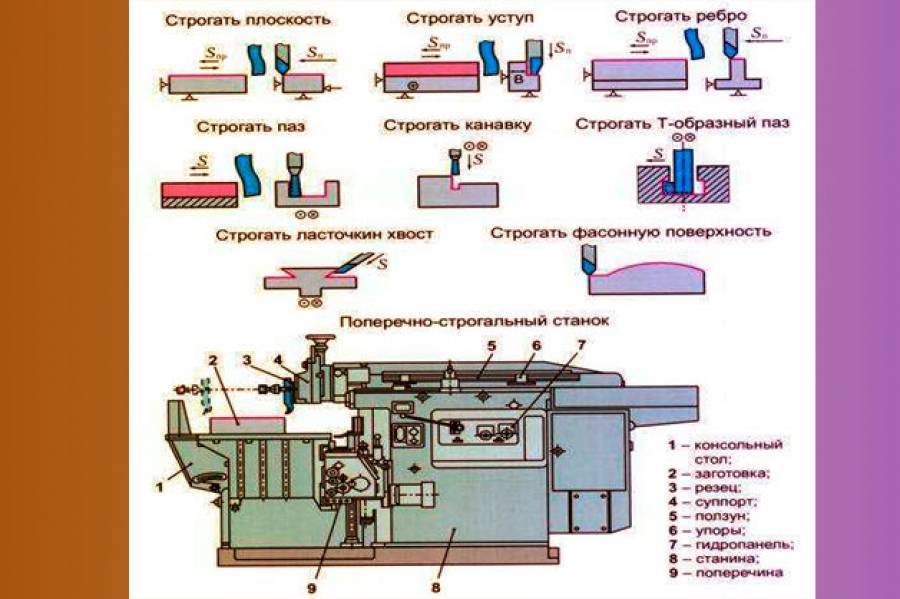
Модель станка это: Классификация металлорежущих станков.
Содержание
Модели на ЧПУ что это такое и как с ними работать
Модели на ЧПУ
2016-09-02
Модели на ЧПУ понимается точное математическое отображение реального объекта. Изначально такие модели создаются в виртуальной среде (компьютерной программе) на основании имеющихся данных (чертежей или рисунков). Напротив, по имеющейся 3D-модели можно воссоздать реальный объект, например, изготовив его на автоматическом станке. Возможность моделировать детали в виртуальной среде и с лёгкостью воплощать их «в материале» является одним из самых главных преимуществ современного станочного оборудования с ЧПУ.
Затраты на модели на ЧПУ гораздо ниже, чем на изготовление пробных образцов продукции. А возможность оценить на экране компьютера готовый результат ещё до начала производства позволяет не только экономить ресурсы и время, но и разрабатывать уникальные изделия, полностью используя технологический потенциал фрезерного оборудования.
Виды 3D-моделей
Простейшим примером 3D-модели является изометрический рисунок. Даже будучи изображённым на листе бумаги он помогает представить реальный объект в трёхмерном пространстве. Современные CAD-приложения позволяют создавать 3D-модели на основе плоских чертежей или рисунков – разумеется, переведённых в электронный вид. Такие модели, помимо внешней идентичности реальному объекту, могут нести информацию о его свойствах – материале, плотности, объёме, массе и т.д. Точная трёхмерная модель получается и при съёмке реального объекта 3D-сканером. Кроме того, в настоящее время существуют обширные библиотеки готовых 3D-моделей (от простейших, до настоящих дизайнерских шедевров) на базе которых успешно выпускаются реальные изделия.
Даже будучи изображённым на листе бумаги он помогает представить реальный объект в трёхмерном пространстве. Современные CAD-приложения позволяют создавать 3D-модели на основе плоских чертежей или рисунков – разумеется, переведённых в электронный вид. Такие модели, помимо внешней идентичности реальному объекту, могут нести информацию о его свойствах – материале, плотности, объёме, массе и т.д. Точная трёхмерная модель получается и при съёмке реального объекта 3D-сканером. Кроме того, в настоящее время существуют обширные библиотеки готовых 3D-моделей (от простейших, до настоящих дизайнерских шедевров) на базе которых успешно выпускаются реальные изделия.
По характеру и сложности, а также типу представления в виртуальной среде модели бывают:
Каркасные (их ещё называют «проволочные») являются примером простейших моделей, состоящих из отрезков, дуг, рёбер и прочих формообразующих линий. Получаемый «каркас» даёт представление лишь о внешнем виде объекта и не несёт информации о его внутренних свойствах. Однако со своей задачей – визуализацией объекта – каркасные модели справляются вполне, занимая к тому же очень мало машинной памяти. Кроме того, каркасное моделирование идеально подходит для представления маршрута движения обрабатывающего инструмента, например при создании управляющей программы для фрезерного станка.
Однако со своей задачей – визуализацией объекта – каркасные модели справляются вполне, занимая к тому же очень мало машинной памяти. Кроме того, каркасное моделирование идеально подходит для представления маршрута движения обрабатывающего инструмента, например при создании управляющей программы для фрезерного станка.
Поверхностные модели, помимо контуров (или «рёбер») объекта включают в себя информацию о типе поверхности – своеобразной оболочке, отделяющей объект от окружающего «пространства».
Твердотельные модели по своей сути являются точной математической копией реального объекта и широко используются в системах компьютерного проектирования для создания новых изделий, либо исследований свойств и взаимного влияния существующих конструкций.
Процесс разработки модели на ЧПУ
Как описывалось выше, трёхмерную модель можно построить из плоских изображений – этот путь изначально использовался в чертёжных программах (подобных AutoCAD). Однако способ разработки плоских чертежей и построения на их базе 3D-моделей довольно трудоёмкий.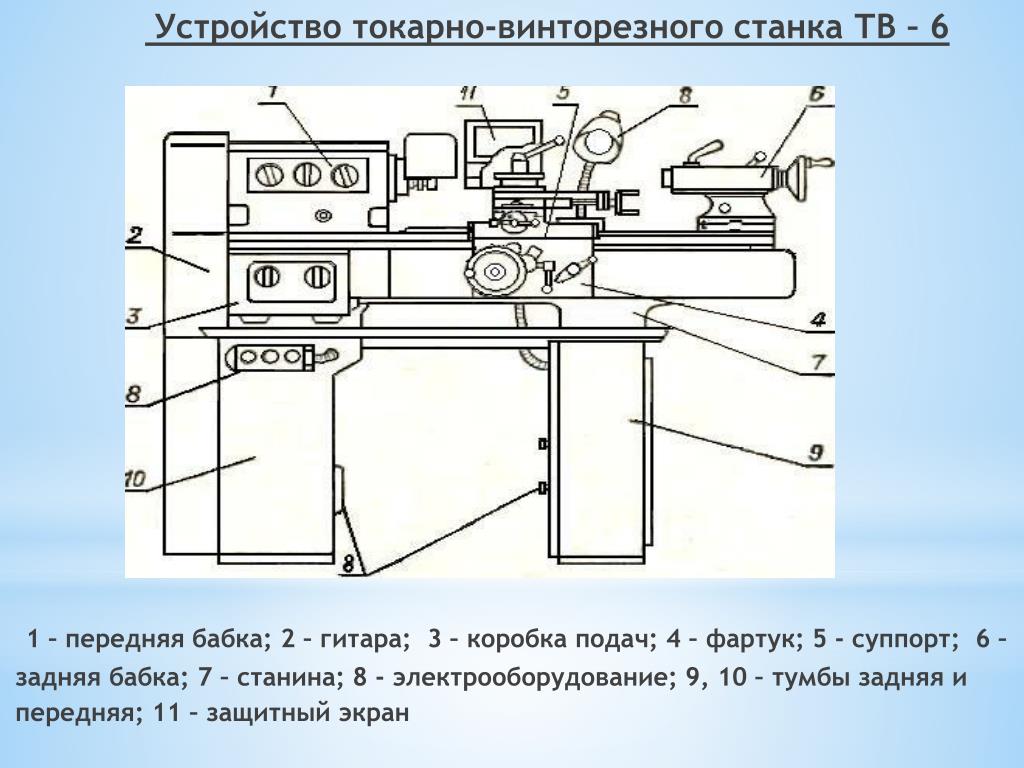 Более рационально сразу же создавать трёхмерные объекты (при необходимости из них легко получаются любые плоские «снимки», в том числе 2D-чертежи) – на таком алгоритме работают программы Pro/Engeneer, CATIA, SolidWorks, Autodesk Inventor и пр. Все они предназначены для работы с твердотельными моделями. Однако из-за различия форматов, графические файлы не всегда совместимы.
Более рационально сразу же создавать трёхмерные объекты (при необходимости из них легко получаются любые плоские «снимки», в том числе 2D-чертежи) – на таком алгоритме работают программы Pro/Engeneer, CATIA, SolidWorks, Autodesk Inventor и пр. Все они предназначены для работы с твердотельными моделями. Однако из-за различия форматов, графические файлы не всегда совместимы.
Для устранения этого недостатка существуют универсальные форматы файлов, в которые осуществляется экспорт 3D-моделей с последующим импортом в нужное приложение. К ним относятся: ACIS (*.sat), STEP AP203/214 (*.step,*.stp), IGES (*.igs,*.iges) и ряд других.
Производство изделий на базе 3D-моделей
Трёхмерная модель является отличным базисом для производства изделий. Современные станки с ЧПУ реализуют алгоритм программного управления, а чем ещё является 3D-модель, как не программным «шифром» реального изделия?
Однако для создания управляющей программы изготовления детали (например, методом фрезерования), 3D-моделей должна быть подвергнута некоторой обработке.
Во-первых, необходимо «привязать» модель к плоскости виртуальной заготовки, установить припуски на обработку, задать уклоны торцевых поверхностей, глубину фрезерования (не более толщины заготовки) и т.д.
Во-вторых, следует указать область крепления заготовки, чтобы в реальности фреза не «спотыкалась» на удерживающих струбцинах.
В-третьих, следует определить этапы фрезерования, задать соответствующие им зоны обработки.
В-четвёртых, необходимо построить траекторию движения фрезы для каждого этапа обработки. Здесь следует учесть материал заготовки, величину припуска на обработку и необходимую смену инструмента между этапами.
В-пятых, следует провести визуализацию процесса обработки (своего рода «виртуальную фрезеровку») и проконтролировать результат. Исправить ошибки на этом этапе гораздо проще и выгоднее, чем перекидать испорченные на станке заготовки в брак!
Завершающим этапом создания управляющей программы (УП) является её экспорт в файл формата, «понятного» для фрезерного станка. Современные программные комплексы подготовки 3D-моделей к производству (например, ArtCAM) содержат обширную базу данных так называемых «постпроцессоров» — специальных модулей, оптимизирующих УП под конкретную модель станка. Таким образом, имея электронные файлы УП, остаётся лишь загрузить их в память станка, установить фрезу, закрепить на рабочем столе заготовку, нажать клавишу «пуск» и дожидаться окончания обработки изделия, будучи совершенно уверенным в его высоком качестве!
Современные программные комплексы подготовки 3D-моделей к производству (например, ArtCAM) содержат обширную базу данных так называемых «постпроцессоров» — специальных модулей, оптимизирующих УП под конкретную модель станка. Таким образом, имея электронные файлы УП, остаётся лишь загрузить их в память станка, установить фрезу, закрепить на рабочем столе заготовку, нажать клавишу «пуск» и дожидаться окончания обработки изделия, будучи совершенно уверенным в его высоком качестве!
Создание моделей для фрезерного ЧПУ станка. Особенности
Модели для ЧПУ – это, по сути, шаблоны, готовые к производству. Они могут иметь стандартный двухмерный вид, а также 3D. Модели отличаются широким разнообразием – от простейших изделий до сложных резных элементов.
Создание прототипа будущей детали – сложная задача, требующая особых навыков в моделировании. На сайте for3d.ru представлен широкий ассортимент моделей для ЧПУ. Каталог товаров рассортирован по категориям для удобства клиента.
3d модели широко используются в производстве. Виртуальные образцы будущих изделий могут иметь различную степень сложности – от простых двухмерных рисунков до сложных трехмерных моделей.
В чем преимущество моделей для фрезерного ЧПУ перед обычными производственными методами? Благодаря широкому программному комплексу у специалиста появляется возможность создавать сложные изделия с минимальными финансовыми и ресурсными затратами. Для создания прообраза будущей детали или готового продукта достаточно ввести его параметры в компьютер.
Какова выгода для производителя? Приобретая готовые ЧПУ-модели, вы получаете макет, готовый к загрузке в станок с программным управлением. Для удобства все 3d модели представляются в формате stl. Почему? Дело в том, что stl. – единый формат для всего 3д-моделирования, который может открыться на любых устройствах. Он удобен вне зависимости от задач, стоящих перед вами. При необходимости в модели можно изменять некоторые размеры и изменять детали непосредственно в процессе производства.
Он удобен вне зависимости от задач, стоящих перед вами. При необходимости в модели можно изменять некоторые размеры и изменять детали непосредственно в процессе производства.
Подробнее об stl мы писали в данной статье.
3d модели для деревообрабатывающих станков:
Выполнение резьбы по дереву – сложный и трудоемкий процесс, выполнение которого вручную займет длительное время. Благодаря фрезерному станку работа может быть выполнена в несколько раз быстрее, а при наличии готовой модели от вас требуется лишь запустить изделие в производство.
Замена ручной резьбы обеспечивает значительное удешевление готового продукта.
С помощью 3d фрезера можно изготовить:
- Резные мебельные элементы: поручни, ножки, спинки и многое другое.
- Резьбу на ограждениях, балясинах, лестницах.

- Накладки и кронштейны.
- Оправы картин, зеркал, часов.
- Резные статуи и иконы.
- И многое другое.
Используя 3д модели, вы можете наладить серийное производство оригинальных деревянных изделий. В процессе работы влияние человеческого фактора сведено до минимума – человек участвует в производстве только на процессе моделирования.
Читайте подробнее в статье о 3д моделях для станков по дереву.
3д модели для станков по обработке металла:
Применение 3D – моделирования не ограничивается только древесиной – оно с успехом используется для обработки металлов.
Stl-модели используются в производстве медалей, рамок и оправ, элементов мебели и фурнитуры. Созданные модели применяются для изготовления путем лазерной резки и гравировки.
Готовые 3д модели имеют целый ряд преимуществ:
- Скорость производства с помощью ЧПУ- станков возрастает в несколько раз.
- 3d – безальтернативный вариант при серийном производстве.
 Станок может без перерыва «штамповать» детали, при этом сохраняя безупречное качество.
Станок может без перерыва «штамповать» детали, при этом сохраняя безупречное качество. - Снижение себестоимости изделия.
Можно ли создать некачественную модель ЧПУ?
Не исключено, что без должной подготовки можно создать приличную 3d модель. Но подобное встречается редко. Как минимум, человек должен обладать математическим складом ума и легко работать в нужных программах.
Самостоятельное изучение тематического материала дает свои плоды, но регулярная практика все же необходима. При отсутствии ее и профильного образования создаются некачественные модели для ЧПУ. Их использование сильно сказывается на финансовой составляющей проекта. Так как неточность в размерах, узорах, изгибах и прочего провоцирует создание объекта, не отвечающего изначальным требованиям. И его приходится дорабатывать или изготавливать снова, но уже по откорректированной модели.
Помимо материальных ресурсов затрачиваются при этом и временные. Время сейчас — самое дорогое удовольствие, и при возможности лучше потратить его на повышение квалификации или получение образования в сфере моделирования.
Можно использовать качественные модели, просто приобретая их в готовом виде. Сделать это можно в большинстве интернет-магазинов, ориентированных на ЧПУ. For3d.ru, лидирующий среди них, гарантирует высокую точность 3d моделей, созданных целой командой профессионалов.
Еще статьи по теме:
- Где взять готовые модели для ЧПУ?
- Топ-10 наиболее востребованных изделий
- Как научиться 3d моделированию?
- Все о разработке 3д моделей. Программы, цены, сроки.
Как это работает и почему это важно
Модели являются центральным продуктом науки о данных, и они обладают огромной силой для преобразования компаний, отраслей и общества. В основе каждого приложения машинного обучения или искусственного интеллекта лежит модель ML/AI, построенная с использованием данных, алгоритмов и кода. Несмотря на то, что модели выглядят как программное обеспечение и содержат данные, модели имеют разные исходные материалы, разные процессы разработки и разное поведение.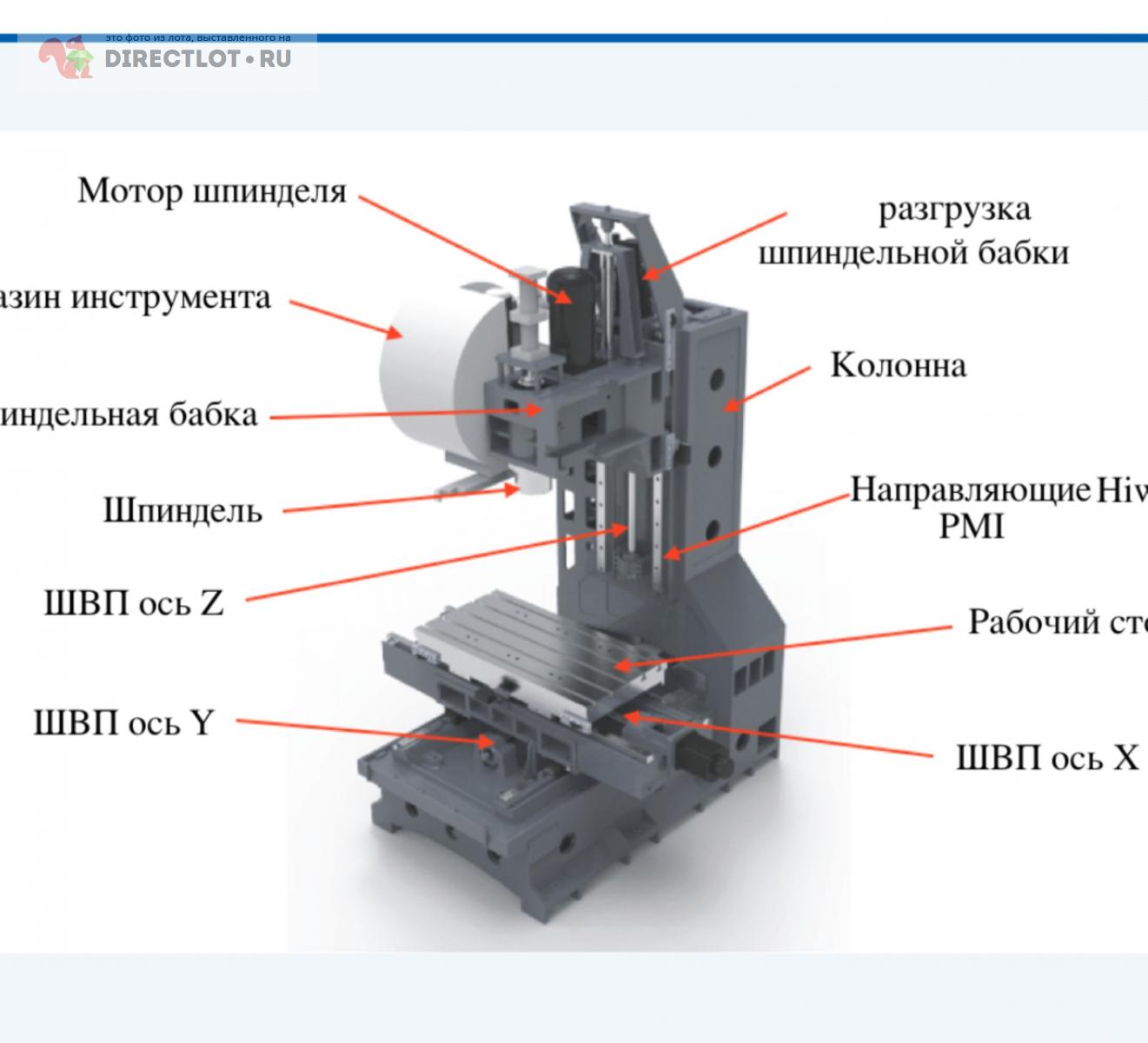 Процесс создания моделей называется моделированием.
Процесс создания моделей называется моделированием.
Что такое машинное обучение?
Модель — это особый тип алгоритма. В программном обеспечении алгоритм представляет собой жестко закодированный набор инструкций для вычисления детерминированного ответа. Модели — это алгоритмы, инструкции которых выводятся из набора данных и затем используются для прогнозирования, рекомендаций или предписания действий на основе вероятностной оценки. В модели используются алгоритмы для выявления шаблонов в данных, которые формируют связь с выходными данными. Модели могут предсказывать события до того, как они произойдут, более точно, чем люди, например, катастрофические погодные явления или риск неминуемой смерти в больнице.
Почему важны модели машинного обучения?
Модели резко снижают стоимость прогнозирования, подобно тому, как полупроводники резко снижают стоимость арифметики. Это изменение делает модели новой валютой конкурентного преимущества, стратегии и роста. Модели могут основываться друг на друге. Выходные данные одной модели служат входными данными для другой, более сложной модели, а затем создают живую, связанную, обучаемую армию лиц, принимающих решения. К счастью или к сожалению, модели могут делать это автономно, с таким уровнем скорости и сложности, с которым люди не могут даже надеяться.
Выходные данные одной модели служат входными данными для другой, более сложной модели, а затем создают живую, связанную, обучаемую армию лиц, принимающих решения. К счастью или к сожалению, модели могут делать это автономно, с таким уровнем скорости и сложности, с которым люди не могут даже надеяться.
Для организаций, которые руководствуются моделями, моделирование — это не просто процесс создания моделей. Это структура процессов, инструментов и протоколов, которые расширяют возможности команды специалистов по обработке и анализу данных на каждом этапе жизненного цикла анализа данных (DSLC).
Управление моделями лежит в основе моделирования, которое включает в себя отслеживание артефактов модели с момента создания первой версии модели до окончательной модели, развернутой в производственной среде. Каждый раз, когда модель изменяется или используются новые данные, записываются новые версии. Состояние моделей постоянно отслеживается для отслеживания аномалий, которые могут возникнуть из-за изменений во входных данных, изменений на рынке или любых других изменений, когда входные данные больше не соответствуют данным, используемым при построении модели. Модель, которая не контролируется, может начать давать неточные ответы, которые приведут к снижению эффективности бизнеса, и продолжать делать это без ведома бизнеса.
Модель, которая не контролируется, может начать давать неточные ответы, которые приведут к снижению эффективности бизнеса, и продолжать делать это без ведома бизнеса.
Типы инструментов моделирования
Инструменты моделирования, как правило, основаны на коде, хотя существуют некоторые коммерческие решения для создания простых моделей без кода, а библиотеки и платформы существуют на нескольких языках, чтобы помочь специалистам по данным ускорить свою работу. Эти инструменты содержат библиотеки алгоритмов, которые можно использовать для быстрого и эффективного создания моделей. Многие инструменты моделирования имеют открытый исходный код и основаны на Python, хотя обычно используются другие языки, такие как R, C++, Java, Perl и многие другие. Некоторые популярные библиотеки инструментов и фреймворки:
- Scikit-Learn: используется для методов машинного обучения и статистического моделирования, включая классификацию, регрессию, кластеризацию и уменьшение размерности, а также прогнозный анализ данных.

- XGBoost: — это библиотека с открытым исходным кодом, которая предоставляет инфраструктуру повышения градиента регуляризации для различных языков программирования.
- Apache Spark: — это унифицированный аналитический механизм с открытым исходным кодом, предназначенный для масштабирования требований к обработке данных.
- PyTorch: используется для моделей глубокого обучения, таких как обработка естественного языка и компьютерное зрение. Основанная на Python, она была разработана исследовательской лабораторией искусственного интеллекта Facebook как библиотека с открытым исходным кодом.
- TensorFlow: похож на PyTorch, это библиотека Python с открытым исходным кодом, созданная Google, которая поддерживает дополнительные языки. Он используется для разработки моделей глубокого обучения.
- Keras: — это API, построенный на основе TensorFlow, который предлагает упрощенный интерфейс, требующий минимального ручного кодирования.

- Ray: — это платформа библиотеки с открытым исходным кодом, которая имеет простой API для масштабирования приложений от одного процессора до больших кластеров.
- Horovod: — это распределенная среда обучения глубокому обучению, которую можно использовать с PyTorch, TensorFlow, Keras и другими инструментами. Он используется для масштабирования между несколькими графическими процессорами одновременно.
Существуют тысячи доступных инструментов, и для большинства моделей требуется несколько инструментов, которые лучше всего подходят для типа данных и бизнес-задачи.
Как создаются модели машинного обучения?
В бизнес-среде создание новой модели почти всегда связано с проблемой, требующей решения, например, с принятием более обоснованных решений, автоматизацией процедур или поиском закономерностей в огромном объеме данных.
Как только решение этой проблемы определено, оно преобразуется в бизнес-цель, такую как прогнозирование нехватки запасов или определение кредитных лимитов для банковских клиентов. Затем это можно перевести в техническую проблему, которую необходимо решить с помощью моделей ML/AI.
Затем это можно перевести в техническую проблему, которую необходимо решить с помощью моделей ML/AI.
В зависимости от типа бизнес-проблемы и доступных данных определяется подход, который лучше всего подходит для этой проблемы. Существуют различные типы подходов к машинному обучению, в том числе:
- Контролируемое обучение: используется, когда вы знаете, что модель должна изучить, обычно в прогнозировании, регрессии или классификации. Вы подвергаете алгоритм обучающим данным, позволяете модели анализировать выходные данные и корректировать параметры, пока не достигнет желаемой цели.
- Обучение без учителя: модель может свободно исследовать данные и выявлять закономерности между переменными. Это полезно для группировки неструктурированных данных на основе статистических свойств. Поскольку это не требует обучения, это гораздо более быстрый процесс.
- Обучение с подкреплением: используется с ИИ или нейронными сетями, когда модели необходимо взаимодействовать с окружающей средой.
 Когда модель совершает желаемое действие, ее поведение подкрепляется вознаграждением.
Когда модель совершает желаемое действие, ее поведение подкрепляется вознаграждением. - Регрессия: используется для обучения контролируемых моделей. Он используется для прогнозирования или объяснения числового значения с использованием предыдущего набора данных, например прогнозирования изменений процентных ставок на основе исторических экономических данных.
- Классификация: используется для прогнозирования или объяснения значений класса в контролируемом обучении. Это часто используется в электронной коммерции, например, для прогнозирования покупок клиентов или ответов на рекламные объявления.
- Кластеризация: используется при неконтролируемой разработке, эти модели группируют данные по сходству или общим свойствам. В бизнесе их можно использовать для сегментации потребительских рынков. Социальные сети и видеоплатформы могут использовать кластеризацию, чтобы рекомендовать новый контент.
- Деревья решений: используют алгоритм для классификации объектов, отвечая на вопросы об их атрибутах.
 В зависимости от ответа, например «да» или «нет», модель переходит к другому вопросу, а затем к другому. Эти модели можно использовать для интеллектуального ценообразования и ботов обслуживания клиентов.
В зависимости от ответа, например «да» или «нет», модель переходит к другому вопросу, а затем к другому. Эти модели можно использовать для интеллектуального ценообразования и ботов обслуживания клиентов. - Глубокое обучение: предназначен для воспроизведения структуры человеческого мозга. Это также называется нейронными сетями, где миллионы связанных нейронов создают сложную структуру, которая многократно обрабатывает и перерабатывает данные, чтобы получить ответ.
После получения данных они подготавливаются в соответствии с конкретным подходом и могут включать удаление ненужных или повторяющихся данных из набора данных. Затем специалист по данным проведет эксперименты с разными алгоритмами и сравнит производительность с другим набором данных. Например, модель распознавания изображений будет обучена на одном наборе изображений, а затем протестирована на новом наборе изображений, чтобы убедиться, что она будет работать должным образом. Как только производительность будет соответствовать потребностям бизнес-задачи, она будет готова к развертыванию.
Даже после того, как модель кажется стабильной и работает с ожидаемыми параметрами, ее все равно необходимо контролировать. Это можно сделать автоматически с помощью платформы Domino Model Monitor, указав метрики точности модели, а затем заставив платформу уведомить вас, если модель работает за пределами этих метрик. Например, если точность модели начнет снижаться, необходимо будет выяснить причину и либо переобучить модель, используя обновленное представление данных, либо вообще построить новую модель.
Управление модельным риском
Модельный риск, при котором модель используется и не дает желаемого результата, может быть исключительно опасным, если для управления им не реализованы меры безопасности. Это сводится к модели управления рисками. Если вы знакомы с финансами, вы обнаружите, что управление рисками моделей в науке о данных похоже на управление рисками для финансовых моделей. Модель управления рисками включает пять ключевых аспектов, одним из которых является управление моделью.
- Определение модели: подробно описывает постановку проблемы, лежащую в основе генезиса модели, цель вывода модели, а также все используемые решения, модификации и наборы данных.
- Управление рисками: включает политики, процедуры и средства контроля, которые необходимо внедрить.
- Управление жизненным циклом: определяет зависимости модели и факторы, которые необходимо учитывать на протяжении всего жизненного цикла модели.
- Effective Challenge : независимая оценка и проверка, чтобы убедиться, что все решения, принятые во время разработки, являются правильными.
Независимо от производительности модели, необходимо надлежащее управление рисками модели, чтобы гарантировать, что модель соответствует желаемым и нормативным требованиям для организации.
Моделирование в Enterprise MLOps
По мере роста организаций сложность, необходимая для управления, разработки, развертывания и мониторинга моделей в группах и инструментах, может остановить прогресс. Корпоративные платформы MLOps специально созданы для того, чтобы помочь масштабировать науку о данных между различными командами и инструментами с помощью общих сред управления и управления рисками моделей, поддерживая при этом стандартизированные процессы разработки, развертывания и мониторинга для всех типов моделей. Организации, основанные на моделях и подпитываемые корпоративными MLOps, могут извлечь выгоду из новой валюты конкурентного преимущества, стратегии и роста — моделей AI/ML.
Корпоративные платформы MLOps специально созданы для того, чтобы помочь масштабировать науку о данных между различными командами и инструментами с помощью общих сред управления и управления рисками моделей, поддерживая при этом стандартизированные процессы разработки, развертывания и мониторинга для всех типов моделей. Организации, основанные на моделях и подпитываемые корпоративными MLOps, могут извлечь выгоду из новой валюты конкурентного преимущества, стратегии и роста — моделей AI/ML.
Что это такое и почему это важно
Обучение модели машинного обучения (ML) — это процесс, в котором алгоритм машинного обучения получает обучающие данные, на основе которых он может учиться. Модели машинного обучения можно натренировать, чтобы они приносили пользу бизнесу разными способами, путем быстрой обработки огромных объемов данных, выявления закономерностей, обнаружения аномалий или проверки корреляций, которые человеку было бы трудно сделать без посторонней помощи.
Что такое обучение моделей?
Обучение модели лежит в основе жизненного цикла разработки науки о данных, где группа специалистов по обработке и анализу данных работает над подбором наилучших весов и смещений для алгоритма, чтобы минимизировать функцию потерь в диапазоне предсказания. Функции потерь определяют, как оптимизировать алгоритмы ML. Команда специалистов по данным может использовать различные типы функций потерь в зависимости от целей проекта, типа используемых данных и типа алгоритма.
Функции потерь определяют, как оптимизировать алгоритмы ML. Команда специалистов по данным может использовать различные типы функций потерь в зависимости от целей проекта, типа используемых данных и типа алгоритма.
Когда используется метод обучения с учителем, обучение модели создает математическое представление взаимосвязи между функциями данных и целевой меткой. При неконтролируемом обучении он создает математическое представление среди самих признаков данных.
Важность обучения модели
Обучение модели — это первичный этап машинного обучения, в результате которого создается рабочая модель, которую затем можно проверить, протестировать и развернуть. Производительность модели во время обучения в конечном итоге определит, насколько хорошо она будет работать, когда она в конечном итоге будет помещена в приложение для конечных пользователей.
Как качество обучающих данных, так и выбор алгоритма являются центральными элементами этапа обучения модели. В большинстве случаев обучающие данные разбиваются на два набора для обучения, а затем проверки и тестирования.
Выбор алгоритма в первую очередь определяется конечным вариантом использования. Однако всегда необходимо учитывать дополнительные факторы, такие как сложность модели алгоритма, производительность, интерпретируемость, требования к компьютерным ресурсам и скорость. Уравновешивание этих различных требований может сделать выбор алгоритмов запутанным и сложным процессом.
Как обучить модель машинного обучения
Обучение модели требует систематического, повторяемого процесса, который позволяет максимально эффективно использовать имеющиеся обучающие данные и время вашей группы по обработке и анализу данных. Прежде чем приступить к этапу обучения, вам необходимо сначала определить постановку задачи, получить доступ к набору данных и очистить данные, которые будут представлены в модели.
В дополнение к этому вам необходимо определить, какие алгоритмы вы будете использовать и с какими параметрами (гиперпараметрами) они будут работать. Сделав все это, вы можете разделить свой набор данных на набор для обучения и набор для тестирования, а затем подготовить алгоритмы своей модели для обучения.
Разделить набор данных
Ваши исходные обучающие данные — это ограниченный ресурс, который необходимо распределять осторожно. Некоторые из них можно использовать для обучения вашей модели, а некоторые — для тестирования вашей модели, но вы не можете использовать одни и те же данные для каждого шага. Вы не можете должным образом протестировать модель, если не дали ей новый набор данных, с которым она раньше не сталкивалась. Разделение обучающих данных на два или более набора позволяет обучать, а затем проверять модель с использованием одного источника данных. Это позволяет вам увидеть, является ли модель переоснащенной, что означает, что она хорошо работает с обучающими данными, но плохо с тестовыми данными.
Обычный способ разделения обучающих данных — перекрестная проверка. Например, при 10-кратной перекрестной проверке данные разбиваются на десять наборов, что позволяет обучать и тестировать данные десять раз. Для этого:
- Разделите данные на десять равных частей или сгибов.

- Назначьте одну складку в качестве удерживающей складки.
- Обучите модель остальным девяти сгибам.
- Проверьте модель на удерживающем изгибе.
Повторите этот процесс десять раз, каждый раз выбирая другую складку в качестве удерживающей складки. Средняя производительность по десяти удержанным сгибам — это ваша оценка производительности, называемая перекрёстной оценкой.
Выберите алгоритмы для тестирования
В машинном обучении есть тысячи алгоритмов на выбор, и нет надежного способа определить, какой из них будет лучшим для конкретной модели. В большинстве случаев вы, скорее всего, перепробуете десятки, если не сотни алгоритмов, чтобы найти тот, который приводит к точной рабочей модели. Выбор алгоритмов-кандидатов часто зависит от:
- Размер обучающих данных.
- Точность и интерпретируемость требуемого вывода.
- Требуемая скорость обучения, которая обратно пропорциональна точности.

- Линейность обучающих данных.
- Количество объектов в наборе данных.
Настройка гиперпараметров
Гиперпараметры — это атрибуты высокого уровня, устанавливаемые группой специалистов по обработке и анализу данных перед сборкой и обучением модели. Хотя многие атрибуты можно узнать из обучающих данных, они не могут узнать свои собственные гиперпараметры.
Например, если вы используете алгоритм регрессии, модель может сама определить коэффициенты регрессии путем анализа данных. Однако он не может диктовать силу штрафа, который он должен использовать, чтобы упорядочить избыток переменных. В качестве другого примера, модель, использующая метод случайного леса, может определить, где деревья решений будут разделены, но количество используемых деревьев необходимо настроить заранее.
Подгонка и настройка моделей
Теперь, когда данные подготовлены и определены гиперпараметры модели, пришло время начать обучение моделей. По сути, процесс состоит в том, чтобы перебирать различные алгоритмы, используя каждый набор значений гиперпараметров, которые вы решили изучить. Для этого:
По сути, процесс состоит в том, чтобы перебирать различные алгоритмы, используя каждый набор значений гиперпараметров, которые вы решили изучить. Для этого:
- Разделите данные.
- Выберите алгоритм.
- Настройте значения гиперпараметров.
- Обучить модель.
- Выберите другой алгоритм и повторите шаги 3 и 4.
Затем выберите другой набор значений гиперпараметров, который вы хотите попробовать для того же алгоритма, снова проверьте его перекрестную проверку и рассчитайте новую оценку. После того, как вы попробовали каждое значение гиперпараметра, вы можете повторить те же шаги для дополнительных алгоритмов.
Воспринимайте эти испытания как легкоатлетические заезды. Каждый алгоритм продемонстрировал, что он может делать с различными значениями гиперпараметров. Теперь вы можете выбрать лучшую версию из каждого алгоритма и отправить их на финальный конкурс.
Выберите лучшую модель
Теперь пришло время протестировать лучшие версии каждого алгоритма, чтобы определить, какая из них дает вам наилучшую модель в целом.
- Делайте прогнозы на основе тестовых данных.
- Определите наземную истину для целевой переменной во время обучения этой модели.
- Определите показатели производительности на основе ваших прогнозов и целевой переменной истинности.
- Запустите каждую финалистку с тестовыми данными.
После завершения тестирования вы можете сравнить их производительность, чтобы определить, какие модели лучше. Абсолютный победитель должен был показать хорошие результаты (если не лучшие) как на тренировках, так и на тестах. Он также должен хорошо работать по другим вашим показателям производительности (таким как скорость и эмпирические потери) и, в конечном счете, должен адекватно решать или отвечать на вопрос, поставленный в постановке задачи.
