Станок модели: Классификация и расшифровка токарных станков
Содержание
Универсальный токарный станок модели FD 250 S
Цена: По запросу
Заказать
Рабочая зона
Высота центров, мм
125
Расстояние между центрами, мм
500
Максимальный диаметр обработки над станиной, мм
260
Максимальный диаметр обработки над суппортом, мм
156
Токарный шпиндель
Конус шпинделя (размер) по стандарту DIN 55027
4
Диаметр отверстия токарного шпинделя, мм
38
Внутренний конус шпинделя по DIN 228
5
Инструментальный суппорт
Угол поворота верхней каретки
+40⁰ / — 40⁰
Подачи
Продольное перемещение каретки, мм
80
Поперечное перемещение каретки, мм
80
Инструментальная система
Тип инструментальной системы
инструментальная головка Multifix (размер А)
Задняя бабка
Тип задней бабки
ручная
Ход пиноли, мм
100
Внутренний конус пиноли задней бабки по стандарту DIN 228, мм
МК-3
Привод
Тип привода
с бесступенчатым регулированием
Количество основных ступеней привода
1
Число оборотов, об/мин
60 — 3. 000 (опц. 90 — 4.500)
000 (опц. 90 — 4.500)
Мощность электродвигателя, кВт (пост./30 мин)
2,2/3,7 (пост./в течении 30 мин.)
Прочие характеристики
Потребляемая мощность, кВт
4,0
Номер лакокрасочного покрытия
RAL 5009 (синий) + RAL 7035 (светло серый)
Габаритные размеры и масса
Длина, мм
1.300
Ширина, мм
700
Высота, мм
1.400
Масса станка, кг
510
Скачать каталог в PDF
| Задняя бабка с быстрозажимным приспособлением для цанг и микрометрическим продольным упором |
| Быстрая и удобная фиксация задней бабки и пиноли |
| Поперечный суппорт с удобной фиксацией рукояткой. Верхние салазки с углом поворота каретки +40⁰ / — 40⁰ |
| Инструментальная головка Multifix (размер А) — позволяют быстро устанавливать оптимальный угол резца для различных токарных операций |
Возможность установки приспособлений цанговых быстрозажимных рычажного типа для цанг толкающего типа DIN 6343-32 161 E, для цанг типа 5С: 385E, K32: DIN 6341. |
| Стальной держатель с быстрой заменой типа A |
| Защитный фланец для головки шпинделя DIN 55027-4 |
| Набор рабочих инструментов (пакет инструментов, набор гаечных ключей, масляный шприц) |
| 2 руководства по эксплуатации с перечнем запасных частей и документацией электросхемы |
| Буферные опоры станины |
Сделать заявку
Ваше имя *
Телефон *e-mail *
Текст вопроса
Токарно-винторезный станок модели РТ2511 Ф1 (1М63-8)
- Доска объявлений
- Металлообработка
- Токарное оборудование
- Токарно-винторезные станки
Объявление не актуально!
Предназначен для выполнения разнообразных токарных работ, включая точение конусов и нарезание резьб: метрических, дюймовых, модульных, питчевых. Высокая мощность привода и жесткость станка, широкий диапазон частоты вращения шпинделя и подач позволяют полностью использовать возможности прогрессивных инструментов при обработке различных материалов
Высокая мощность привода и жесткость станка, широкий диапазон частоты вращения шпинделя и подач позволяют полностью использовать возможности прогрессивных инструментов при обработке различных материалов
Токарно-винторезный станок модели РТ2511 Ф1 (1М63-8)
Предназначен для выполнения разнообразных токарных работ, включая точение конусов и нарезание резьб: метрических, дюймовых, модульных, питчевых. Высокая мощность привода и жесткость станка, широкий диапазон частоты вращения шпинделя и подач позволяют полностью использовать возможности прогрессивных инструментов при обработке различных материалов
Наибольший диаметр заготовки, мм (устанавливаемой над станиной) 700
обрабатываемой над станиной, мм 630
обрабатываемой над суппортом 350
Наибольшая длина обрабатываемой заготовки, мм 8000
Колическво ступеней частот вращения шпинделя, мм 22
Пределы частот вращения шпинделя, об/мин 10-1 250
Пределы рабочих подач, мм/об:
продольных поперечных резцовых салазок 0,033-5,6 0,013-2,064 0,010-1,76
Пределы шаговыхрезьб:
метрических, мм 1-224
дюймовых, ниток/дюйм 28-0,25
модульных, модуль 0,25-56
питчевых, питч диам. 112-0,5
112-0,5
Наибольший вес устанавливаемой заготовки в центрах , кг 2000
Мощность главного привода, кВт 15
Габаритные размеры, мм:
Длина 10190
ширина 1 780
высота 1 650
Создано 10.11.2016 Изменено 24.04.2017
Токарный станок бу
Токарный по металлу БУ
Бу токарно-винторезные
Станки по металлу
1к62
Металлообрабатывающие станки
Похожие объявления
Токарно-винторезный станок модели 165
Состояние: Новый Производитель: Рязанский станкостроительный завод (Россия)
В наличии
Снежинск (Челябинская обл.) (Россия)
450 000
токарно-винторезный станок ДИП-300 (163, 1м63)
Состояние: Б/У Год выпуска: 1990 Производитель: токарно-винторезный станок ДИП300 (163, 1М63)
Санкт-Петербург (Россия)
Интересные статьи партнеров
Пусконаладка пресса для горячего прессования STP-120T1-3000 в Твери
Идея для лазерной гравировки: Уникальные скалки с трафаретами
Что будет если окунуть сверло в краску и раскрутить
Станок для резки пенопласта своими руками
ЧПУ нестинг: подробное объяснение процесса
Что нужно знать при покупке шпинделя для токарного станка?
12 способов нанести текстуру на древесину подручными инструментами
Прорыв в аддитивном производстве: меняющие цвет чернила для 3D принтера
Возможности 3D принтеров: 2-ух этажный дом, миллиметровая статуя Давида и веганский стейк
Вы недавно смотрели
Все просмотренные объявления →
Описание типов моделей машинного обучения
Модель машинного обучения — это программа, которая используется для прогнозирования заданного набора данных. Модель машинного обучения строится с помощью контролируемого алгоритма машинного обучения и использует вычислительные методы для «изучения» информации непосредственно из данных, не полагаясь на заранее определенное уравнение. В частности, алгоритм берет известный набор входных данных и известные ответы на данные (выходные данные) и обучает модель машинного обучения генерировать разумные прогнозы для ответа на новые данные.
Модель машинного обучения строится с помощью контролируемого алгоритма машинного обучения и использует вычислительные методы для «изучения» информации непосредственно из данных, не полагаясь на заранее определенное уравнение. В частности, алгоритм берет известный набор входных данных и известные ответы на данные (выходные данные) и обучает модель машинного обучения генерировать разумные прогнозы для ответа на новые данные.
Типы моделей машинного обучения
Существует два основных типа моделей машинного обучения: классификация машинного обучения (где ответ принадлежит набору классов) и регрессия машинного обучения (где ответ является непрерывным).
Выбор правильной модели машинного обучения может показаться сложным — существуют десятки моделей классификации и регрессии, каждая из которых использует свой подход к обучению. Этот процесс требует оценки компромиссов, таких как скорость, точность и сложность модели, и может включать пробы и ошибки.
Ниже приведен обзор моделей машинного обучения с классификацией и регрессией, который поможет вам начать работу.
Популярные модели машинного обучения для регрессии
| Модель | Изображение | Как это работает | Функция MATLAB | Примеры и инструкции |
|---|---|---|---|---|
| Линейная регрессия | Линейная регрессия — это метод статистического моделирования, используемый для описания переменной непрерывного отклика как линейной функции одной или нескольких переменных-предикторов. Поскольку модели линейной регрессии легко интерпретировать и легко обучать, они часто являются первыми моделями, которые адаптируются к новому набору данных. | ФитЛМ | Что такое модель линейной регрессии? — Документация Подгонка модели машинного обучения линейной регрессии — Пример кода | |
| Нелинейная регрессия | Нелинейная регрессия — это метод статистического моделирования, который помогает описать нелинейные отношения в экспериментальных данных. «Нелинейный» относится к функции подбора, которая является нелинейной функцией параметров. Например, если параметрами подбора являются b0, b1 и b2: уравнение y = b 0 +b 1 x+b 2 x 2 является линейной функцией параметров подбора, тогда как y = (b 0 x b1 )/(x+b 2 ) является нелинейной функцией подгоночных параметров. | фитнлм | Нелинейная регрессия — Документация Подгонка модели машинного обучения нелинейной регрессии — пример кода | |
| Регрессия гауссовского процесса (GPR) | Модели GPR — это непараметрические модели машинного обучения, которые используются для прогнозирования значения переменной непрерывного отклика. Переменная отклика моделируется как гауссовский процесс с использованием ковариаций с входными переменными. Эти модели широко используются в области пространственного анализа для интерполяции при наличии неопределенности. Георадар также называют Кригингом. | фитргп | Регрессионные модели гауссовского процесса — документация Подгонка модели машинного обучения гауссовского процесса — пример кода | |
| Метод опорных векторов (SVM) Регрессия | SVM работают так же, как алгоритмы классификации SVM, но модифицированы, чтобы иметь возможность прогнозировать непрерывный отклик. Вместо поиска гиперплоскости, разделяющей данные, алгоритмы регрессии SVM находят модель, которая отклоняется от измеренных данных не более чем на небольшую величину, с минимально возможными значениями параметров (чтобы свести к минимуму чувствительность к ошибкам). | фитрвм | Понимание регрессии метода опорных векторов — документация Подгонка модели машинного обучения SVM — пример кода | |
| Обобщенная линейная модель | Обобщенная линейная модель (GLM) — это частный случай нелинейных моделей, в котором используются линейные методы. Он включает в себя подгонку линейной комбинации входов к нелинейной функции (функции связи) выходов. Модель логистической регрессии является примером GLM. Он включает в себя подгонку линейной комбинации входов к нелинейной функции (функции связи) выходов. Модель логистической регрессии является примером GLM. | фитинг | Обобщенные линейные модели — Документация Подгонка обобщенной линейной модели — Пример кода | |
| Дерево регрессии | Деревья решений для регрессии аналогичны деревьям решений для классификации, но они изменены, чтобы иметь возможность прогнозировать непрерывные ответы. | фитртри | Растущие деревья решений — Документация Подгонка модели машинного обучения дерева регрессии — пример кода | |
| Генеративно-аддитивная модель (GAM) | GAM объясняют переменную отклика с помощью суммы одномерных и двумерных функций формы предикторов. Они используют усиленное дерево в качестве функции формы для каждого предиктора и, необязательно, каждой пары предикторов; следовательно, функция может фиксировать нелинейную связь между предиктором и переменной отклика. | фитргам | Обобщенная аддитивная модель — документация Обучение обобщенной аддитивной модели для регрессии — пример кода | |
| Нейронная сеть (мелкая) | Вдохновленная человеческим мозгом, нейронная сеть состоит из сильно связанных сетей нейронов, которые связывают входные данные с желаемыми выходными данными. Сеть обучается путем итеративного изменения сильных сторон соединений, чтобы входные данные обучения соответствовали ответам обучения. | фитрнет | Архитектуры нейронных сетей — документация Подгонка модели машинного обучения нейронной сети — пример кода | |
| Нейронная сеть (глубокая) | Глубокие нейронные сети имеют больше скрытых слоев, чем поверхностные нейронные сети, а в некоторых случаях даже сотни скрытых слоев. Глубокие нейронные сети можно настроить для решения задач регрессии, поместив выходной слой регрессии в конец сети. | сеть поездов | Глубокое обучение в MATLAB — документация Настройка глубокой нейронной сети для регрессии — пример кода | |
| Ансамбли деревьев регрессии | В ансамблевых методах несколько «более слабых» деревьев регрессии объединяются в «более сильный» ансамбль. Окончательная модель использует комбинацию прогнозов из «более слабых» деревьев регрессии для расчета окончательного прогноза. | фитренсборбль | Алгоритмы ансамбля — документация Подгонка модели машинного обучения ансамбля дерева регрессии — пример кода |
 Обычно предполагается, что модели нелинейной регрессии являются параметрическими, где модель описывается как нелинейное уравнение.
Обычно предполагается, что модели нелинейной регрессии являются параметрическими, где модель описывается как нелинейное уравнение.
Популярные модели машинного обучения для классификации
| Модель | Изображение | Как это работает | Функция MATLAB | Дополнительное чтение |
|---|---|---|---|---|
| Дерево решений | Дерево решений позволяет прогнозировать реакцию на данные, следуя решениям в дереве от корня (начала) до конечного узла. Дерево состоит из условий ветвления, в которых значение предиктора сравнивается с обученным весом. Количество ветвей и значения весов определяются в процессе обучения. Для упрощения модели можно использовать дополнительную модификацию или сокращение. Дерево состоит из условий ветвления, в которых значение предиктора сравнивается с обученным весом. Количество ветвей и значения весов определяются в процессе обучения. Для упрощения модели можно использовать дополнительную модификацию или сокращение. | фитингтри | Растущие деревья решений — Документация Подгонка модели машинного обучения дерева решений — пример кода | |
| k — Ближайший сосед (KNN) | KNN — это тип модели машинного обучения, которая классифицирует объекты на основе классов их ближайших соседей в наборе данных. Прогнозы KNN предполагают, что объекты рядом друг с другом похожи. Для нахождения ближайшего соседа используются метрики расстояния, такие как евклидово, квартальный, косинусный и чебышевский. | фитскнн | Классификация с использованием ближайших соседей. Документация | |
| Метод опорных векторов (SVM) | SVM классифицирует данные, находя линейную границу решения (гиперплоскость), которая отделяет все точки данных одного класса от точек данных другого класса. Лучшая гиперплоскость для SVM — это та, у которой самый большой разрыв между двумя классами, когда данные линейно разделимы. Если данные не являются линейно разделимыми, функция потерь используется для штрафа за точки на неправильной стороне гиперплоскости. SVM иногда используют преобразование ядра для преобразования нелинейно разделяемых данных в более высокие измерения, где можно найти линейную границу решения. Лучшая гиперплоскость для SVM — это та, у которой самый большой разрыв между двумя классами, когда данные линейно разделимы. Если данные не являются линейно разделимыми, функция потерь используется для штрафа за точки на неправильной стороне гиперплоскости. SVM иногда используют преобразование ядра для преобразования нелинейно разделяемых данных в более высокие измерения, где можно найти линейную границу решения. | фитцвм | Машины опорных векторов для двоичной классификации — документация Пример кода модели машинного обучения SVM | |
| Генеративно-аддитивная модель (GAM) | GAM объясняют баллы класса, используя сумму одномерных и двумерных функций формы предикторов. Они используют усиленное дерево в качестве функции формы для каждого предиктора и, необязательно, каждой пары предикторов; следовательно, функция может фиксировать нелинейную связь между предиктором и переменной отклика. | фитчгам | Обобщенная аддитивная модель — документация Обучение обобщенной аддитивной модели для бинарной классификации — пример кода | |
| Нейронная сеть (неглубокая) | Вдохновленная человеческим мозгом, нейронная сеть состоит из сильно связанных сетей нейронов, которые связывают входные данные с желаемыми выходными данными. Модель машинного обучения обучается путем итеративного изменения сильных сторон соединений, чтобы заданные входные данные соответствовали правильному ответу. Говорят, что нейроны между входным и выходным слоями нейронной сети находятся в «скрытых слоях». Неглубокие нейронные сети обычно имеют от одного до двух скрытых слоев. | фитнет | Архитектуры нейронных сетей — документация Подгонка модели машинного обучения для неглубоких нейронных сетей — пример кода | |
| Нейронная сеть (глубокая) | Глубокие нейронные сети имеют больше скрытых слоев, чем поверхностные нейронные сети, а в некоторых случаях даже сотни скрытых слоев. Глубокие нейронные сети можно настроить для решения задач классификации, поместив выходной слой классификации в конец сети. Многие предварительно обученные модели глубокого обучения для классификации общедоступны для таких задач, как распознавание изображений. Глубокие нейронные сети можно настроить для решения задач классификации, поместив выходной слой классификации в конец сети. Многие предварительно обученные модели глубокого обучения для классификации общедоступны для таких задач, как распознавание изображений. | сеть поездов | Глубокое обучение в MATLAB — документация Подгонка модели классификации глубокой нейронной сети — пример кода | |
| Деревья решений с пакетированием и ускорением | В этих ансамблевых методах несколько «более слабых» деревьев решений объединяются в «более сильный» ансамбль. Дерево решений в пакете состоит из деревьев, которые обучаются независимо на данных, загружаемых из входных данных. Повышение включает в себя создание сильного ученика путем итеративного добавления «слабых» учеников и корректировки веса каждого «слабого» ученика, чтобы сосредоточиться на неправильно классифицированных примерах. | монтажная сборка | Алгоритмы ансамбля — документация Подбор усиленного ансамбля деревьев решений — пример кода | |
| Наивный Байес | Наивный байесовский классификатор предполагает, что наличие определенного признака в классе не связано с наличием какого-либо другого признака. Он классифицирует новые данные на основе наибольшей вероятности их принадлежности к тому или иному классу. | фитцнб | Наивная байесовская классификация — документация Подгонка модели наивного байесовского машинного обучения — пример кода | |
| Дискриминантный анализ | Дискриминантный анализ классифицирует данные, находя линейные комбинации признаков. Дискриминантный анализ предполагает, что разные классы генерируют данные на основе распределений Гаусса. Обучение модели дискриминантного анализа включает в себя поиск параметров распределения Гаусса для каждого класса. Параметры распределения используются для расчета границ, которые могут быть линейными или квадратичными функциями. Эти границы используются для определения класса новых данных. Параметры распределения используются для расчета границ, которые могут быть линейными или квадратичными функциями. Эти границы используются для определения класса новых данных. | фиткдиск | Создание модели дискриминантного анализа — документация Подгонка модели машинного обучения дискриминантного анализа — пример кода |

См. также:
что такое линейная регрессия?,
нелинейная регрессия,
машина опорных векторов (SVM),
сверточная нейронная сеть,
сети с долговременной кратковременной памятью (LSTM),
контролируемое обучение
История вопроса: что такое генеративная модель? | Машинное обучение
Что означает «генеративный» в названии «генеративно-состязательная сеть»?
« Генеративный » описывает класс статистических моделей, который контрастирует с
дискриминационные модели .
Неофициально:
- Генеративные модели могут генерировать новые экземпляры данных.

- Дискриминативные модели различают разные виды данных
экземпляры.
Генеративная модель может генерировать новые фотографии животных, которые выглядят как настоящие
животных, тогда как дискриминационная модель могла бы отличить собаку от кошки. GAN являются
только один вид генеративной модели.
Более формально, учитывая набор экземпляров данных X и набор меток Y:
- Генеративные модели фиксируют совместную вероятность p(X, Y) или просто
p(X), если меток нет. - Дискриминативные модели фиксируют условную вероятность p(Y | X).
Генеративная модель включает в себя распределение самих данных и сообщает вам
насколько вероятен данный пример. Например, модели, которые предсказывают следующее слово в
последовательность обычно представляет собой генеративные модели (обычно намного проще, чем GAN)
потому что они могут присвоить вероятность последовательности слов.
Дискриминационная модель игнорирует вопрос о том, является ли данный экземпляр
скорее всего, и просто говорит вам, насколько вероятно, что метка будет применена к
экземпляр.
Обратите внимание, что это очень общее определение. Существует множество видов генеративных
модель. GAN — это всего лишь один из видов генеративной модели.
Вероятности моделирования
Ни одна из моделей не должна возвращать число, представляющее
вероятность. Вы можете моделировать распределение данных, имитируя
распределение.
Например, дискриминационный классификатор, такой как решение
дерево может помечать экземпляр
без присвоения вероятности этой метке. Такой классификатор по-прежнему будет
модель, потому что распределение всех предсказанных меток будет моделировать реальную
распределение меток в данных.
Точно так же генеративная модель может моделировать распределение, производя убедительные
«поддельные» данные, которые выглядят так, как будто они взяты из этого дистрибутива.
Генеративные модели сложны
Генеративные модели решают более сложную задачу, чем аналогичные дискриминационные
модели. Генеративные модели должны модели больше .
Генеративные модели должны модели больше .
Генеративная модель изображений может фиксировать корреляции, такие как «вещи, которые
похоже, что лодки, вероятно, появятся рядом с вещами, похожими на воду».
и «глаза вряд ли появятся на лбу». Это очень
сложные дистрибутивы.
Напротив, дискриминативная модель могла бы изучить разницу между
«парусник» или «не парусник», просто ища несколько контрольных моделей. Это
может игнорировать многие корреляции, которые генеративная модель должна получить правильно.
Дискриминативные модели пытаются провести границы в пространстве данных, в то время как генеративные
модели пытаются моделировать размещение данных в пространстве. Например,
На следующей диаграмме показаны дискриминационные и генеративные модели рукописного ввода.
цифры:
Рисунок 1: Дискриминационная и генеративная модели рукописных цифр.
Дискриминационная модель пытается определить разницу между написанными от руки нулями
и 1, нарисовав линию в пространстве данных.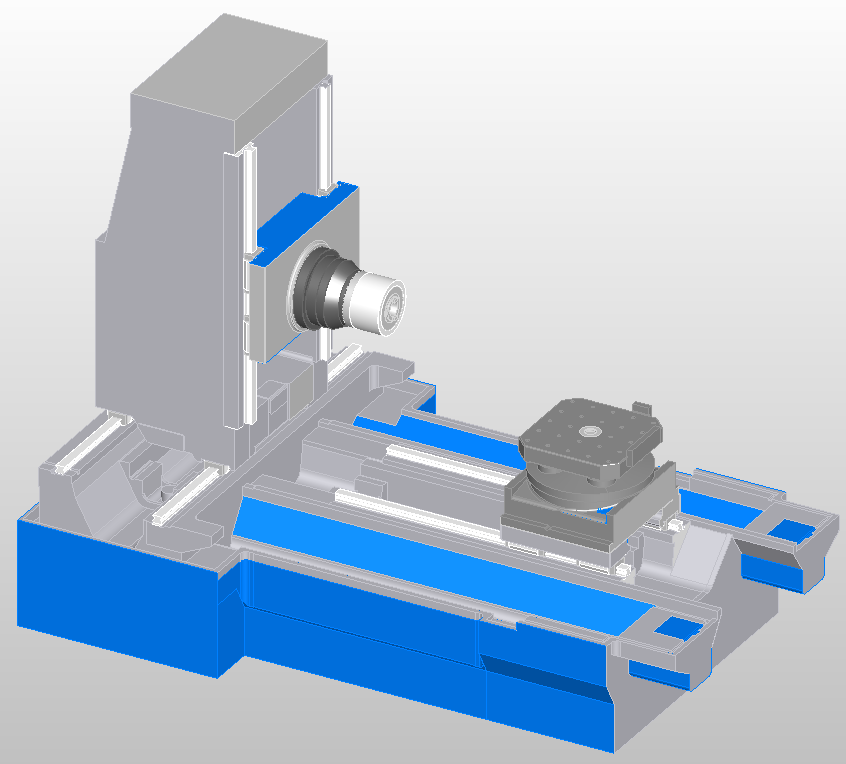 Если он получает линию правильно, он может
Если он получает линию правильно, он может
отличать 0 от 1, даже не моделируя, где именно
экземпляры размещаются в пространстве данных по обе стороны от линии.
Напротив, генеративная модель пытается производить убедительные единицы и нули
генерируя цифры, близкие к их реальным аналогам в данных
Космос. Он должен моделировать распределение по всему пространству данных.
GAN предлагают эффективный способ обучения таких богатых моделей, чтобы они походили на настоящие
распределение. Чтобы понять, как они работают, нам нужно понять основные
структура ГАН.
Проверьте свое понимание: Генеративный и генеративный
Дискриминативные модели
У вас есть IQ на 1000 человек. Вы моделируете распределение показателей IQ
со следующей процедурой:
- Бросьте три шестигранных кубика.
- Умножить бросок на константу w.

- Повторить 100 раз и взять среднее значение всех результатов.
Вы пробуете разные значения для w, пока результат вашей процедуры не будет равен
средний показатель реального IQ. Ваш
моделировать генеративную модель или дискриминативную модель?
Генеративная модель
Правильно: с каждым броском вы эффективно генерируете IQ
воображаемый человек. Кроме того, ваша генеративная модель фиксирует
тот факт, что показатели IQ распределяются нормально (то есть по кривой нормального распределения).
Дискриминационная модель
Неверно: аналогичная дискриминационная модель попыталась бы различить
между различными видами показателей IQ. За
Например, дискриминационная модель может попытаться классифицировать IQ как фальшивый или
настоящий.
Недостаточно информации.
Эта модель действительно подходит под определение одного из двух наших видов
модели.
