Классификация арматуры: Арматура — классификация и применение
Содержание
Характеристики и классификация арматуры
Арматура – это металлические и не металлические стержни. Ее возможно классифицировать по материалу изготовления, диаметру, качеству, и пр.
| Арматура |
По материалу изготовления и типу профиля стержни бывают:
- Металлические, производящиеся из стали различных марок.
Металлическая арматура с периодическим профилем
Класс | Диаметр в мм | Марка стали | Тип профиля |
|---|---|---|---|
А1 (А240) | 6-40 | Ст3кп/пс/сп | Гладкий |
А2 (А300) | 10-80 | Ст5сп/пс, 8Г2С | периодический |
А3 (А400) | 6-40 6-22 | 35ГС, 25Г2С, 32Г2Рпс | периодический |
А4 (А600) | 10-18(6-8) 10-32(36-40) | 80C 20ХГ2Ц | периодический |
А5 (А800) | 10-32(6-8) | 23в2Г2Т | периодический |
- Не металлические, композитные.

Композитная арматура
Они имеют периодический профиль. Изготавливаются из cтеклянных, базальтовых, углеродных и арамидных волокон
Дополнительные индексы.
Стержни могут иметь следующие дополнительные индексы в маркировке:
- Индекс С. Означает свариваемый.
- Индекс К. Означает высокую стойкость к корозийному растрескиванию.
Отсутствие индекса С в маркировке арматуры означает, что такие стержни не желательно сваривать, в местах сварки они становятся очень хрупкими.
Метод поставки
Арматуру поставляют в следующих видах:
- В виде готовой сварной сетки для армирования
- В виде прутьев различной длинны. Обычно, от 6 до 12 м. (При сечении больше 10 мм)
- В виде мотка. (При сечении менее 10 мм)
При технологиях изготовления арматуру производят в основном стержневым и проволочным методами.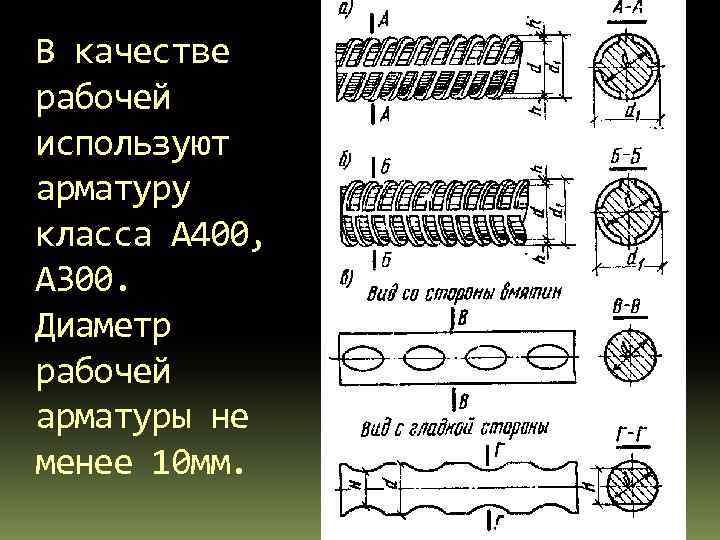
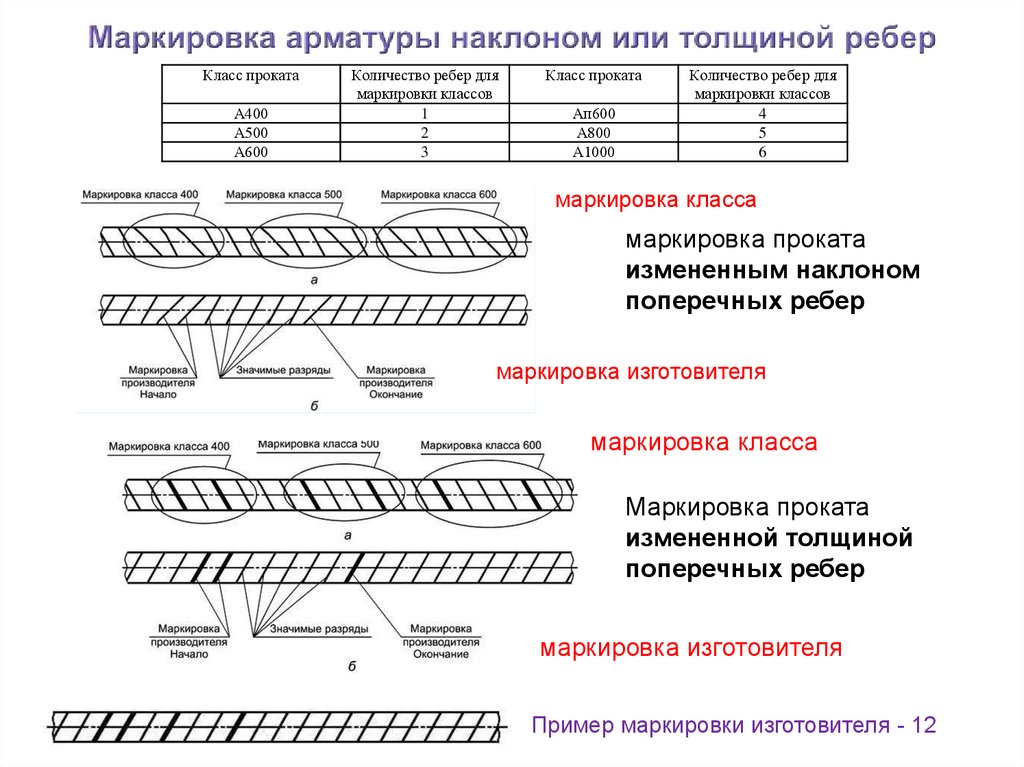
Тип профиля
У металлических стержней могут быть два типа профиля:
- Гладкий. Без каких либо дополнительных насечек.
- Периодический. Имеет ребра для улучшения сцепления с бетоном. Такой профиль разделяют на спиралевидный, кольцевой, смешанный.
Профиль композитной арматуры периодический, но ребра имеют специальную форму и поверхность покрывается песком.
Упрочнение арматуры При изготовлении прутья могут быть не подверженные упрочнению, требуемые свойства обеспечивает сталь, а также подверженные термическому упрочнению (закалке) для увеличения прочности.
Классификация трубопроводной арматуры по функциональному назначению|Производство трубопроводной арматуры в СПб
- Главная
- Общие понятия трубопроводной арматуры
- Классификация трубопроводной арматуры по функциональному назначению
/
/
Функциональное назначение трубопроводной арматуры делит ее на следующие основные классы:
- Запорная ТА
- Регулирующая ТА
- Распределительная ТА
- Предохранительная ТА
- Защитная / отсечная ТА
- Фазоразделительная ТА
Запорная трубопроводная арматура используется для перекрытия потоков жидких сред. Этот тип арматуры должен обеспечивать не только надежное, но и полное перекрытие проходного сечения. Таким образом ТА необходимо обеспечивать всего 2 типа состояния — открыта или закрыта, она не может быть предназначена для условий эксплуатации в промежуточном положении рабочего органа.
Этот тип арматуры должен обеспечивать не только надежное, но и полное перекрытие проходного сечения. Таким образом ТА необходимо обеспечивать всего 2 типа состояния — открыта или закрыта, она не может быть предназначена для условий эксплуатации в промежуточном положении рабочего органа.
Этот тип трубопроводной арматуры имеет самое широкое применение. Этом класс включает пробно-спускную и контрольно-спускную ТА, которые предназначены для кратковременного открытия, имеющего целью проверку рабочей среды на наличие или параметры.
Регулирующая трубопроводная арматура используется для непосредственного регулирования параметров рабочей среды с помощью изменения ее расхода. Этому типу арматуры свойственно не обеспечивать полное перекрытие проходного сечения.
К этой трубопроводной арматуре могут быть предъявлены дополнительные требования, касающиеся вида регулировочной характеристики или надежности/точности регулирования параметров.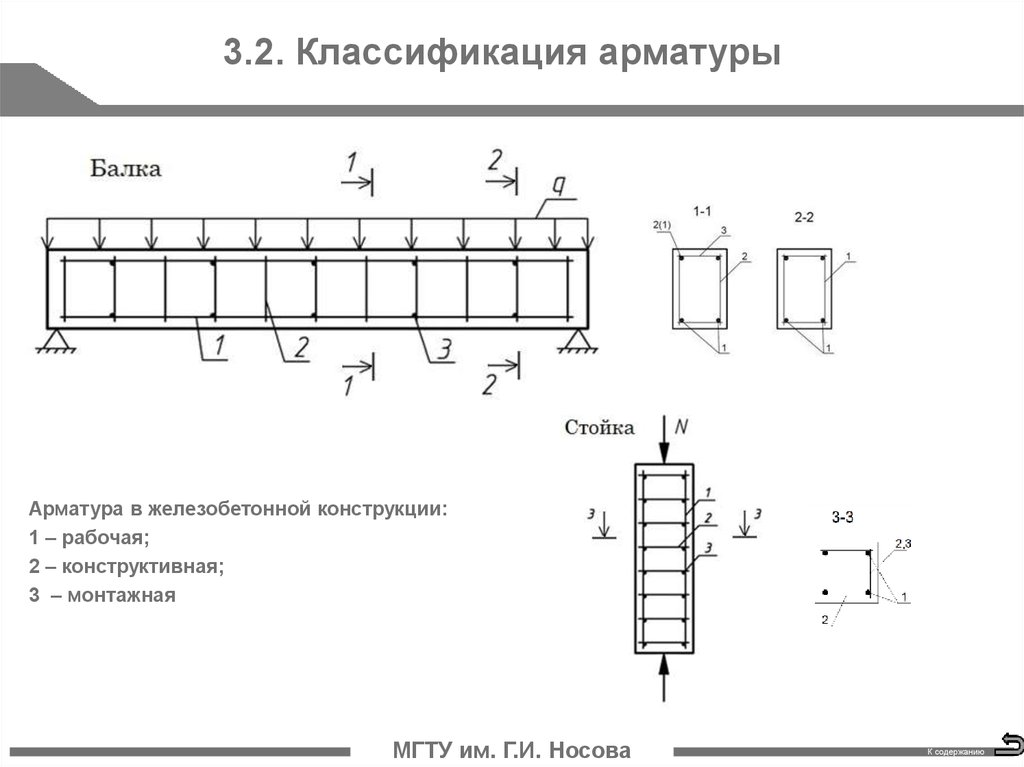 Этот класс включает и дроссельную ТА, которая предназначена для снижения давления потока рабочей среды.
Этот класс включает и дроссельную ТА, которая предназначена для снижения давления потока рабочей среды.
Распределительная трубопроводная арматура используется для распределения потока рабочей среды по 2 или более направлениям. Одним из ярких примеров трубопроводной арматуры этого типа является трех ходовой кран, который часто используется в отоплении с целью регулирования теплоотдачи отопительного прибора за счет пропускания части общего расхода теплоносителя на стояке через замыкающий участок.
Этот класс арматуры нашел свое широкое применение в системах гидро- / пневмоавтоматики с целью управления различными устройствами.
Предохранительная трубопроводная арматура используется для предотвращения аварийного повышения одного из параметров при обслуживании систем методом автоматического выброса избыточного количества рабочей среды. Одним из самых ярких представителей являются предохранительные клапаны, которые устанавливаются на паровом котле. При превышении уровня давления в барабане котла и срабатывает данный предохранительный клапан, в результате чего часть пара стравливается через него в атмосферу, тем самым поддерживается давление в самом котле на уровне максимального из допустимых значений.
Этот класс трубопроводной арматуры включает и мембранно-разрывные устройства (взрывозащитные клапаны и др.), которые представляют из себя мембрану, разрываемую под действием давления в момент взрыва, что и является препятствием критичному повышению давления в системе.
Защитная трубопроводная арматура используется для защиты промышленного оборудования в случаях аварийного изменения параметра рабочей среды, которым относятся давление, температура и направление потока, при помощи отключения обслуживаемого участка. Ее отличие от предохранительной трубопроводной арматуры заключается в том, что поток не стравливается в атмосферу, а отключается критичный элемент системы.
Ярким примером этого класса являются обратные клапаны, которые предотвращают самопроизвольное изменение направления потока рабочей среды в трубопроводной системе. В устройствах топки данный тип ТА отключает подачу топлива к горелочному устройству при погасании факела / при отключении электрического снабжения / остановке дымососа или дутьевого вентилятора.
Фазоразделительная трубопроводная арматура используется для автоматического разделения разного рода фаз рабочей среды, к которой также относятся вода и пар – это конденсатоотводчики, вода и воздух – это воздухоотводчики и вантузы, вода и масло – это маслоотделители.
Основные виды ТА не включают промежуточные, из которых можно выделить: запорно-регулирующую, смесительную, пробно-спускную и другие.
Смотреть разделТрубопроводная арматураОбратитьсяв Службу поддержки
Можно ли использовать обучение с подкреплением для классификации?
8 минут чтения
После изучения обучения с подкреплением кто не задается вопросом, будет ли оно полезно для задач, которые обычно зарезервированы
для контролируемого обучения.
В конце концов, это естественный вопрос.
Итак, я решил выяснить это наилучшим из известных мне способов: написав кучу кода.
Загрузите блокнот Jupyter.
Загрузка экспериментальных данных
В попытке ответить на вопрос, не поглощая свой единственный графический процессор за несколько недель обучения, я выбрал набор данных MNIST.
в качестве экспериментальной базы.
MNIST — это достаточно простая задача, которую можно решить всего за несколько секунд, но в то же время достаточно сложная задача, чтобы ответить на
вопрос о том, можно ли использовать обучение с подкреплением для обучения классификатора.
Если вы не знакомы с этим, MNIST представляет собой набор изображений рукописных цифр (0-9) в черно-белом режиме.
Задача классификации состоит в том, чтобы определить, какую цифру представляет каждое изображение.
Изображения выглядят так:
Итак, давайте закодируем этого плохого мальчика.
Настройка
Наши единственные зависимости — это tensorflow и OpenAI Baselines. Давайте возьмем те
установка пакетов в сторону:
pip установить тензорный поток-gpu-1.15.5 pip install git+https://github.com/openai/[электронная почта защищена]
Затем весь импорт сразу:
время импорта импортный тренажерный зал импортировать случайный импортировать numpy как np из тензорного потока импортировать керас из слоев импорта tensorflow.keras из baselines.ppo2 импортировать ppo2 из baselines.common.vec_env.dummy_vec_env импортировать DummyVecEnv импортировать из исходных данных deepq скамья импорта базовых показателей регистратор импорта из базовых показателей импортировать тензорный поток как tf из baselines.common.tf_util импортировать make_session
Теперь мы готовы погрузиться в код.
Получение данных
# Модель/параметры данных
число_классов = 10
input_shape = (28, 28, 1)
# данные, разделенные между обучающими и тестовыми наборами
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Масштабировать изображения в диапазоне [0, 1]
x_train = x_train.astype("float32") / 255
x_test = x_test.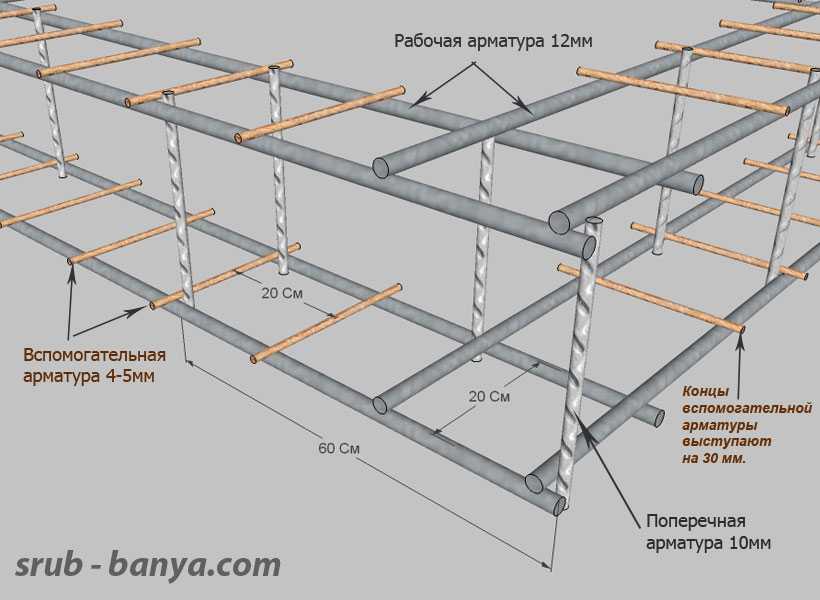 astype("float32") / 255
# Убедитесь, что изображения имеют форму (28, 28, 1)
x_train = np.expand_dims (x_train, -1)
x_test = np.expand_dims (x_test, -1)
print("Форма x_train:", x_train.shape)
print(x_train.shape[0], "образцы поездов")
print(x_test.shape[0], "тестовые образцы")
# преобразовать векторы классов в бинарные матрицы классов
y_train_one_hot = keras.utils.to_categorical (y_train, num_classes)
y_test_one_hot = keras.utils.to_categorical (y_test, num_classes)
astype("float32") / 255
# Убедитесь, что изображения имеют форму (28, 28, 1)
x_train = np.expand_dims (x_train, -1)
x_test = np.expand_dims (x_test, -1)
print("Форма x_train:", x_train.shape)
print(x_train.shape[0], "образцы поездов")
print(x_test.shape[0], "тестовые образцы")
# преобразовать векторы классов в бинарные матрицы классов
y_train_one_hot = keras.utils.to_categorical (y_train, num_classes)
y_test_one_hot = keras.utils.to_categorical (y_test, num_classes)
С помощью этого кода мы используем встроенные утилиты keras для загрузки набора данных mnist и загрузки его в память.
Он скопирован прямо со страницы примера keras.
Если вы смотрели какое-либо из моих видео, вы, вероятно, знаете, что я предпочитаю PyTorch, но, учитывая, что я решил
использовать базовые уровни для алгоритмов RL, keras создан как более простая альтернатива базовому уровню контролируемого обучения.
Базовый уровень Кераса
Даже если RL сработает, мы не узнаем, хороша ли она, если нам не с чем ее сравнить.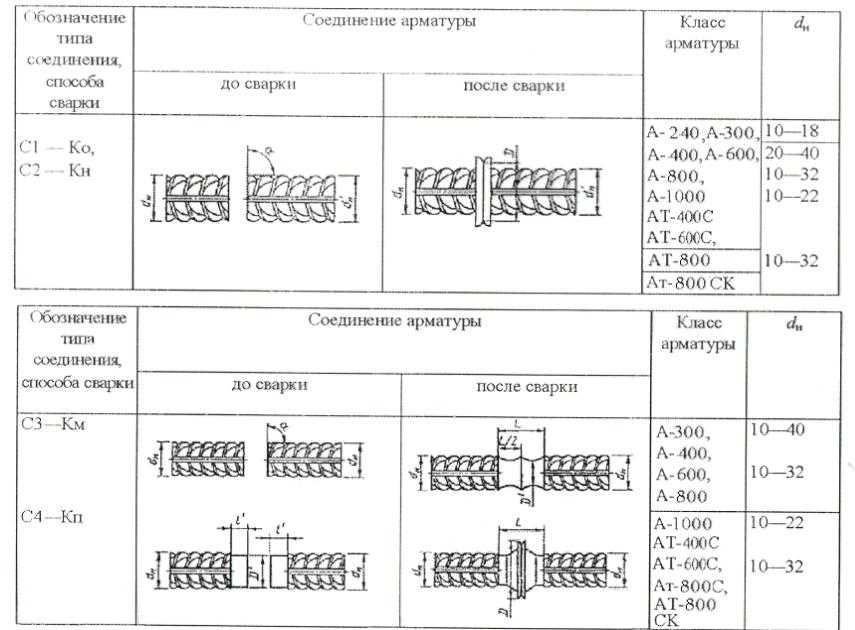
Давайте исправим это, обучив классификатор на наборе данных MNIST с помощью традиционного контролируемого обучения с использованием Keras.
по определению keras_train (batch_size = 32, эпохи = 2):
модель = keras.Sequential(
[
keras.Input(форма=input_shape),
слои.Свести(),
слои.Dense(64, активация='relu'),
слои.Dense(64, активация='relu'),
слои.Dense (количество_классов, активация = "softmax")
]
)
модель.резюме()
model.compile(loss="categorical_crossentropy", оптимизатор="adam", metrics=["точность"])
start_time = время.время()
model.fit(x_train, y_train_one_hot, batch_size=batch_size, epochs=epochs, validation_split=0,1)
end_time = время.время()
оценка = model.evaluate (x_test, y_test_one_hot, подробный = 0)
print("Потеря теста:", оценка[0])
print("Точность теста:", оценка[1])
print("Время обучения:", end_time - start_time)
keras_train()
Обратите внимание, что он использует MLP с двумя скрытыми слоями по 64 модуля. Это довольно классический размер сети для RL, и я хочу, чтобы все попытки имели примерно одинаковое количество параметров.
Это довольно классический размер сети для RL, и я хочу, чтобы все попытки имели примерно одинаковое количество параметров.
Кроме того, он имеет размер пакета 32, так как это типичный размер пакета, используемый в DQN.
Когда я запускаю его, я получаю такой вывод:
Потеря теста: 0,11103802259191871 Точность теста: 0,9658 Время обучения: 14.185736656188965
Это 96% точности всего за 14 секунд обучения. Очень впечатляет!
RL Тренировочная среда (gym.Env)
С тех пор, как OpenAI выпустила свою библиотеку тренажерного зала, она стала стандартом де-факто для RL.
среды обучения алгоритмам.
Давайте создадим такой, который адаптирует парадигму вознаграждения среды RL к проблеме классификации.
Идея проста: каждый класс изображения — это уникальное действие, которое может выполнить агент. Если он предпримет действие, которое
соответствует правильному классу, даем +1 награду. В противном случае мы даем 0 наград.
Кроме того, ошибка временной разницы делает предположение, что действия на одном этапе влияют на вознаграждение на следующих шагах.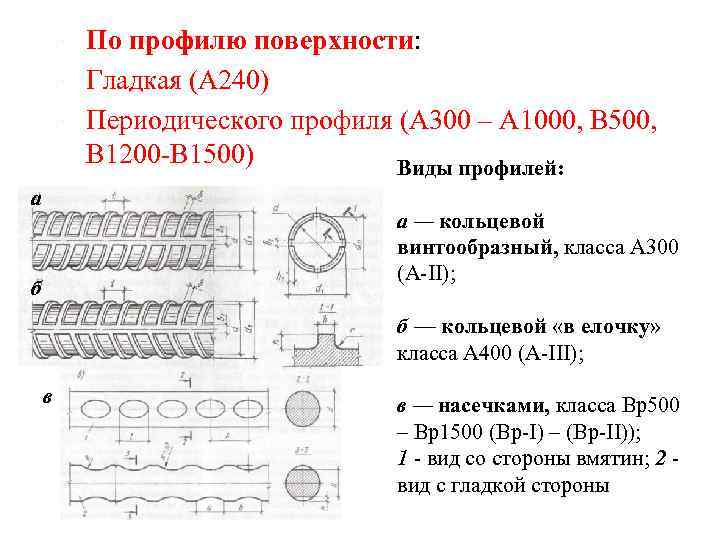 Который
Который
в нашей среде это не так. Таким образом, эпизоды, которые длятся дольше одного временного шага, не имеют никакого смысла в этом контексте.
класс MnistEnv (спортзал.Env):
def __init__(self, images_per_episode=1, набор данных=(x_train, y_train), random=True):
супер().__инит__()
self.action_space = спортзал.spaces.Discrete(10)
self.observation_space = gym.spaces.Box (низкий = 0, высокий = 1,
форма=(28, 28, 1),
dtype=np.float32)
self.images_per_episode = images_per_episode
self.step_count = 0
self.x, self.y = набор данных
self.random = случайный
self.dataset_idx = 0
шаг защиты (я, действие):
сделано = ложь
награда = int (действие == self.expected_action)
obs = self._next_obs()
self.step_count += 1
если self.step_count >= self.images_per_episode:
сделано = верно
вернуть наблюдения, награда, сделано, {}
сброс защиты (сам):
self. step_count = 0
obs = self._next_obs()
возврат наблюдений
защита _next_obs(я):
если self.random:
next_obs_idx = random.randint(0, len(self.x) - 1)
self.expected_action = int(self.y[next_obs_idx])
obs = self.x[next_obs_idx]
еще:
obs = self.x[self.dataset_idx]
self.expected_action = int(self.y[self.dataset_idx])
self.dataset_idx += 1
если self.dataset_idx >= len(self.x):
поднять StopIteration()
возврат наблюдений
step_count = 0
obs = self._next_obs()
возврат наблюдений
защита _next_obs(я):
если self.random:
next_obs_idx = random.randint(0, len(self.x) - 1)
self.expected_action = int(self.y[next_obs_idx])
obs = self.x[next_obs_idx]
еще:
obs = self.x[self.dataset_idx]
self.expected_action = int(self.y[self.dataset_idx])
self.dataset_idx += 1
если self.dataset_idx >= len(self.x):
поднять StopIteration()
возврат наблюдений
Полученный код для тренажерного зала Env довольно прост.
Единственное, что следует отметить, это то, что мы можем поменять местами набор данных и случайных параметров на функцию __init__ для
превратить тренажерный зал в оценочную скамью на тестовом наборе.
Момент истины
Теперь узнаем раз и навсегда. Можно ли использовать RL для классификации?
Сначала мы будем тренироваться с дуэльной глубокой Q-сетью.
определение mnist_dqn():
logger.configure(dir='./logs/mnist_dqn', format_strs=['stdout', 'tensorboard'])
env = MnistEnv (images_per_episode = 1)
env = скамейка.Monitor (env, logger.get_dir())
модель = deepq.learn(
окружение,
"млп",
количество_слоев=1,
номер_скрытый = 64,
активация=tf.nn.relu,
скрытые=[32],
дуэль = правда,
лр=1е-4,
total_timesteps=int(1.2e5),
размер_буфера=10000,
исследовательская_фракция = 0,1,
explore_final_eps=0,01,
поезд_частота = 4,
Learning_starts=10000,
target_network_update_freq=1000,
)
model.save('dqn_mnist.pkl')
env.close()
модель возврата
start_time = время.время()
dqn_model = mnist_dqn()
print("Время обучения DQN:", time.time() - start_time)
Это довольно стандартные вещи, ничего необычного не происходит. Мы используем реализацию DQN из
Базовые показатели OpenAI.
Размер пакета равен 32, как и в модели keras, а общее количество временных шагов равно 120 000, что в два раза превышает количество выборок.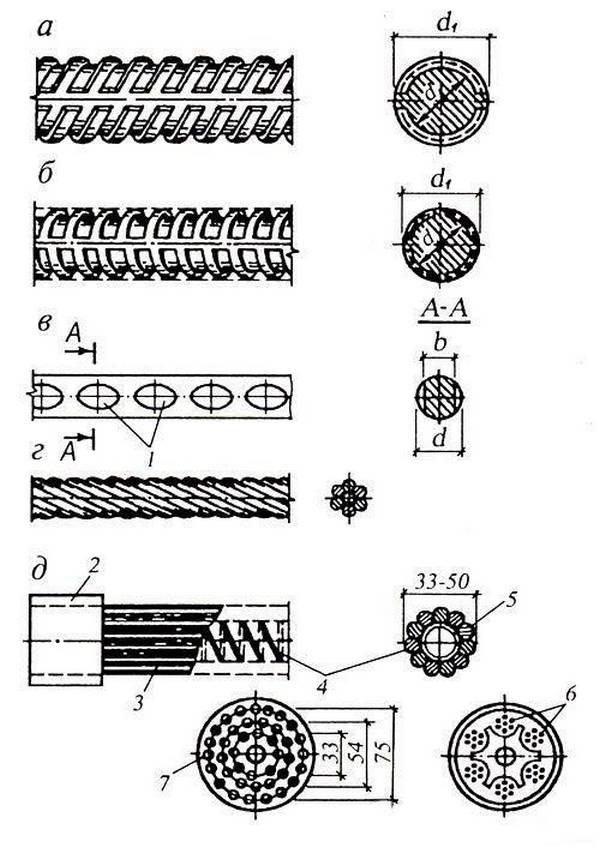
в тренировочном наборе. Это имитирует 2 эпохи, как мы используем в модели keras.
По сравнению с контролируемым базовым планом существует архитектурная разница. Дуэльная часть алгоритма ломается
вместо этого последний слой на два отдельных слоя по 32 единицы. Эти две головки сходятся по отдельности в один выход, и
вывод для каждого действия.
В конечном счете, это означает, что параметров станет на несколько меньше, но мы все еще на том же уровне.
Окончательный вывод после обучения выглядит так:
-------------------------------------- | % времени, потраченного на изучение | 1 | | эпизоды | 1.2e+05 | | средняя награда за 100 эпизодов | 1 | | шаги | 1.2e+05 | -------------------------------------- Время обучения DQN: 461,527117729187
потребовалось намного больше времени (более чем в 30 раз), чем контролируемый базовый уровень, но похоже, что точность была достигнута на 100%.
на тренировочном комплексе!
Давайте запустим оценку и посмотрим, как она выдержит испытание на тестовом наборе.
определение mnist_dqn_eval (dqn_model):
попытки, верно = 0,0
env = MnistEnv (images_per_episode = 1, набор данных = (x_test, y_test), random = False)
пытаться:
пока верно:
obs, выполнено = env.reset(), False
пока не сделано:
obs, rew, done, _ = env.step(dqn_model(obs[None])[0])
попытки += 1
если рев > 0:
правильно += 1
кроме StopIteration:
Распечатать()
print('проверка завершена...')
print('Точность: {0}%'.format((число с плавающей запятой (верно) / количество попыток) * 100))
mnist_dqn_eval (dqn_model)
Аааааанннндддд… результаты:
Точность: 93,47869573914784%
Точность 93,4%!
Ну, я думаю, это ответ, обучение с подкреплением определенно можно использовать в качестве классификатора.
То есть до тех пор, пока вы готовы ждать в 30 раз больше времени, чтобы обучить его с помощью RL.
Можем ли мы сделать лучше? Может это просто алгоритм. DQN, в конце концов, не король алгоритмов RL.
Тестирование с королем
Чтобы выяснить, можем ли мы добиться большего успеха, мы собираемся провести еще один эксперимент с королем алгоритмов RL.
… барабанная дробь …
Оптимизация проксимальной политики (PPO), представленная
Джон Шульман в 2017 году уже некоторое время занимает место короля алгоритмов.
Это алгоритм, который достаточно гибок, чтобы применяться ко многим типам задач, и достаточно надежен, чтобы не требовать многого.
настройка гиперпараметров.
На самом деле он оказался настолько хорош, что всех удивило, когда OpenAI использовал его для обучения ботов DOTA 2, которые нас раздавили
простые смертные в профессиональной игре.
Итак, давайте посмотрим, как он работает в качестве скромного классификатора.
определение mnist_ppo():
logger.configure(dir='./logs/mnist_ppo', format_strs=['stdout', 'tensorboard'])
env = DummyVecEnv([лямбда: скамейка. Monitor(MnistEnv(images_per_episode=1), logger.get_dir())])
модель = ppo2.learn(
окружение = окружение,
сеть = 'млп',
число_слоев = 2,
номер_скрытый = 64,
nшагов=32,
total_timesteps=int(1.2e5),
семя = целое (время. время ()))
модель возврата
start_time = время.время()
ppo_model = mnist_ppo()
print("Время обучения PPO:", time.time() - start_time)
Monitor(MnistEnv(images_per_episode=1), logger.get_dir())])
модель = ppo2.learn(
окружение = окружение,
сеть = 'млп',
число_слоев = 2,
номер_скрытый = 64,
nшагов=32,
total_timesteps=int(1.2e5),
семя = целое (время. время ()))
модель возврата
start_time = время.время()
ppo_model = mnist_ppo()
print("Время обучения PPO:", time.time() - start_time)
То же самое, что и с DQN, это стандартная установка с использованием базовой реализации PPO в нашей среде.
Архитектурно модель PPO добавляет стоимостную главу с одним выходом после последнего уровня MLP. В конце концов, это означает
еще несколько параметров по сравнению с контролируемым базовым уровнем.
После обучения вывод выглядит следующим образом:
-------------------------------------- | среднее значение | 1 | | средний | 0,95 | | кадров в секунду | 177 | | потеря/оккл | 0,131 | | потеря/усечение | 0,0625 | | потеря/policy_entropy | 0,0253 | | потеря/policy_loss | -0,0292 | | убыток/значение_убыток | 0,0271 | | разное/explained_variance | 0,115 | | разное/обновления | 3.75e+03 | | разное/serial_timesteps | 1.2e+05 | | разное/time_elapsed | 638 | | разное/общее_время | 1.2e+05 | -------------------------------------- Время обучения PPO: 638.657053232193
ВОУ! Более 10 минут тренировочного времени, и это даже не на 100% на тренировочном наборе.
Выглядит не очень хорошо, но давайте посмотрим, как это работает на тренировочном наборе.
определение mnist_ppo_eval (ppo_model):
попытки, верно = 0,0
env = DummyVecEnv([лямбда: MnistEnv(images_per_episode=1, набор данных=(x_test, y_test), random=False)])
пытаться:
пока верно:
obs, выполнено = env.reset(), [False]
пока не сделано[0]:
obs, rew, done, _ = env.step(ppo_model.step(obs[None])[0])
попытки += 1
если рев[0] > 0:
правильно += 1
кроме StopIteration:
Распечатать()
print('проверка завершена...')
print('Точность: {0}%'.format((число с плавающей запятой (верно) / количество попыток) * 100))
mnist_ppo_eval(ppo_model)
Функция eval почти копирует/вставляет функцию eval DQN, но учитывает пакетную среду.
Вывод:
Точность: 95,1995199519952%
Точность 95%! Похоже, что PPO имеет преимущество перед DQN, хотя обучение занимает на 150% больше времени.
Тем не менее, мы примерно в 40 раз тратим больше времени на обучение с помощью обучения с учителем, и все еще не с более высокой точностью.
Важно то, что мы ответили на наш вопрос!
Reinforcement Learning
CAN можно использовать для обучения классификатора.
НО только маньяк будет ждать в 40 раз дольше!
Если вам понравилась эта статья, посетите мой канал на YouTube.
где я обсуждаю различные темы ИИ с упором на RL.
Категории:
ай,
обучение с подкреплением
Обновлено:
Глубокое обучение с подкреплением для несбалансированной классификации
 «>
«>Япкович Н., Стивен С. (2002) Проблема дисбаланса классов: систематическое исследование. Intel Data Anal 6 (5):429–449
Статья
Google ученый
Weiss GM (2004) Горное дело с редкостью: объединяющая структура. Информационный бюллетень ACM Sigkdd Explorations 6(1):7–19
Статья
Google ученый
He H, Garcia EA (2008) Изучение несбалансированных данных. IEEE Trans Know Data Eng 9:1263–1284
Google ученый
Haixiang G, Yijing L, Shang J, Mingyun G, Yuanyue H, Bing G (2017) Обучение на несбалансированных по классам данных: обзор методов и приложений. Expert Syst Appl 73:220–239
Статья
Google ученый
Мних В., Кавуккуоглу К., Сильвер Д., Грейвс А., Антоноглу И.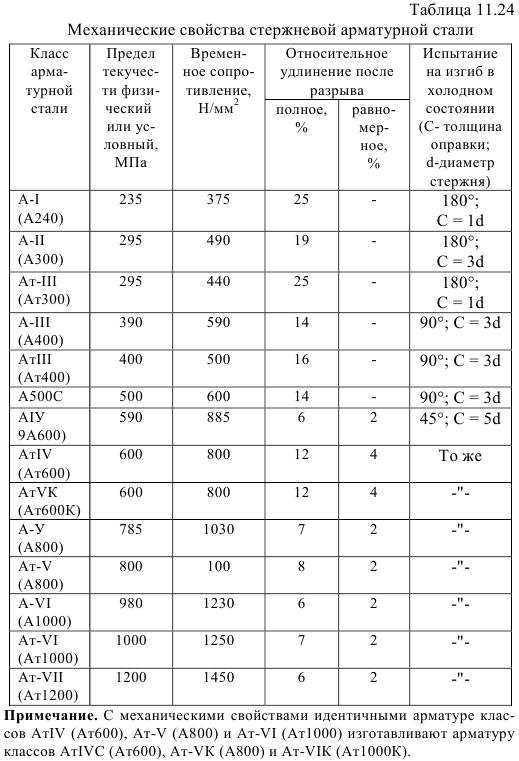 , Вирстра Д., Ридмиллер М. (2013) Игра в atari с глубоким обучением с подкреплением. архив: 1312.5602
, Вирстра Д., Ридмиллер М. (2013) Игра в atari с глубоким обучением с подкреплением. архив: 1312.5602
Gu S, Holly E, Lillicrap T, Levine S (2017) Глубокое обучение с подкреплением для роботизированных манипуляций с асинхронными обновлениями вне политики. В: Международная конференция IEEE по робототехнике и автоматизации (ICRA), 2017 г., IEEE, стр. 3389–3396
Чжао С., Чжан Л., Дин З., Инь Д., Чжао И., Тан Дж. (2017) Глубокое обучение с подкреплением для списка- мудрые рекомендации. архив: 1801.00209
Feng J, Huang M, Zhao L, Yang Y, Zhu X (2018) Обучение с подкреплением для классификации отношений на основе зашумленных данных. В: Труды AAAI
Мартинес С., Перрин Г., Рамассо Э., Ромбо М. (2018) Подход к глубокому обучению с подкреплением для ранней классификации временных рядов. В: EUSIPCO, 2018
Drummond C, Holte RC, et al. (2003) С4. 5, дисбаланс классов и чувствительность к затратам: почему недостаточная выборка побеждает избыточную выборку. В: Семинар по обучению на несбалансированных наборах данных II, том 11, Citeseer, стр. 1–8
(2003) С4. 5, дисбаланс классов и чувствительность к затратам: почему недостаточная выборка побеждает избыточную выборку. В: Семинар по обучению на несбалансированных наборах данных II, том 11, Citeseer, стр. 1–8
Хан Х., Ван В.И., Мао Б.Х. (2005) Пограничный удар: новый метод избыточной выборки в обучении несбалансированных наборов данных. В: Международная конференция по интеллектуальным вычислениям, Springer, стр. 878–887 9.0004
Mani I (2003) I Zhang, knn Подход к несбалансированному распределению данных: тематическое исследование, связанное с извлечением информации. В: Материалы семинара по обучению на несбалансированных наборах данных, том 126
Batista GE, Prati RC, Monard MC (2004) Исследование поведения нескольких методов балансировки обучающих данных машинного обучения. Информационный бюллетень ACM SIGKDD Explorations 6(1):20–29
Статья
Google ученый
 «>
«>Аккаси А., Вароглу Э., Димилилер Н. (2017) Сбалансированная недостаточная выборка: новый метод недостаточной выборки на основе предложений для улучшения распознавания именованных сущностей в химическом и биомедицинском тексте. Appl Intell, стр. 1–14
Гупта Д., Ричхария Б. (2018) Метод двойных опорных векторов на основе нечетких наименьших квадратов на основе энтропии для изучения дисбаланса классов. Приложение Intell 48(11):4212–4231
Статья
Google ученый
Wu G, Chang EY (2005) Kba: Выравнивание границ ядра с учетом несбалансированного распределения данных. IEEE Trans Knowl Data Eng 17(6):786–795
Статья
Google ученый
Тан Ю., Чжан Ю.-К., Чавла Н.В., Крассер С. (2009) Моделирование Svms для сильно несбалансированной классификации. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) 39(1):281–288
Статья
Google ученый
Su C, Cao J (2018) Улучшение ленивого дерева решений для несбалансированной классификации с использованием нечувствительных к перекосу критериев. Applied Intelligence
Zadrozny B, Elkan C (2001) Изучение и принятие решений, когда затраты и вероятности неизвестны. В: Труды седьмой Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных, ACM, стр. 204–213
Задрозный Б., Лэнгфорд Дж., Эйб Н. (2003) Чувствительное к затратам обучение с помощью пропорционального взвешивания примеров. В: ICDM, 2003 г., Третья международная конференция IEEE по интеллектуальному анализу данных, 2003 г., IEEE, стр. 435–442
Zhou Z-H, Liu X-Y (2006) Обучение нейронных сетей, чувствительных к затратам, с помощью методов, решающих проблему дисбаланса классов. IEEE Trans Knowl Data Eng 18(1):63–77
Статья
MathSciNet
Google ученый
Кравчик Б., Возняк М. (2015) Чувствительная к стоимости нейронная сеть с порогом перемещения на основе roc для несбалансированной классификации. В: Международная конференция по интеллектуальной инженерии данных и автоматизированному обучению, Springer, стр. 45–52 9.0004
Чен Дж., Цай С.А., Мун Х., Ан Х., Янг Дж., Чен С.Х. (2006) Корректировка порога принятия решения в прогнозировании класса. SAR QSAR Environ Res 17(3):337–352
Статья
Google ученый
Yu H, Sun C, Yang X, Yang W, Shen J, Qi Y (2016) Odoc-elm: Оптимальное решение выводит машину экстремального обучения на основе компенсации для классификации несбалансированных данных. Основанная на знаниях система 92:55–70
Статья
Google ученый
Тинг К.М. (2000) Сравнительное исследование экономичных алгоритмов повышения. В: Материалы 17-й Международной конференции по машинному обучению Citeseer
Яниш Дж., Певно Т., Лисо В. (2017) Классификация с дорогостоящими функциями с использованием глубокого обучения с подкреплением. архив: 1711.07364
Wang S, Liu W, Wu J, Cao L, Meng Q, Kennedy PJ (2016) Обучение глубоких нейронных сетей на несбалансированных наборах данных в Neural Networks (IJCNN). В: 2016 Международная совместная конференция по. IEEE, стр. 4368–4374
Huang C, Li Y, Change Loy C, Tang X (2016) Обучение глубокому представлению для несбалансированной классификации. В: Материалы конференции IEEE по компьютерному зрению и распознаванию образов, стр. 5375–5384
Yan Y, Chen M, Shyu ML, Chen SC (2015)Глубокое обучение для несбалансированной классификации мультимедийных данных. В: Мультимедиа (ISM). В: 2015 Международный симпозиум IEEE по. IEEE, стр. 483–488
Хан С.Х., Хаят М., Беннамун М., Сохел Ф.А., Тогнери Р. (2018) Чувствительное к стоимости изучение глубоких представлений признаков на основе несбалансированных данных. IEEE Trans Neural Network Learning Syst 29(8):3573–3587
IEEE Trans Neural Network Learning Syst 29(8):3573–3587
Артикул
Google ученый
Донг К., Гонг С., Чжу С. (2018) Несбалансированное глубокое обучение путем постепенного исправления класса меньшинств. IEEE Transactions on Pattern Analysis and Machine Intelligence
Wiering MA, van Hasselt H, Pietersma AD, Schomaker L (2011) Алгоритмы обучения с подкреплением для решения задач классификации. В: Симпозиум IEEE по адаптивному динамическому программированию и обучению с подкреплением (ADPRL), 2011 г., IEEE, стр. 9.1–96
Чжан Т., Хуанг М., Чжао Л. (2018) Обучение структурированному представлению для классификации текста с помощью обучения с подкреплением. AAAI
Лю Д., Цзян Т. (2018) Глубокое обучение с подкреплением для сегментации и классификации хирургических жестов. архив: 1806.08089
Zhao D, Chen Y, Lv L (2017) Глубокое обучение с подкреплением и визуальным вниманием для классификации транспортных средств. IEEE Trans Cogn Develop Syst 9(4):356–367
Статья
Google ученый
Абди Л., Хашеми С. (2014) Подход к сокращению ансамбля, основанный на обучении с подкреплением в присутствии несбалансированных данных нескольких классов. В: Материалы Третьей международной конференции по программным вычислениям для решения задач, Springer, стр. 589–600
Dixit AK, Sherrerd JJ, et al. (1990) Оптимизация в экономической теории. Издательство Оксфордского университета по запросу
Лин Т.Ю., Гоял П., Гиршик Р., Хе К., Доллар П. (2017) Потеря фокуса при обнаружении плотных объектов. В: Материалы Международной конференции IEEE по компьютерному зрению, стр. 29.80–2988
Gu Q, Zhu L, Cai Z (2009) Меры оценки эффективности классификации несбалансированных наборов данных. В: Международный симпозиум по интеллектуальным вычислениям и приложениям, Springer, стр. 461–471
Bengio Y (2012) Практические рекомендации по градиентному обучению глубоких архитектур. В: Neural Networks: Tricks of the Trade, Springer, стр. 437–478
Demšar J (2006) Статистическое сравнение классификаторов по нескольким наборам данных. J Mach Learn Res 7 (январь): 1–30
MathSciNet
МАТЕМАТИКА
Google ученый
Бенаволи А., Корани Г., Мангили Ф. (2016) Должны ли мы действительно использовать апостериорные тесты, основанные на средних рангах? J Mach Learn Res 17(1):152–161
MathSciNet
МАТЕМАТИКА
Google ученый
Wilcoxon F (1992) Индивидуальные сравнения методами ранжирования. В: Прорывы в статистике, Springer, стр. 196–202
