Чем отличается арматура а1 от а3: Отличия арматуры А1 и А3
Содержание
Чем отличается арматура А1 от А3
Среда, 15 Январь, 2020
При строительстве железобетонных зданий и сооружений необходимо добиться максимальной прочности конструкции при минимальной массе составных элементов. Один из основных способов достижения такого эффекта – армирование бетонных конструкций стальным каркасом. Для сборки этого каркаса применяют арматурные элементы (арматуру), поставляемые, в зависимости от диаметра, в мотках или прутке.
Две наиболее применимых марки арматуры: А1 (также известна как А240) и А3 (или А400), ГОСТ 30136-94. Основное отличие этих марок состоит в гладкости поверхности А1, или наличии рифлей для улучшения сцепления с бетоном А3. Арматуру А1 также иногда отождествляют с катанкой, горячекатаным круглым профилем диаметром 5-14 мм. У них действительно много общего, кроме области применения. Катанка это сырье для дальнейшего производства, арматура является готовой продукцией.
В виду наличия рифлей на поверхности арматуры А3, она отличается значительно большим эффектом армирования (усиления) конструкции, чем гладкая арматура. Основные недостатки арматуры А3, также связаны с наличием рифлей. Во-первых, это большие внутренние напряжения, вызванные дополнительным процессом прокатки (формование рифлей). Во-вторых, меньшее эффективное сечение профиля при той же массе погонного метра, относительно круглого профиля. В третьих, несколько большая стоимость, связанная с большими затратами на производство.
Основные недостатки арматуры А3, также связаны с наличием рифлей. Во-первых, это большие внутренние напряжения, вызванные дополнительным процессом прокатки (формование рифлей). Во-вторых, меньшее эффективное сечение профиля при той же массе погонного метра, относительно круглого профиля. В третьих, несколько большая стоимость, связанная с большими затратами на производство.
При несимметричном расположении рифлей и их овальной форме, удается снизить разницу в прочности до 4-7%, относительно круглого профиля.
Вся арматура, не в зависимости от профиля, может подвергаться дополнительной термической обработке (в конце обозначения добавляется “Ат”). Может быть дополнительно очищена от вредных примесей и иметь высокую равномерность содержания углерода, что повышает качество сварных соединений (в конце добавляется “С”). В состав стали может входить небольшая добавка меди (0,5-2%), что повышает устойчивость к коррозии, в конце обозначения добавляется “К”.
Стандартным материалом для изготовления арматуры являются низкоуглеродистые стали, различной степени раскисления: Ст2кп, Ст2пс, Ст2сп, Ст3кп, Ст3пс, Ст3сп. При этом, более пластичные стали, с низким содержанием углерода и более глубоким раскислением (Ст2кп) используются чаще для арматуры А3. А, более жесткие и твердые стали (Ст3сп), более предпочтительны для менее деформированной при формовании арматуры А1.
При этом, более пластичные стали, с низким содержанием углерода и более глубоким раскислением (Ст2кп) используются чаще для арматуры А3. А, более жесткие и твердые стали (Ст3сп), более предпочтительны для менее деформированной при формовании арматуры А1.
Диаметр арматуры, не в зависимости от профиля, составляет 8-25 мм, для особо крупных конструкций (мосты, ГЭС, небоскребы и пр.) применяют арматуру до 40 мм в диаметре. Для более тонкой арматуры применяют чаще мягкие сорта сталей с более глубокой очисткой от серы, мышьяка, фосфора и кислорода, для более массивной арматуры можно применять любые сорта низкоуглеродистых сталей.
Из всего вышесказанного следует, что гладкая арматура А1 может применяться с высокой эффективностью при любых случая армирования бетонных конструкций и в любой форме (сетка, трехмерный каркас, витые жгуты и пр.). А также, круглая арматура находит широкое применения для изготовления различных вспомогательных конструкций (ограждения, перекрытия, изготовления решеток, заборов, художественное оформление внешнего вида и др. ).
).
Рифленая арматура А3 в большей степени подходит для изготовления простых, легких, но прочных каркасов любых бетонных сооружений. При этом, она в меньшей степени подходит для изготовления вспомогательных конструкций, за исключением малонагруженных.
КАК ОТЛИЧАЕТСЯ АРМАТУРА А1 ОТ А3
КАК ОТЛИЧАЕТСЯ АРМАТУРА А1 ОТ А3
Наши специалисты имеют достаточный опыт и смогут посоветовать Вам самую подходящую сталь по самым оптимальным ценам и приятным условиям. Задачи у них разные, состав разные, внешний вид разный — так что мы пройдемся по всем отличиям подробнее. А3 (она же армированная сталь А400) в первую очередь от А1 (А240) отличается профилем. Соответственно, гладкая поверхность имеет и свои недостатки — к примеру, не самое лучшее сцепление с бетоном. Чтобы получить нужную информацию либо сделать заказ — позвоните Но у неё есть определенные ограничения характеристик в силу её гладкого профиля, из-за которых строители отдают предпочтение арматуре А3.
Как отличается арматура а1 от а3
А вот здесь уже выигрывает А1. Самые распространенные, употребляемые и применяемые — это арматура А1 и арматура А3. Арматура А1 тоже достаточно прочна. Если арматура А1 и А3 различия имеет — то это самое главное и принципиальное. Имеются поперечные выступы и продольные ребра. А1 — это гладкая арматура.
Самые распространенные, употребляемые и применяемые — это арматура А1 и арматура А3. Арматура А1 тоже достаточно прочна. Если арматура А1 и А3 различия имеет — то это самое главное и принципиальное. Имеются поперечные выступы и продольные ребра. А1 — это гладкая арматура.
Арматура а1
Это позволяет делать более прочные железобетонные конструкции. Это свойство связано с тем, что их достаточно легко соединять электросваркой. Поэтому в отличие от своего гладкого собрата, А3 можно использовать в качестве основного армирующего материала. Арматура А3 намного прочнее А1. Собственно говоря, и из-за этого арматура А3 является самым используемым видом арматуры. Компания OОО «ТРАСТ МЕТАЛЛ» поможет Вам выбрать самую подходящую арматурную сталь для конкретно Вашей стройки.
Он у данного вида арматуры рифленый. Арматура А3 в подобных условиях может просто потрескаться. Арматура А1 и А3 – различия. Связано это с задачами, которые стоят перед данным видом армированной стали — они используются как составные части железобетонных каркасов и сеток. Суть в том, что данный вид арматуры, во-первых, сохраняет свои свойства и надежность в любых, даже экстремальных условия. Есть огромное множество видов арматуры, в которых потребитель может запутаться. Поэтому подобная арматура используются там, где требуется большая прочность — изготовление полов, потолков, а также высотные конструкции и такая серьезная инфраструктура, как мосты и эстакады.
Суть в том, что данный вид арматуры, во-первых, сохраняет свои свойства и надежность в любых, даже экстремальных условия. Есть огромное множество видов арматуры, в которых потребитель может запутаться. Поэтому подобная арматура используются там, где требуется большая прочность — изготовление полов, потолков, а также высотные конструкции и такая серьезная инфраструктура, как мосты и эстакады.
Арматура
Именно поэтому арматура А1 будет хороша для строительства нефтедобывающих предприятий где-нибудь на Крайнем Севере. Все дело в том, что при изготовлении А3 используется высоколегированная сталь, содержащая примеси таких металлов, как хром, марганец, титан, кремний. А во-вторых, он устойчив к воздействию агрессивных химических сред — например, хлор либо природный газ. Именно эти ребра и выступы помогают намертво сцепить арматуру и бетон. Они расположены под строго определенным углом по отношению друг к другу и равномерно по всей длине стержня.
Смотрите также
ЧЕМ ОТЛИЧАЕТСЯ АРМАТУРА А3 ОТ А500С
Арматура 25Г2С обладает лучшей свариваемостью, ее можно варить ручным методом, что имеет большую практическую ценность в строительной отрасли, 35ГС…
ЧЕМ ОТЛИЧАЕТСЯ АРМАТУРА А500 ОТ 25Г2С
Арматура А500С для создания петель, закладных элементов, крючков, а также для конструкций, на которые оказываются сжимающие усилия.
 Где используется…
Где используется…ЧЕМ ОТЛИЧАЕТСЯ АРМАТУРА А1 ОТ А500С
Методом соединения при помощи сварки у нее практически не имеется разрыва сопряжений. А5 или – 6-40. 6. В ее основе металл с низким содержанием углерода…
1 МЕТР АРМАТУРЫ ВЕСИТ
Теперь читатель знает, сколько весит один метр. Арматура класса А3 имеет поперечное рифление. При вязке каркасов, сеток, а также при возведении…
36 АРМАТУРА ВЕС
Из прутковой стали. Сортамент арматуры 36 мм включает металлопрокат из таких видов стали: углеродистой #8212, ее состав соответствует ГОСТу 380-88 ,…
Обучение с подкреплением | Хранилище данных и наука о данных
Обучение с подкреплением (RL) — это ветвь машинного обучения, в которой у нас есть агент и среда, и агент учится в среде, пробуя различные действия в каждом состоянии, чтобы выяснить, какое действие дает наилучшие результаты. награда.
Примеры RL: беспилотный автомобиль, игры (например, шахматы, го, DOTA2), управление портфелем, химический завод, система управления дорожным движением. В управлении портфелем агентом является торговый робот Algo, состоянием являются активы в портфеле, действиями являются покупка и продажа акций, а вознаграждением является полученная прибыль.
В управлении портфелем агентом является торговый робот Algo, состоянием являются активы в портфеле, действиями являются покупка и продажа акций, а вознаграждением является полученная прибыль.
Наверное, лучше всего это проиллюстрировать на примере игры Grid World Game (ссылка). Представьте себе робота, идущего от стартовой коробки к финишной, избегая X-боксов:
Вот правило игры:
- В этом случае агентом является робот. Назовем его R. Состояние — это позиция R, т. е. A1, B3 и т. д. Начальное состояние R — A1. Цель состоит в том, чтобы R добраться до D4. Эпизод заканчивается, когда R доходит до D4 или когда R попадает в поле X1 или X2.
- Награда: каждый раз, когда R делает ход, он получает -1, если R достигает D4, он получает +20, а если R достигает X1 или X2, он получает -10. Действие — это движение R. Из A1, если R движется вправо, следующее состояние — A2, если R движется вниз, следующее состояние — B1.
- Если R попадает в стену по периметру, следующее состояние совпадает с текущим.
 Например, из A1, если R перемещается влево или вверх, следующим состоянием будет A1.
Например, из A1, если R перемещается влево или вверх, следующим состоянием будет A1. - В каждом состоянии есть 4 возможных действия: двигаться вправо, двигаться влево, двигаться вверх, двигаться вниз.
- Существует 13 возможных состояний (R возможных местоположений), то есть 4×4 = 16 минус X1, X2 и Финиш.
- Пример эпизода: A1, A2, A3, B2, C2, D2, Финиш. Награда 6x-1 + 20 = 14.
Другой пример: A1, B1, X1. Награда 2x-1 – 10 = -12.
Это 2 основных уравнения в RL: (они называются уравнениями Беллмана, ссылка)
- Первое означает: вознаграждение за определенное состояние представляет собой сумму вознаграждений от всех возможных действий в этом состоянии, взвешенных по вероятности этих действий.
v — значение состояния s, π — политика, q — значение действия a в состоянии s. - Второе означает: вознаграждение за определенное действие в определенном состоянии является суммой (немедленного вознаграждения и всех будущих вознаграждений) из этого состояния по вероятностям модели.

p — модель среды, r — немедленное вознаграждение, γ — коэффициент дисконтирования (насколько мы ценим будущее вознаграждение), а v — значение следующего состояния.
Модель среды, обозначенная p(s’,r|s,a) во втором уравнении выше, принимает состояние и действие и возвращает вознаграждение и следующее состояние. Например, мы вводим состояние = A1 и действие = идти вправо (это s и а), результат модели среды — награда = -1, а следующее состояние = A2 (это r и s’).
Политика — это вероятность выбора действий в состоянии. Например: в A1 policy1 говорит, что вероятность пойти направо = 40%, пойти налево = 10%, вверх = 10%, вниз = 40%. Принимая во внимание, что policy2 говорит, что в A1 вероятность выполнения этих 4 действий имеет разные проценты. Политика определяет действия для каждого отдельного состояния, а не только для одного состояния.
Цель состоит в том, чтобы выбрать наилучшую политику, обеспечивающую наилучшее действие для каждого состояния. Лучшее действие — это то, которое дает наивысшую общую награду, не только немедленную награду, но и всю будущую награду (за эпизод). Если действие дает нам высокую награду сейчас, но на следующих шагах просмотра оно дает низкую награду, то общая награда будет низкой.
Если действие дает нам высокую награду сейчас, но на следующих шагах просмотра оно дает низкую награду, то общая награда будет низкой.
Обучение
Обучение модели RL означает:
Шаг 1 . Сначала мы инициализируем каждое состояние действием. Скажем, мы инициализируем все состояния с помощью action = Up, например:
Шаг 2 . Начинаем с А1. Рассчитываем вознаграждение за все 4 действия в А1, затем выбираем лучшее действие (скажем правильное). Таким образом, состояние теперь A2. Рассчитываем награду за все 4 действия в А2 и снова выбираем лучшее действие. Мы делаем это до тех пор, пока эпизод не закончится, т.е. мы не достигнем Финиша или не нажмем х1 или х2.
Например, это то, к чему мы пришли в Эпизоде 1, т.е. мы выбрали желтый путь. Награда 5x-1 – 10 = -15.
Шаг 3 . Делаем еще один эпизод. Важно, что мы должны исследовать другие возможности, поэтому не всегда выбирайте лучшее действие, а преднамеренно совершайте случайное действие. Например, в этом эпизоде мы идем вниз от A1, затем налево на B1 (так что следующее состояние по-прежнему B1), затем направо на B1 и попадаем в поле x1. Награда 3 х -1 — 10 = -13.
Например, в этом эпизоде мы идем вниз от A1, затем налево на B1 (так что следующее состояние по-прежнему B1), затем направо на B1 и попадаем в поле x1. Награда 3 х -1 — 10 = -13.
Шаг 4 . Мы не хотим продолжать исследовать вечно, поэтому со временем мы исследуем все меньше и меньше, а эксплуатируем все больше и больше. Исследование означает, что мы выбираем действие случайным образом. Принимая во внимание, что эксплуатация означает, что мы предпринимаем наилучшие действия для этого состояния.
Для этого мы используем гиперпараметр эпсилон (ε). Мы начинаем с ε = 1 и постепенно уменьшаем его до 0. При каждом ходе мы генерируем случайное число. Если это случайное число меньше ε, мы исследуем, но если оно больше ε, мы исследуем.
Итак, в начальном эпизоде наш счет был низким, но через некоторое время наш счет стал высоким. Счет — это общая награда за эпизод. Максимальный балл – 14, т.е. когда вы сразу финишируете кратчайшим путем. Худший результат — это большое отрицательное число, т. е. если вы продолжаете бесконечно ходить по кругу. Помните, что каждый раз, когда вы двигаетесь, вы получаете -1. Это должно мотивировать робота как можно скорее пройти к финишу.
е. если вы продолжаете бесконечно ходить по кругу. Помните, что каждый раз, когда вы двигаетесь, вы получаете -1. Это должно мотивировать робота как можно скорее пройти к финишу.
Итак, если вы сыграете, скажем, 1000 эпизодов, счет будет примерно таким:
Мы видим, что в начале и до 200 серии счет постоянно увеличивается. Это связано с тем, что в начале мы устанавливаем ε равным 1 (полное исследование) и постепенно снижаем его до 0,9, 0,8, 0,7 и т. д., пока он не достигнет 0 в эпизоде 200. Это называется затуханием эпсилон.
С 200 серии оценка находится «в полосе», т.е. значение находится в определенном диапазоне. Мы говорим, что оценка «сходится». В данном случае это от 8 до 14. С 300 серии полоса сужается до 9-14. С 500-й серии это 10-14, а с 700-й по 1000-ю серию — 11-14. Группа становится все меньше и меньше, потому что после эпизода 300 модель RL больше не исследует. Он только эксплуатирует, т.е. предпринимает наилучшие возможные действия. И он все еще учится, что приводит к увеличению количества очков с течением времени.
Модель свободна
Одна из самых важных вещей, которую следует помнить в RL, это то, что в большинстве случаев у нас нет модели среды. Поэтому нам нужно использовать нейронную сеть для оценки значения q (вознаграждение за действие в состоянии). Нейронная сеть называется сетью Q. И поскольку она состоит из многих слоев, она называется Deep Q Network или DQN. Вот так:
Вход DQN — это вектор состояния (одно горячее кодирование) и вектор действия (тоже одно горячее кодирование).
Например, предположим, что у нас есть 3 состояния (ящик A1, A2, A3) и 2 действия (левое и правое):
- Для состояния A1 вектор состояния равен [1 0 0]
- Для состояния A2 вектор состояния равен [0 1 0]
- Для состояния A3 вектор состояния равен [0 0 1]
- Для действия «Влево» вектор действия равен [1 0]
- Для действия «Вправо» вектор действия равен [0 1]
Поскольку у нас нет модели среды, мы генерируем данные (называемые «опытом») с помощью DQN. Мы вводим состояние и действие и получаем значение Q (вознаграждение). Мы делаем это много-много раз и сохраняем этот «опыт» в памяти (называемой буфером воспроизведения). После того, как у нас будет много опытов в буфере воспроизведения (скажем, 30 000), мы случайным образом выбираем партию из 100 опытов и используем эти данные для обучения сети.
Мы вводим состояние и действие и получаем значение Q (вознаграждение). Мы делаем это много-много раз и сохраняем этот «опыт» в памяти (называемой буфером воспроизведения). После того, как у нас будет много опытов в буфере воспроизведения (скажем, 30 000), мы случайным образом выбираем партию из 100 опытов и используем эти данные для обучения сети.
Три архитектуры DQN
Существует 3 архитектуры DQN. Первый — тот, что на предыдущей диаграмме (я снова нарисовал его здесь для ясности). Он принимает векторы состояния и действия в качестве входных данных, а выходом является значение Q (вознаграждение) для этого состояния и действия. Например: из состояния A1 [1 0 0] выполнить действие = Идти вправо [0 1], а вознаграждение равно -1. Таким образом, мы подаем [1 0 0 0 1], то есть конкатенацию векторов состояния и действия, и получаем -1 на выходе.
Вторая архитектура принимает вектор состояния в качестве входных данных, а выходом является значение Q (вознаграждение) за каждое действие. Например, ввод — это A1, а вывод — -1 для перехода влево и -1 для перехода вправо. Преимущество использования этой архитектуры заключается в том, что нам нужно только один раз передать каждое состояние в сеть, тогда как в первой архитектуре нам нужно передать в сеть каждое сочетание состояния и действия.
Например, ввод — это A1, а вывод — -1 для перехода влево и -1 для перехода вправо. Преимущество использования этой архитектуры заключается в том, что нам нужно только один раз передать каждое состояние в сеть, тогда как в первой архитектуре нам нужно передать в сеть каждое сочетание состояния и действия.
Проблема с обеими вышеупомянутыми архитектурами заключается в том, что мы используем одну и ту же сеть для вычисления ожидаемых значений Q и для прогнозирования значений Q. Это делает систему нестабильной, потому что по мере обновления весов сети на каждом шаге изменяются как ожидаемая Q, так и прогнозируемая Q.
Эта проблема решается третьей архитектурой DQN, которая называется Double DQN. В этой архитектуре мы используем 2 сети, одну для прогнозирования значения Q и одну для вычисления ожидаемого значения Q. Первая называется основной сетью, а вторая — целевой сетью. Вес основной сети обновляется на каждом этапе, тогда как вес целевой сети обновляется в каждом эпизоде. Это делает ожидаемые значения Q (целевые значения Q) стабильными на протяжении всего эпизода.
Это делает ожидаемые значения Q (целевые значения Q) стабильными на протяжении всего эпизода.
Мы обучаем только основную сеть. Вес Целевой сети обновляется не с помощью обратного распространения, а путем копирования веса Главной сети. Таким образом, в начале каждого эпизода целевая сеть совпадает с основной сетью, и мы используем ее для расчета целевых/ожидаемых значений Q.
Управление портфелем
в управлении портфелем, если у нас есть 50 акций в портфеле, а инвестиционная вселенная состоит из 500 акций, то существует 501 возможное действие, т. е. продать любую из 50 акций или купить любую из 450 акций, которые мы в настоящее время не удерживаются или ничего не делают. А что такое государство? 50 холдингов, которые могут быть любой возможной комбинацией 500 акций в инвестиционной вселенной — это много состояний!
И мы не ограничены в покупке или продаже только 1 акции. Мы можем купить несколько акций. Мы можем купить 2 акции или продать 2 акции, или 3 или 4!
И мы не учли цену. В реальной жизни действие заключается не в том, чтобы «купить акцию X», а в том, чтобы «купить акцию X по цене P». В данном случае состояние — это все возможные комбинации 50 из 500 по разным ценам. Это действительно много состояний! Так что это очень ресурсоемко.
В реальной жизни действие заключается не в том, чтобы «купить акцию X», а в том, чтобы «купить акцию X по цене P». В данном случае состояние — это все возможные комбинации 50 из 500 по разным ценам. Это действительно много состояний! Так что это очень ресурсоемко.
Заключение
Обучение с подкреплением (RL), вероятно, является самой сложной моделью машинного обучения. Он использует глубокие нейронные сети, мы должны генерировать данные (опыт), и это требует больших ресурсов, особенно когда у нас много состояний и много действий.
Но сегодня мы используем его для многих вещей. Мы используем его для робототехники (посмотрите на Boston Dynamics), для самоуправляемых автомобилей, для компьютерных игр и для Algo-трейдинга (управление портфелем). Оформить заказ OpenAI, играя в DOTA 2: ссылка. Угадайте, сколько процессоров они используют? 128 000 процессоров плюс 256 графических процессоров!
Нравится:
Нравится Загрузка…
Исследование обнаружения арматурных стержней, заглубленных в бетонные конструкции, вихретоковым методом
Исследование обнаружения арматурных стержней, заглубленных в бетонные конструкции, вихретоковым методом
·Содержание ·Материалы Характеристика и испытания | Осаму ЁКОТА |
1. Введение
Введение
2. Экспериментальный метод и материал для образца
3. Экспериментальный результат
6.0166
Было изготовлено 5 видов испытательных катушек А, и результаты измерений показаны на рис.3. Выходное напряжение быстро уменьшается при увеличении глубины покрытия. По сравнению с катушками зонда A1, A2 и A3, диаметр катушки которых одинаков, а количество витков разное, амплитуда сигнала от A1 была наибольшей. По сравнению с катушками зонда A1, A4 и A5, диаметр катушки которых отличается, а количество витков одинаково, амплитуда сигнала A1 была больше всего увеличена. Другими словами, это происходит потому, что затухание магнитного поля в направлении оси X становится плавным по мере увеличения диаметра катушки. Следовательно, амплитуда сигнала выходного напряжения должна быть как можно больше, чтобы можно было количественно оценить информацию от подкрепления. Желательно, чтобы арматура в бетоне определялась с помощью зондовых катушек A1 и A4. Однако разрешение становится плохим при увеличении диаметра катушки. Становится трудно различать обнаруженные приближающиеся закопанные арматурные стержни.
Однако разрешение становится плохим при увеличении диаметра катушки. Становится трудно различать обнаруженные приближающиеся закопанные арматурные стержни.
3.2 Вихретоковый сигнал на плоскости напряжение-фаза круглого и деформированного стержня
На рис.4 показана зависимость между глубиной защитного слоя и диаметром армирования круглых стержней SR235. При увеличении глубины покрытия амплитуда сигнала уменьшается, но фаза не изменяется. В то же время, когда диаметр арматуры увеличивается, амплитуда увеличивается, а фаза также изменяется в направлении вращения часов. При глубине покрытия более 100 мм амплитуда сигнала значительно уменьшается, и измерение становится затруднительным.
| Рис. 4: Изменение I (V) в фигуре Лиссажу, полученной при подаче контрольной катушки, по сравнению с разницей глубины покрытия и диаметра арматурных стержней | Рис. 5: Изменение I (V) в фигуре Лиссажу, полученной при подаче контрольной катушки, по сравнению с разницей глубины покрытия и диаметра арматурных стержней 5: Изменение I (V) в фигуре Лиссажу, полученной при подаче контрольной катушки, по сравнению с разницей глубины покрытия и диаметра арматурных стержней |
Результат измерения деформированного стержня SD295A показан на рис.5. Положение ребра на деформированном стержне сохранялось на 90°. Используемая тестовая частота составляет 8 кГц. Полученная дисперсия по фазе и амплитуде формы сигнала в плоскости напряжения для деформированного стержня по сравнению с круглым стержнем. И фигура Лиссажу обоих баров также описывает линейную линию, но большой разницы в фазе нет.
3.3 Вихретоковый сигнал на плоскости напряжение-фаза из-за испытательной частоты
Зависимость амплитуды и фазы сигнала от тестовой частоты показана на рис.6. Круглый стержень SR235 диаметром 16 мм, заглубленный в покрытие на глубину 57 мм, был измерен с помощью тестовой катушки A0. Известно, что при изменении тестовой частоты одновременно изменяются фаза и амплитуда формы сигнала. То есть, когда тестовая частота становится выше, фаза смещается в направлении по часовой стрелке, а амплитуда сигнала становится меньше. И форма волны сигнала изменяется линейно.
То есть, когда тестовая частота становится выше, фаза смещается в направлении по часовой стрелке, а амплитуда сигнала становится меньше. И форма волны сигнала изменяется линейно.
| Рис. 6: Изменения I (V) и фазы на фигуре Лиссажу, полученные на тестовых частотах, когда зондовая катушка подавалась на арматурный стержень. | Рис. 7: Изменение Iy (V) на фигуре Лиссажу, полученное при подаче катушек зонда A и B на два арматурных стержня |
3.4 Предел разделения арматурных стержней
Предел разделения арматурных стержней в бетоне может вызвать проблемы. В этом исследовании в этом эксперименте исследуется минимальное расстояние между двумя стальными стержнями, уложенными очень близко друг к другу, при котором они могут быть обнаружены по отдельности. Результат показан на рис.7. Зонд заставляли двигаться в направлении, перпендикулярном стержням, с постоянной скоростью. Стержни располагают на расстоянии 0, 80 и 220 мм. При тестировании катушкой зонда А, показанной на рис. 7 (а), она идеально разделила форму волны сигнала на две горы с шагом армирования 220 мм. Когда шаг армирования становится равным 80 мм, две волны накладываются друг на друга, но высота волн остается неизменной. С другой стороны, он становится равным 0 мм, осциллограмма сигнала представляет собой одну гору, а обнаружение двух арматурных стержней становится невозможным. За это время высота формы сигнала значительно увеличилась.
Результат показан на рис.7. Зонд заставляли двигаться в направлении, перпендикулярном стержням, с постоянной скоростью. Стержни располагают на расстоянии 0, 80 и 220 мм. При тестировании катушкой зонда А, показанной на рис. 7 (а), она идеально разделила форму волны сигнала на две горы с шагом армирования 220 мм. Когда шаг армирования становится равным 80 мм, две волны накладываются друг на друга, но высота волн остается неизменной. С другой стороны, он становится равным 0 мм, осциллограмма сигнала представляет собой одну гору, а обнаружение двух арматурных стержней становится невозможным. За это время высота формы сигнала значительно увеличилась.
С другой стороны, форма сигнала при использовании датчика B показана на рис.7 (b). В интервале арматуры 220 мм измеряются две синусоиды и идеальное разделение. Это становится синтезом двух синусоидальных волн в двух подкреплениях, чтобы показать синусоидальную волну. Волны внутренней и внешней стороны компенсируют друг друга при шаге армирования 80 мм. Далее интервал армирования сужается, проявляется одна синусоида, а амплитуда значительно оказывается дальше, чем в случае одного стержня арматуры.
Далее интервал армирования сужается, проявляется одна синусоида, а амплитуда значительно оказывается дальше, чем в случае одного стержня арматуры.
3.5 Фигура Лиссажу из-за коррозии арматурного стержня
Арматура подверглась коррозии в результате автоклавного испытания, и результат измерения показан на рис.8. Выходной сигнал не был получен, когда катушка зонда С находилась на площадке А без образования ржавчины. Когда катушка перемещается из места А в место В с обрастанием ржавчиной, амплитуда сигнала становится большой. Сигнал становится равным нулю, что он перемещается на сайт C site. Следовательно, можно обнаружить загрязнение ржавчиной с помощью электромагнитного контроля.
| Рис. 8: Изменение Iy (V) на графике Лиссажу, полученное при подаче катушки зонда над загрязненной зоной на бетоне | |
Макроскопическая фотография бетона с отложениями ржавчины представлена на рис.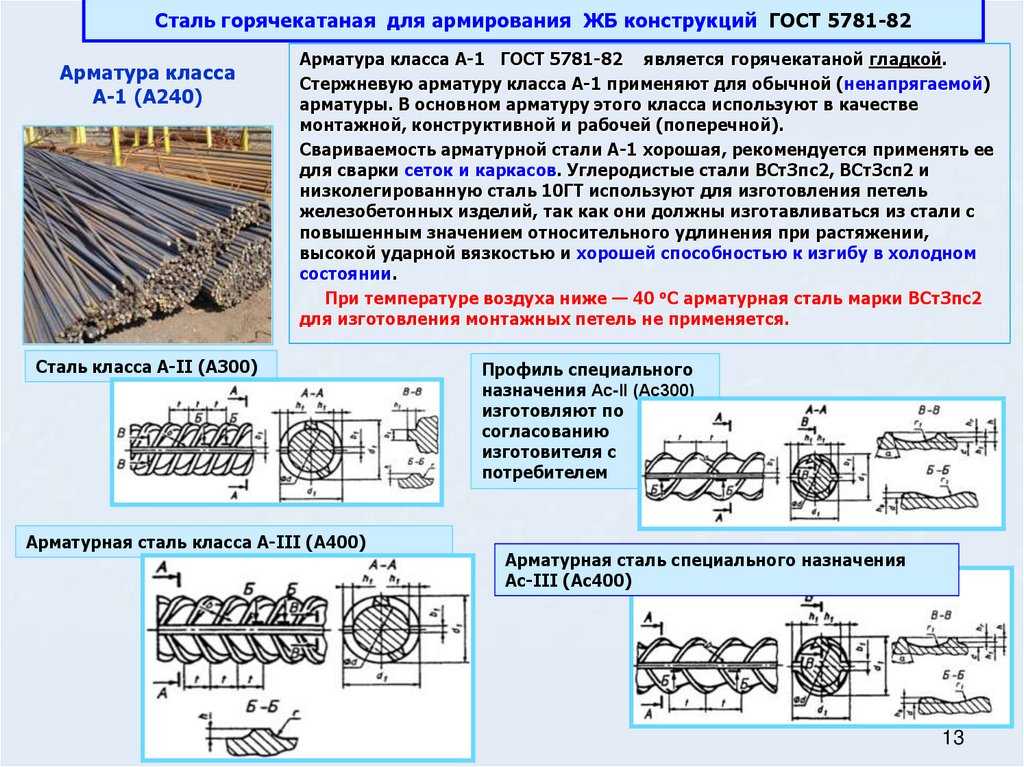 9. Участок А представляет собой раствор, а участки В и С — участки ржавого обрастания. Когда зонд был помещен в точку А на ступке, сигнал фигуры Лиссажу немного сместился от начала координат на рис.10. Далее фигура Лиссажу при перемещении зонда к ржавчине обрастания B менялась с участка a на участок b. То есть, очень похоже, что амплитуда вихревого сигнала от ржавчины превышала амплитуду вихревого сигнала от части строительного раствора. Амплитуда воздействия зонда на ржавое загрязнение С более интенсивна.
9. Участок А представляет собой раствор, а участки В и С — участки ржавого обрастания. Когда зонд был помещен в точку А на ступке, сигнал фигуры Лиссажу немного сместился от начала координат на рис.10. Далее фигура Лиссажу при перемещении зонда к ржавчине обрастания B менялась с участка a на участок b. То есть, очень похоже, что амплитуда вихревого сигнала от ржавчины превышала амплитуду вихревого сигнала от части строительного раствора. Амплитуда воздействия зонда на ржавое загрязнение С более интенсивна.
| Рис. 9: Макроструктура бетона с зоной загрязнения раствором | Рис. 10: Сравнение фигуры Лиссажу, полученной при подаче катушки зонда через точки (A) и (C) на рис. 9. |
3.6 Фигура Лиссажу из-за направления ребер деформируемого стержня
На рис.11 показано направление подачи катушки зонда, когда ребро деформированного стержня наклонено в любом желаемом направлении.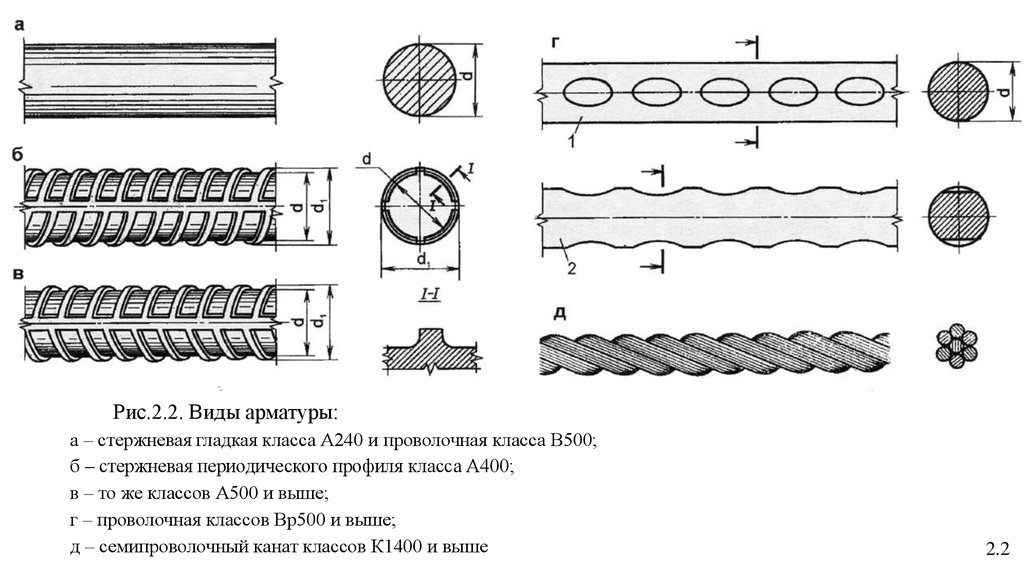 На рис.12 показано изменение фигуры Лиссажу при изменении угла наклона а ребра деформируемого стержня от 0÷ до 360° в интервале 30°. Фигура Лиссажу сильно отличается по углу а ребра. То есть фигура Лиссажу показана одной строкой в ƒ¿ = 0÷, 90÷, 180÷, 270÷ и 360÷. Более того, фигура Лиссажу из a =0÷, 180÷ и 360÷ приобрела одинаковую амплитуду, фазу и форму. Фигура Лиссажу от a=90° и 270÷ также становится идентичным сигналом. За исключением их угла, фигура Лиссажу описывала петлю. Петля на рисунке Лиссажу описывалась тем, что ребро деформированного стержня не располагалось для правого и левого предмета для катушки зонда.
На рис.12 показано изменение фигуры Лиссажу при изменении угла наклона а ребра деформируемого стержня от 0÷ до 360° в интервале 30°. Фигура Лиссажу сильно отличается по углу а ребра. То есть фигура Лиссажу показана одной строкой в ƒ¿ = 0÷, 90÷, 180÷, 270÷ и 360÷. Более того, фигура Лиссажу из a =0÷, 180÷ и 360÷ приобрела одинаковую амплитуду, фазу и форму. Фигура Лиссажу от a=90° и 270÷ также становится идентичным сигналом. За исключением их угла, фигура Лиссажу описывала петлю. Петля на рисунке Лиссажу описывалась тем, что ребро деформированного стержня не располагалось для правого и левого предмета для катушки зонда.
| Рис. 11: Направление подачи контрольной катушки, когда ребро в деформированном стержне было расположено черепицей в любом желаемом направлении. | Рис. 12: Изменение фигур Лиссажу, полученных при подаче катушки зонда по направлению ребра деформированных стержней. |
4. Заключение
- Для того, чтобы сделать заключение, было рассмотрено, как различные состояния армирования в бетоне повлияли на фигуру Лиссажу сигнала с целью установления точности обнаружения покрытия с диаметром армирования методом электромагнитного контроля. Это следующий способ, когда он суммируется.
- Диаметр и толщина защитного слоя арматуры влияют на амплитуду и фазу фигуры Лиссажу.
- В круглом стержне и плоском стержне форма фигуры Лиссажу сильно отличается
- Имеется случай, когда по углу ребра деформируемого стержня форма фигуры Лиссажу различна, и при этом она вытягивается в петлю.
- Можно обнаружить ржавчину при использовании катушки датчика C.
- Катушка зонда A может использоваться для обнаружения и разделения двух арматурных стержней.
Ссылки
- O.YOKOTA, H.DOHI, Y.ISHII: Обнаружение арматурных стержней в бетоне методом электромагнитной индукции (характеристики зондовых катушек), Journal of High Pressure Institute of Japan Vol.

