Классификация арматуры: Классы арматуры и марки стали
Содержание
Характеристики и классификация арматуры
Арматура – это металлические и не металлические стержни. Ее возможно классифицировать по материалу изготовления, диаметру, качеству, и пр.
| Арматура |
По материалу изготовления и типу профиля стержни бывают:
- Металлические, производящиеся из стали различных марок.
Металлическая арматура с периодическим профилем
Класс | Диаметр в мм | Марка стали | Тип профиля |
|---|---|---|---|
А1 (А240) | 6-40 | Ст3кп/пс/сп | Гладкий |
А2 (А300) | 10-80 | Ст5сп/пс, 8Г2С | периодический |
А3 (А400) | 6-40 6-22 | 35ГС, 25Г2С, 32Г2Рпс | периодический |
А4 (А600) | 10-18(6-8) 10-32(36-40) | 80C 20ХГ2Ц | периодический |
А5 (А800) | 10-32(6-8) | 23в2Г2Т | периодический |
- Не металлические, композитные.


Композитная арматура
Они имеют периодический профиль. Изготавливаются из cтеклянных, базальтовых, углеродных и арамидных волокон
Дополнительные индексы.
Стержни могут иметь следующие дополнительные индексы в маркировке:
- Индекс С. Означает свариваемый.
- Индекс К. Означает высокую стойкость к корозийному растрескиванию.
Отсутствие индекса С в маркировке арматуры означает, что такие стержни не желательно сваривать, в местах сварки они становятся очень хрупкими.
Метод поставки
Арматуру поставляют в следующих видах:
- В виде готовой сварной сетки для армирования
- В виде прутьев различной длинны. Обычно, от 6 до 12 м. (При сечении больше 10 мм)
- В виде мотка. (При сечении менее 10 мм)
При технологиях изготовления арматуру производят в основном стержневым и проволочным методами.
Тип профиля
У металлических стержней могут быть два типа профиля:
- Гладкий.
 Без каких либо дополнительных насечек.
Без каких либо дополнительных насечек. - Периодический. Имеет ребра для улучшения сцепления с бетоном. Такой профиль разделяют на спиралевидный, кольцевой, смешанный.
Профиль композитной арматуры периодический, но ребра имеют специальную форму и поверхность покрывается песком.
Упрочнение арматуры При изготовлении прутья могут быть не подверженные упрочнению, требуемые свойства обеспечивает сталь, а также подверженные термическому упрочнению (закалке) для увеличения прочности.
Классификация арматуры в зависимости от характеристик – ТПК Нано-СК
Без рубрики
Железобетонные изделия по своему названию характеризуют наличие в них стержней из металла. Однако, в современном строительном бизнесе инновационные технология вытесняют классические материалы для армирования. Альтернатива стали и железу — композитные материалы.
В армировании фундаментов используют базальтовая, углеродистая и стеклопластиковая арматуру. Также неметаллические стержни подходят ля усиления стен, строительства дорожного полотна, садового хозяйства и укрепления земельных емкостей промышленного назначения.
Стеклопластиковая арматура в конструкциях из бетона применяется не первый год, однако в отечественном крупном строительном бизнесе занимает слабые позиции. Постоянные сплетни и споры о слабых характеристиках композитного прута, сужают круг его применения. Те, кто не принимает новую технологию производства неметаллических изделий, уверены в недоработанной нормативной базе композитной арматуры. Но компания ТПК «НАНО-СК» уверяет Вас в том, что все необходимые стандарты уже приняты:
- ГОСТ 31938-2012. Определяет технические условия, закрепленные за арматурой периодического сечения.
- ГОСТ 32486-2013, ГОСТ 32487-2013 и ГОСТ 32492-2013. Подробно показывают все методы по определению характеристик долговечности неметаллической арматуры, устойчивости стрежней к щелочным средам, способы выявления прочности по разным параметрам.
Официальная документация устанавливает параметры для композитной арматуры от четырех до тридцати двух миллиметров. Любой диаметр неметаллической арматуры по СНиП 52-01-2003 разрешается применять в армировании фундаментов. С производства, арматура из стеклопластика диаметром 4-8 мм продается в бухте. Бухты наматывают по заказу, оговаривая заранее необходимую длину. По договоренности, можно заранее заказывать отрезки прута от 1 до 12 метров.
С производства, арматура из стеклопластика диаметром 4-8 мм продается в бухте. Бухты наматывают по заказу, оговаривая заранее необходимую длину. По договоренности, можно заранее заказывать отрезки прута от 1 до 12 метров.
Неметаллические композитные стержни арматуры изготавливаются из волокон различных материалов. Полиэфирные смолы, входящие в их состав, выполняют связывающие функции.
Слой обмотки (анкеровка), нанесенный вокруг стержня, способствует наилучшему сцеплению фундамента с композитом.
Из-за различных составляющих, неметаллическую арматуру классифицируют на:
- Стеклокомпозитная (АСК).
- Углекомпозитная (АУК).
- Базальтокомпозитная (АБК).
- Арамидокомпозитная (ААК).
- Комбинированная с различным композитным составом (АКК).
При армировании, заменять стальную арматуру на гладкую (песчаную) или на стрежни с обмоткой. Слой обмотки или стеклянная нить под определенным углом наносится на гладкий прут. Этот процесс в производстве завершают термообработкой.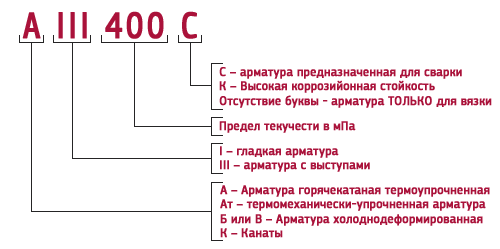
Ребристая арматура прошла все лабораторные исследования и, согласно выводам экспертов, превосходит стальную в сцеплении с бетоном и по коэффициенту прочности на разрыв.
Сомнений нет в том что витая композитная арматура является высоконадежной, использование такого материала доступно даже в самых важных конструкциях.
Композитная арматура с песчаным напылением без обмотки имеет коэффициент сцепления с бетоном гораздо меньше. Однако, поверхностный слой песка защищает стержень арматуры от воздействий агрессивной земной породы. Для стальной арматуры такой защиты нет.
Можно ли использовать обучение с подкреплением для классификации?
8 минут чтения
После изучения обучения с подкреплением кто не задается вопросом, будет ли оно полезно для задач, которые обычно зарезервированы
для контролируемого обучения.
В конце концов, это естественный вопрос.
Итак, я решил выяснить это наилучшим из известных мне способов: написав кучу кода.
Загрузите блокнот Jupyter.
Загрузка экспериментальных данных
В попытке ответить на вопрос, не поглощая свой единственный графический процессор за несколько недель обучения, я выбрал набор данных MNIST.
в качестве экспериментальной базы.
MNIST — это достаточно простая задача, которую можно решить всего за несколько секунд, но в то же время достаточно сложная задача, чтобы ответить на
вопрос о том, можно ли использовать обучение с подкреплением для обучения классификатора.
Если вы не знакомы с этим, MNIST представляет собой набор изображений рукописных цифр (0-9) в черно-белом режиме.
Задача классификации состоит в том, чтобы определить, какую цифру представляет каждое изображение.
Изображения выглядят так:
Итак, давайте закодируем этого плохого мальчика.
Настройка
Наши единственные зависимости — это tensorflow и OpenAI Baselines. Давайте возьмем те
установка пакетов в сторону:
pip установить тензорный поток-gpu-1.15.5 pip install git+https://github.com/openai/[электронная почта защищена]
Затем весь импорт сразу:
время импорта импортный тренажерный зал импортировать случайный импортировать numpy как np из тензорного потока импортировать керас из слоев импорта tensorflow.keras из baselines.ppo2 импортировать ppo2 из baselines.common.vec_env.dummy_vec_env импортировать DummyVecEnv импортировать из исходных данных deepq скамья импорта базовых показателей регистратор импорта из базовых показателей импортировать тензорный поток как tf из baselines.common.tf_util импортировать make_session
Теперь мы готовы погрузиться в код.
Получение данных
# Модель/параметры данных
число_классов = 10
input_shape = (28, 28, 1)
# данные, разделенные между обучающими и тестовыми наборами
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Масштабировать изображения в диапазоне [0, 1]
x_train = x_train.astype("float32") / 255
x_test = x_test. astype("float32") / 255
# Убедитесь, что изображения имеют форму (28, 28, 1)
x_train = np.expand_dims (x_train, -1)
x_test = np.expand_dims (x_test, -1)
print("Форма x_train:", x_train.shape)
print(x_train.shape[0], "образцы поездов")
print(x_test.shape[0], "тестовые образцы")
# преобразовать векторы классов в бинарные матрицы классов
y_train_one_hot = keras.utils.to_categorical (y_train, num_classes)
y_test_one_hot = keras.utils.to_categorical (y_test, num_classes)
astype("float32") / 255
# Убедитесь, что изображения имеют форму (28, 28, 1)
x_train = np.expand_dims (x_train, -1)
x_test = np.expand_dims (x_test, -1)
print("Форма x_train:", x_train.shape)
print(x_train.shape[0], "образцы поездов")
print(x_test.shape[0], "тестовые образцы")
# преобразовать векторы классов в бинарные матрицы классов
y_train_one_hot = keras.utils.to_categorical (y_train, num_classes)
y_test_one_hot = keras.utils.to_categorical (y_test, num_classes)
С помощью этого кода мы используем встроенные утилиты keras для загрузки набора данных mnist и загрузки его в память.
Он скопирован прямо со страницы примера keras.
Если вы смотрели какое-либо из моих видео, вы, вероятно, знаете, что я предпочитаю PyTorch, но, учитывая, что я решил
использовать базовые уровни для алгоритмов RL, keras создан как более простая альтернатива базовому уровню контролируемого обучения.
Базовый уровень Кераса
Даже если RL сработает, мы не узнаем, хороша ли она, если нам не с чем ее сравнить.
Давайте исправим это, обучив классификатор на наборе данных MNIST с помощью традиционного контролируемого обучения с использованием Keras.
по определению keras_train (batch_size = 32, эпохи = 2):
модель = keras.Sequential(
[
keras.Input(форма=input_shape),
слои.Свести(),
слои.Dense(64, активация='relu'),
слои.Dense(64, активация='relu'),
слои.Dense (количество_классов, активация = "softmax")
]
)
модель.резюме()
model.compile(loss="categorical_crossentropy", оптимизатор="adam", metrics=["точность"])
start_time = время.время()
model.fit(x_train, y_train_one_hot, batch_size=batch_size, epochs=epochs, validation_split=0,1)
end_time = время.время()
оценка = model.evaluate (x_test, y_test_one_hot, подробный = 0)
print("Потеря теста:", оценка[0])
print("Точность теста:", оценка[1])
print("Время обучения:", end_time - start_time)
keras_train()
Обратите внимание, что он использует MLP с двумя скрытыми слоями по 64 модуля. Это довольно классический размер сети для RL, и я хочу, чтобы все попытки имели примерно одинаковое количество параметров.
Это довольно классический размер сети для RL, и я хочу, чтобы все попытки имели примерно одинаковое количество параметров.
Кроме того, он имеет размер пакета 32, так как это типичный размер пакета, используемый в DQN.
Когда я запускаю его, я получаю такой вывод:
Потеря теста: 0,11103802259191871 Точность теста: 0,9658 Время обучения: 14.185736656188965
Это 96% точности всего за 14 секунд обучения. Довольно внушительный!
RL Тренировочная среда (gym.Env)
С тех пор, как OpenAI выпустила свою библиотеку тренажерного зала, она стала стандартом де-факто для RL.
среды обучения алгоритмам.
Давайте создадим такой, который адаптирует парадигму вознаграждения среды RL к проблеме классификации.
Идея проста: каждый класс изображения — это уникальное действие, которое может выполнить агент. Если он предпримет действие, которое
соответствует правильному классу, даем +1 награду. В противном случае мы даем 0 наград.
Кроме того, ошибка временной разницы делает предположение, что действия на одном этапе влияют на вознаграждение на следующих шагах. Что
Что
в нашей среде это не так. Таким образом, эпизоды, которые длятся дольше одного временного шага, не имеют никакого смысла в этом контексте.
класс MnistEnv (спортзал.Env):
def __init__(self, images_per_episode=1, набор данных=(x_train, y_train), random=True):
супер().__инит__()
self.action_space = спортзал.spaces.Discrete(10)
self.observation_space = gym.spaces.Box (низкий = 0, высокий = 1,
форма=(28, 28, 1),
dtype=np.float32)
self.images_per_episode = images_per_episode
self.step_count = 0
self.x, self.y = набор данных
self.random = случайный
self.dataset_idx = 0
шаг защиты (я, действие):
сделано = ложь
награда = int (действие == self.expected_action)
obs = self._next_obs()
self.step_count += 1
если self.step_count >= self.images_per_episode:
сделано = верно
вернуть наблюдения, награда, сделано, {}
сброс защиты (сам):
self. step_count = 0
obs = self._next_obs()
возврат наблюдений
защита _next_obs(я):
если self.random:
next_obs_idx = random.randint(0, len(self.x) - 1)
self.expected_action = int(self.y[next_obs_idx])
obs = self.x[next_obs_idx]
еще:
obs = self.x[self.dataset_idx]
self.expected_action = int(self.y[self.dataset_idx])
self.dataset_idx += 1
если self.dataset_idx >= len(self.x):
поднять StopIteration()
возврат наблюдений
step_count = 0
obs = self._next_obs()
возврат наблюдений
защита _next_obs(я):
если self.random:
next_obs_idx = random.randint(0, len(self.x) - 1)
self.expected_action = int(self.y[next_obs_idx])
obs = self.x[next_obs_idx]
еще:
obs = self.x[self.dataset_idx]
self.expected_action = int(self.y[self.dataset_idx])
self.dataset_idx += 1
если self.dataset_idx >= len(self.x):
поднять StopIteration()
возврат наблюдений
Полученный код для тренажерного зала Env довольно прост.
Единственное, что следует отметить, это то, что мы можем поменять местами набор данных и случайных параметров на функцию __init__ для
превратить тренажерный зал в оценочную скамью на тестовом наборе.
Момент истины
Теперь узнаем раз и навсегда. Можно ли использовать RL для классификации?
Сначала мы будем тренироваться с дуэльной глубокой Q-сетью.
определение mnist_dqn():
logger.configure(dir='./logs/mnist_dqn', format_strs=['stdout', 'tensorboard'])
env = MnistEnv (images_per_episode = 1)
env = скамейка.Monitor (env, logger.get_dir())
модель = deepq.learn(
окружение,
"млп",
количество_слоев=1,
номер_скрытый = 64,
активация=tf.nn.relu,
скрытые=[32],
дуэль = правда,
лр=1е-4,
total_timesteps=int(1.2e5),
размер_буфера=10000,
исследовательская_фракция = 0,1,
explore_final_eps=0,01,
поезд_частота = 4,
Learning_starts=10000,
target_network_update_freq=1000,
)
model.save('dqn_mnist.pkl')
env.close()
модель возврата
start_time = время.время()
dqn_model = mnist_dqn()
print("Время обучения DQN:", time.time() - start_time)
Это довольно стандартные вещи, ничего необычного не происходит. Мы используем реализацию DQN из
Базовые показатели OpenAI.
Размер пакета равен 32, как и в модели keras, а общее количество временных шагов равно 120 000, что в два раза превышает количество выборок.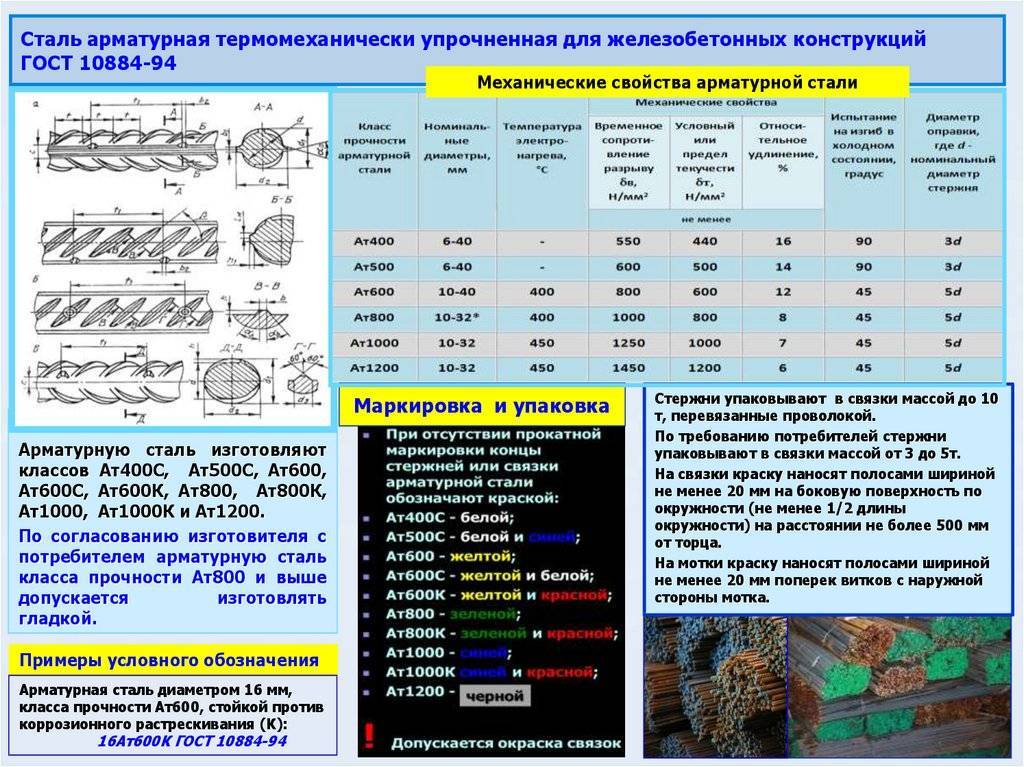
в тренировочном наборе. Это имитирует 2 эпохи, как мы используем в модели keras.
По сравнению с контролируемым базовым планом существует архитектурная разница. Дуэльная часть алгоритма ломается
вместо этого последний слой на два отдельных слоя по 32 единицы. Эти две головки сходятся по отдельности в один выход, и
вывод для каждого действия.
В конечном счете, это означает, что параметров станет на несколько меньше, но мы все еще на том же уровне.
Окончательный вывод после обучения выглядит так:
-------------------------------------- | % времени, потраченного на изучение | 1 | | эпизоды | 1.2e+05 | | средняя награда за 100 эпизодов | 1 | | шаги | 1.2e+05 | -------------------------------------- Время обучения DQN: 461,527117729187
потребовалось намного больше времени (более чем в 30 раз), чем контролируемый базовый уровень, но похоже, что точность была достигнута на 100%.
на тренировочном комплексе!
Давайте запустим оценку и посмотрим, как она выдержит испытание на тестовом наборе.
определение mnist_dqn_eval (dqn_model):
попытки, верно = 0,0
env = MnistEnv (images_per_episode = 1, набор данных = (x_test, y_test), random = False)
пытаться:
пока верно:
obs, выполнено = env.reset(), False
пока не сделано:
obs, rew, done, _ = env.step(dqn_model(obs[None])[0])
попытки += 1
если рев > 0:
правильно += 1
кроме StopIteration:
Распечатать()
print('проверка завершена...')
print('Точность: {0}%'.format((число с плавающей запятой (верно) / количество попыток) * 100))
mnist_dqn_eval (dqn_model)
Аааааанннндддд… результаты:
Точность: 93,47869573914784%
Точность 93,4%!
Ну, я думаю, это ответ, обучение с подкреплением определенно можно использовать в качестве классификатора.
То есть до тех пор, пока вы готовы ждать в 30 раз больше времени, чтобы обучить его с помощью RL.
Можем ли мы сделать лучше? Может это просто алгоритм. DQN, в конце концов, не король алгоритмов RL.
Тестирование с королем
Чтобы выяснить, можем ли мы добиться большего успеха, мы собираемся провести еще один эксперимент с королем алгоритмов RL.
… барабанная дробь …
Оптимизация проксимальной политики (PPO), представленная
Джон Шульман в 2017 году уже некоторое время занимает место короля алгоритмов.
Это алгоритм, который достаточно гибок, чтобы применяться ко многим типам задач, и достаточно надежен, чтобы не требовать многого.
настройка гиперпараметров.
На самом деле он оказался настолько хорош, что всех удивило, когда OpenAI использовал его для обучения ботов DOTA 2, которые нас раздавили
простые смертные в профессиональной игре.
Итак, давайте посмотрим, как он работает в качестве скромного классификатора.
определение mnist_ppo():
logger.configure(dir='./logs/mnist_ppo', format_strs=['stdout', 'tensorboard'])
env = DummyVecEnv([лямбда: скамейка. Monitor(MnistEnv(images_per_episode=1), logger.get_dir())])
модель = ppo2.learn(
окружение = окружение,
сеть = 'млп',
число_слоев = 2,
номер_скрытый = 64,
nшагов=32,
total_timesteps=int(1.2e5),
семя = целое (время. время ()))
модель возврата
start_time = время.время()
ppo_model = mnist_ppo()
print("Время обучения PPO:", time.time() - start_time)
Monitor(MnistEnv(images_per_episode=1), logger.get_dir())])
модель = ppo2.learn(
окружение = окружение,
сеть = 'млп',
число_слоев = 2,
номер_скрытый = 64,
nшагов=32,
total_timesteps=int(1.2e5),
семя = целое (время. время ()))
модель возврата
start_time = время.время()
ppo_model = mnist_ppo()
print("Время обучения PPO:", time.time() - start_time)
То же самое, что и с DQN, это стандартная установка с использованием базовой реализации PPO в нашей среде.
Архитектурно модель PPO добавляет стоимостную главу с одним выходом после последнего уровня MLP. В конце концов, это означает
еще несколько параметров по сравнению с контролируемым базовым уровнем.
После обучения вывод выглядит следующим образом:
-------------------------------------- | среднее значение | 1 | | средний | 0,95 | | кадров в секунду | 177 | | потеря/оккл | 0,131 | | потеря/усечение | 0,0625 | | потеря/policy_entropy | 0,0253 | | потеря/policy_loss | -0,0292 | | убыток/значение_убыток | 0,0271 | | разное/explained_variance | 0,115 | | разное/обновления | 3.75e+03 | | разное/serial_timesteps | 1.2e+05 | | разное/time_elapsed | 638 | | разное/общее_время | 1.2e+05 | -------------------------------------- Время обучения PPO: 638.657053232193
ВОУ! Более 10 минут тренировочного времени, и это даже не на 100% на тренировочном наборе.
Выглядит не очень хорошо, но давайте посмотрим, как это работает на тренировочном наборе.
определение mnist_ppo_eval (ppo_model):
попытки, верно = 0,0
env = DummyVecEnv([лямбда: MnistEnv(images_per_episode=1, набор данных=(x_test, y_test), random=False)])
пытаться:
пока верно:
obs, выполнено = env.reset(), [False]
пока не сделано[0]:
obs, rew, done, _ = env.step(ppo_model.step(obs[None])[0])
попытки += 1
если рев[0] > 0:
правильно += 1
кроме StopIteration:
Распечатать()
print('проверка завершена...')
print('Точность: {0}%'.format((число с плавающей запятой (верно) / количество попыток) * 100))
mnist_ppo_eval(ppo_model)
Функция eval почти копирует/вставляет функцию eval DQN, но учитывает пакетную среду.
Вывод:
Точность: 95,1995199519952%
Точность 95%! Похоже, что PPO имеет преимущество перед DQN, хотя обучение занимает на 150% больше времени.
Тем не менее, мы примерно в 40 раз тратим больше времени на обучение с помощью обучения с учителем, и все еще не с более высокой точностью.
Что важно, так это то, что мы ответили на наш вопрос!
Reinforcement Learning
CAN можно использовать для обучения классификатора.
НО только маньяк будет ждать в 40 раз дольше!
Если вам понравилась эта статья, посетите мой канал на YouTube.
где я обсуждаю различные темы ИИ с упором на RL.
Категории:
ай,
обучение с подкреплением
Обновлено:
Обучение с подкреплением: современная классификация методов машинного обучения (часть 3) | Донни Со
Опубликовано в
·
Чтение: 10 мин.
·
14 июня 2019 г.
В этой третьей части серии под названием Learning Machine Learning мы обсудим последний класс машин методы обучения: обучение с подкреплением . Если вы хотите прочитать мой взгляд на контролируемое/неконтролируемое обучение, вы можете прочитать его здесь и здесь .
Как уже упоминалось, современные алгоритмы машинного обучения можно разделить на один из трех классов: обучение с учителем, обучение без учителя и обучение с подкреплением. Это разделение выбрано из-за того, как эти алгоритмы изучают модель машинного обучения. В частности:
Рассматривающий рост в индустрии машинного обучения вызвал возобновление интереса к людям об искусственном…
www.datadriveninvestor.com
- . Контролируемое обучение: изучает модель по примеру
- Ун.
- Обучение с подкреплением: изучение модели на основе опыта
Во время наших предыдущих обсуждений мы упоминали, что обучение с учителем обычно состоит из помеченных данных, тогда как обучение без учителя работает с данными без обучающих меток.
Вы можете считать обучение с подкреплением (RL) другим, потому что вы не начинаете с каких-либо данных. Скорее вы начинаете с понимания проблемы, которую пытаетесь решить. Например, если вы хотите решить навигационную задачу о перемещении из точки А в точку Б с помощью обучения с подкреплением, вам нужно будет определить следующее:
- Агент
- в точку B. Это может включать различные промежуточные этапы вознаграждения между точками A и B.
- Среда ( состояние ) и то, как агент наблюдает среду, в которой находятся точки A и B. двигаться вверх, вниз, влево, вправо)
В этом навигационном примере агент находится в среде, и его цель состоит в том, чтобы добраться из точки А в точку Б. Агент достигает этой цели, выполняя действий . Эти действия агента могут привести к вознаграждает , чтобы мотивировать агента, когда он делает правильный выбор. Эти действия также могут изменить состояние среды. Наконец, это новое состояние среды наблюдает агент, который затем решает, какое следующее наилучшее действие следует предпринять. Это резюмируется изображением ниже.
Эти действия также могут изменить состояние среды. Наконец, это новое состояние среды наблюдает агент, который затем решает, какое следующее наилучшее действие следует предпринять. Это резюмируется изображением ниже.
Рисунок 1: Взаимодействие между агентом и средой. Источник: http://rll.berkeley.edu/deeprlcourse-fa15/
Давайте используем этот пример маршрутизации в качестве простой иллюстрации того, как может работать RL. Мы начинаем без данных, но агент будет генерировать несколько вариантов маршрутизации, чтобы добраться из точки А в точку Б методом проб и ошибок. Предполагая, что действия, которые мы можем предпринять, следующие:
- Вверх
- Вниз
- Влево
- Вправо
Награда выдается при достижении точки B. Предположим также, что в этой ситуации агент может сделать только четыре шага, прежде чем игра закончится. Затем агент выполняет ряд действий, которые могут выглядеть следующим образом:
Каким должен быть результат строки 3? Ну, это действительно зависит. Если предположить, что агент находится в лабиринте только с тремя горизонтальными квадратами, а состояние окружающей среды до Действия 1 всегда следующее:
Если предположить, что агент находится в лабиринте только с тремя горизонтальными квадратами, а состояние окружающей среды до Действия 1 всегда следующее:
Тогда становится ясно, что важнее всего то, что агенту нужно два раза переместиться вправо, чтобы достичь точки B (Действия агента, движущегося вверх или вниз, становятся несущественными). Действия, предпринятые для ID 3, приводят агента к точке B.
Предположим, что у нас есть альтернативная среда лабиринта как таковая:
Тогда важнее всего то, что агенту нужно спуститься один раз и дважды пройти вправо, чтобы добраться до Точка B. Действия, предпринятые для ID 3, приводят агента к точке B.
В другой альтернативной среде предположим, что теперь у нас есть области в лабиринте, куда агент не может попасть (затемненные области). В этом случае ID 0 и ID 2 перемещают Агента из точки A в точку B, а ID 3 не может. (Вам потребуется, чтобы агент сначала переместился вправо, прежде чем двигаться вниз.)
В задачах RL мы не знаем об окружающей среде. Проблема в RL заключается в том, как мы узнаем, какое следующее наилучшее действие следует предпринять, чтобы максимизировать вознаграждение. Это делается путем генерации данных посредством этого итеративного процесса проб и ошибок, когда агент наблюдает за окружающей средой и предпринимает следующее наилучшее действие.
Проблема в RL заключается в том, как мы узнаем, какое следующее наилучшее действие следует предпринять, чтобы максимизировать вознаграждение. Это делается путем генерации данных посредством этого итеративного процесса проб и ошибок, когда агент наблюдает за окружающей средой и предпринимает следующее наилучшее действие.
Есть два основных метода, которые можно изучить из сгенерированных данных, и это методы Q Learning (обучение на основе ценности) и градиенты политики. Чтобы объяснить эти два метода, я буду решать вводную игру из тренажерного зала OpenAI, известную как CartPole-v0. Мой подход будет заключаться в том, чтобы попытаться объяснить эти методы с точки зрения программирования, и, надеюсь, оттуда мы получим интуицию для любого метода.
Стойка прикреплена к тележке. Когда начинается игровой эпизод, шест находится в вертикальном положении. Тележка может двигаться как влево, так и вправо. В каждый момент времени тележка должна двигаться либо влево, либо вправо. Перемещение тележки влияет на шест. Цель состоит в том, чтобы удерживать шест под определенным углом более 19 секунд.5 моментов времени более 100 последовательных эпизодов. Интуиция такова, что если алгоритм RL способен сбалансировать полюс более чем на 195 моментов времени в 100 эпизодах, это означает, что алгоритм RL понял, как правильно играть в игру.
Цель состоит в том, чтобы удерживать шест под определенным углом более 19 секунд.5 моментов времени более 100 последовательных эпизодов. Интуиция такова, что если алгоритм RL способен сбалансировать полюс более чем на 195 моментов времени в 100 эпизодах, это означает, что алгоритм RL понял, как правильно играть в игру.
Рисунок 2: CartPole-v0
Вкратце:
Награда: Агент получает награду +1 каждый раз, когда шест остается в вертикальном положении.
Действия: Тележка может двигаться только влево или вправо.
Наблюдения: Агент наблюдает за окружающей средой с помощью этих четырех значений:
Дополнительную информацию можно найти здесь.
Интуиция для Q Learning следующая: учитывая определенные наблюдения, какова ожидаемая награда за каждое действие, которое может предпринять агент. Следовательно, Q Learning сродни созданию огромной таблицы поиска, где в каждой точке наблюдения таблица сообщает вам ожидаемые награды за выполнение любого из возможных действий. Давайте разберем это на эти пять деталей:
Давайте разберем это на эти пять деталей:
По сути, основной цикл Q-обучения выглядит просто так:
- Выберите следующее наилучшее действие для выполнения
- Выполните действие в среде
- Наблюдайте/дискретизируйте новое состояние в среде
- Обновите Q-таблицы
- Повторяйте до завершения
концепция в РЛ известный как эксплуатация против разведки. Это означает, что на каждом временном шаге агент может либо выполнить действие, которое в настоящее время он считает лучшим ходом (эксплуатация), либо агент может выполнить новый ход (исследование).
Это можно сделать с помощью жадного эпсилон-метода. Жадный эпсилон генерирует случайное число и проверяет, меньше ли оно переменной (эпсилон). Если это так, используется случайное действие (исследование). В противном случае используется лучшее действие для наблюдения (эксплуатация).
И последнее замечание: в самом начале Q-таблицы в основном пусты, поэтому вам нужно, чтобы агент выполнял больше исследовательских действий. Однако вы хотели бы, чтобы агент становился все более и более эксплуатирующим, поскольку Q-таблицы начинают заполняться, увеличивая эпсилон с течением времени.
Однако вы хотели бы, чтобы агент становился все более и более эксплуатирующим, поскольку Q-таблицы начинают заполняться, увеличивая эпсилон с течением времени.
Как мы видели ранее, наблюдения, возвращенные из окружающей среды, идут непрерывно. Однако при создании Q-таблиц эти числа проще преобразовать в дискретную форму. Это достигается с помощью следующей функции:
Этот элегантный способ дискретизации приписывается этой статье.
Наконец, мы обновляем Q-таблицы, используя формулу:
Полученное значение представляет собой ожидаемую будущую награду за новое действие. Полученная ценность состоит из двух частей: текущей награды и дисконтированной будущей награды. Это обесцененное будущее вознаграждение является оценкой оптимальной будущей стоимости после совершения действия, умноженной на коэффициент дисконтирования (чтобы учесть, что это будущее вознаграждение).
Переменная альфа управляет скоростью обновления существующих значений Q-таблицы.
Последний шаг обновляет альфа-скорость обучения. Как и в случае с epsilon, вначале вы можете захотеть, чтобы обновления были более агрессивными. Однако со временем вы, вероятно, захотите сократить количество обновлений, чтобы сделать вашу таблицу более стабильной.
Как и в случае с epsilon, вначале вы можете захотеть, чтобы обновления были более агрессивными. Однако со временем вы, вероятно, захотите сократить количество обновлений, чтобы сделать вашу таблицу более стабильной.
Интуиция для градиентов политики такова: при определенных наблюдениях какая политика является наилучшей для агента. Градиенты политики немного сложнее, но стоит отметить, что недавние достижения в области RL относятся к градиентам политики.
Программно вы можете представить, что существует основной цикл, который определяет, какими должны быть политики. В этом случае мы будем использовать нейронную сеть и основной цикл, чтобы узнать эти политики. Следовательно, мы будем описывать нейронную сеть и три основные детали этого цикла:
- Нейронная сеть
- Прямой проход (вычислить выходные действия нейронной сети)
- Вычислить вознаграждение (вычислить данные обучения, нейронная сеть)
- Функция потерь
- Обратный проход (обновление весов нейронной сети)
Мы показываем построенную нами нейронную сеть. Он состоит из двух скрытых слоев по 32 узла.
Он состоит из двух скрытых слоев по 32 узла.
Detail two передает в нейронную сеть текущее состояние окружающей среды и генерирует вероятности действий. Мы вызываем случайный выбор (на основе вероятностей действий, предоставляемых нейронной сетью), чтобы решить, какое действие мы предпримем.
Во-вторых, мы генерируем список действий из прямых проходов для передачи в среду. Когда мы скармливаем эти действия окружающей среде, мы получаем список вознаграждений благодаря этому списку действий.
Из списка действий мы вычисляем вектор, известный как текущее вознаграждение. Это постоянное вознаграждение рассчитывается с учетом вознаграждений, полученных от этой текущей временной метки до конечной точки. Однако награды, заработанные дальше, будут обесценены.
Чтобы описать функцию потерь градиентов политики, мы сначала опишем функцию отрицательного логарифмического правдоподобия контролируемого обучения как
Это похоже на максимизацию вероятностного члена в левой части уравнения. Для градиентов политики формула аналогична, но с добавлением члена A , который известен как преимущество. В RL преимущество заменяется кумулятивным вознаграждением со скидкой.
Для градиентов политики формула аналогична, но с добавлением члена A , который известен как преимущество. В RL преимущество заменяется кумулятивным вознаграждением со скидкой.
Следовательно, это дает нам следующую реализацию, где мы берем журнал:
- выход модели (вероятность предпринятого действия) умножается на
- фактическое действие предпринято
Этот логарифмический член умножается далее по льготному вознаграждению.
Наконец, мы используем оптимизатор Adam для обновления весов нейронной сети на основе функции потерь журнала.
Эндрю Нг сказал, что ажиотаж и рекламная шумиха вокруг обучения с подкреплением немного непропорциональны экономической ценности, которую оно создает сегодня (источник). Сказав это, были некоторые конкретные отрасли, которые добились успеха в применении RL. Примеры:
- Финансы (Оформление сделок в JP Morgan Chase)
- Проблемы управления/робототехники (управление светофором, навигация по охлаждению центра обработки данных)
- Спонсируемые поисковые торги в режиме реального времени (Alibaba)
Вы можете сказать, что все эти приложения имеют общую черту RL. А именно, способ определения проблемы в качестве агента, наблюдения и принятия мер в среде с очень четкими результатами вознаграждения (например, охлаждение центра обработки данных вознаграждает экономию затрат; управление светофором снижает вознаграждение за задержки / перегрузки).
А именно, способ определения проблемы в качестве агента, наблюдения и принятия мер в среде с очень четкими результатами вознаграждения (например, охлаждение центра обработки данных вознаграждает экономию затрат; управление светофором снижает вознаграждение за задержки / перегрузки).
Сопутствующую серию коротких видеолекций можно найти на YouTube здесь.
На этом завершается вводная серия из трех частей, посвященная современным классификациям машинного обучения. Надеюсь, вам было так же интересно их читать, как мне их писать!
Автор является доцентом Сингапурского технологического института (SIT). Он имеет степень доктора компьютерных наук Имперского колледжа. Он также имеет степень магистра компьютерных наук NUS по программе Singapore MIT Alliance (SMA).
Мнения, изложенные в этой статье, принадлежат автору и не обязательно отражают официальную политику или позицию каких-либо организаций, с которыми связан автор. Автор также не имеет аффилированных лиц и не получает никаких вознаграждений от каких-либо продуктов, курсов или книг, упомянутых в этой статье.
