двух допущениях: 1) окончательная задача имеет детерминированную динамику, т. е. в изменении состояний нет случайности, и 2) что агент либо преуспевает, либо терпит неудачу в конце каждого испытания.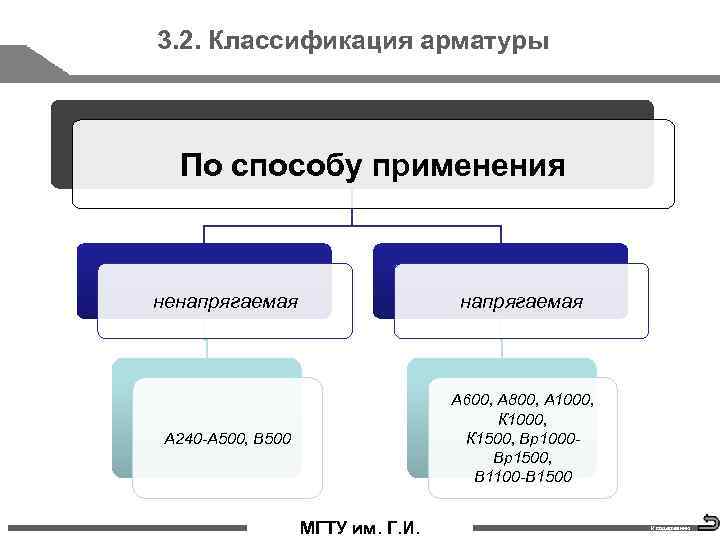 . Это второе предположение об «успехе или неудаче» естественно для многих задач, таких как поднятие предмета, решение лабиринта, победа в игре и так далее. Поскольку каждое испытание будет либо успешным, либо неудачным детерминированным образом, мы можем присвоить каждому действию метки бинарной классификации. Мы говорим, что действие равно эффективное , если оно может привести к успеху, и катастрофическое , если оно гарантированно приведет к неудаче.
. Это второе предположение об «успехе или неудаче» естественно для многих задач, таких как поднятие предмета, решение лабиринта, победа в игре и так далее. Поскольку каждое испытание будет либо успешным, либо неудачным детерминированным образом, мы можем присвоить каждому действию метки бинарной классификации. Мы говорим, что действие равно эффективное , если оно может привести к успеху, и катастрофическое , если оно гарантированно приведет к неудаче.
OPC использует Q-функцию, изученную с помощью алгоритма Q-обучения, которая оценивает будущее общее вознаграждение, если агент решит выполнить какое-либо действие из своего текущего состояния. Затем агент выберет действие с наибольшей общей оценкой вознаграждения. В нашей статье мы доказываем, что производительность агента измеряется тем, насколько часто выбранное им действие является эффективным действием, что зависит от того, насколько хорошо Q-функция правильно классифицирует действия как эффективные по сравнению с катастрофическими. Эта точность классификации действует как оценка оценки вне политики.
Эта точность классификации действует как оценка оценки вне политики.
Однако маркировка данных предыдущих испытаний является лишь частичной. Например, если предыдущее испытание было неудачным, мы не получаем отрицательных меток, потому что не знаем, какое действие было катастрофическим. Чтобы преодолеть это, мы используем методы полуконтролируемого обучения, в частности позитивно-немаркированного обучения, чтобы получить оценку точности классификации на основе частично размеченных данных. Эта точность является оценкой OPC.
Нестандартная оценка обучения Sim-to-Real
В робототехнике принято использовать смоделированные данные и передавать методы обучения, чтобы уменьшить сложность выборки при обучении навыкам робототехники. Это может быть очень полезно, но настройка этих симуляционных методов для реальной робототехники является сложной задачей. Как и в случае внеполитического RL, в обучении не используется настоящий робот, потому что он обучается в симуляции, но для оценки этой политики по-прежнему необходимо использовать настоящего робота. Здесь снова может прийти на помощь оценка вне политики — мы можем взять политику, обученную только в симуляции, затем оценить ее, используя предыдущие данные реального мира, чтобы измерить ее передачу реальному роботу. Мы изучаем OPC как в полностью неполитическом RL, так и в симуляционном RL.
Здесь снова может прийти на помощь оценка вне политики — мы можем взять политику, обученную только в симуляции, затем оценить ее, используя предыдущие данные реального мира, чтобы измерить ее передачу реальному роботу. Мы изучаем OPC как в полностью неполитическом RL, так и в симуляционном RL.
| Пример того, как смоделированный опыт может отличаться от реального. Здесь смоделированные изображения ( слева ) имеют гораздо меньшую визуальную сложность, чем реальные изображения ( справа ). |
Результаты
Во-первых, мы настроили смоделированную версию нашей задачи захвата робота, где мы могли легко обучить и оценить несколько моделей для эталонной оценки вне политики. Эти модели были обучены с полностью вне политики RL, а затем оценены с оценкой вне политики. Мы обнаружили, что в наших задачах по робототехнике вариант OPC, называемый SoftOPC, лучше всего справлялся с прогнозированием конечного процента успеха.
| Эксперимент с имитацией захвата. Красная кривая — безразмерная оценка SoftOPC в ходе обучения, рассчитанная по старым данным. Синяя кривая — это показатель успешности захвата в симуляции. Мы видим, что SoftOPC на старых данных хорошо коррелирует с успехом понимания модели в нашем симуляторе. |
После успеха в симуляции мы попробовали SoftOPC в реальной задаче. Мы взяли 15 моделей, натренированных на разную степень устойчивости к разрыву между симуляцией и реальностью. Из этих моделей 7 были обучены исключительно в моделировании, а остальные были обучены на сочетании смоделированных и реальных данных. Для каждой модели мы оценили SoftOPC на реальных данных вне политики, а затем успешность захвата в реальном мире, чтобы увидеть, насколько хорошо SoftOPC предсказал производительность этой модели. Мы обнаружили, что на реальных данных SoftOPC действительно дает оценки, которые коррелируют с истинным успехом схватывания, что позволяет нам ранжировать симуляционные методы с реальными, используя прошлый реальный опыт.
| Оценка SoftOPC и истинная производительность для 3 различных методов преобразования sim-to-real: базовая симуляция, симуляция со случайными текстурами и освещением и модель, обученная с помощью RCAN. Все три модели обучаются без реальных данных, а затем оцениваются с оценкой вне политики на проверочном наборе реальных данных. Порядок оценки SoftOPC соответствует порядку реального успеха захвата. |
Ниже приведена диаграмма рассеяния полных результатов всех 15 моделей. Каждый балл представляет собой балл оценки вне политики и реальный успех каждой модели. Мы сравниваем различные оценочные функции по их корреляции с успехом окончательного захвата. SoftOPC не полностью коррелирует с истинным успехом схватывания, но его оценки значительно более надежны, чем базовые подходы, такие как ошибка временной разницы (стандартная потеря Q-обучения).
