Классификация арматуры: Арматура — классификация и применение
Содержание
Арматура: виды и классификация — Карстон
Использование бетона для возведения зданий и сооружений различного назначения известно с давних времён. Некоторые исследователи считают, что этот материал использовался даже при строительстве знаменитых египетских пирамид. Однако бетон считается довольно хрупким и может быть разрушен под влиянием окружающей среды. По этой причине происходит его усиление за счёт использования металлических прутьев, композитных материалов, или арматуры. Для разных целей используются различные варианты армирования, которые мы далее рассмотрим.
Используемые в железобетонных конструкциях металлические прутья или композитные элементы различаются по используемому материалу, внешнему виду, расположению в бетонном монолите. Именно по этим критериям происходит разделение арматуры на различные типы и виды. Наибольшее распространение получила арматура на стальной основе, её отличает дешевизна и простота в изготовлении. Существует множество разновидностей подобных усиливающих бетон элементов. Но прежде чем рассказать об этом виде, коротко остановимся на композитном варианте.
Но прежде чем рассказать об этом виде, коротко остановимся на композитном варианте.
Особенности композитной арматуры
Эта разновидность сочетает в своей конструкции как стальные, так и пластиковые элементы. В зависимости от особенностей изготовления, в композитной арматуре могут быть использованы следующие типы искусственных волокон:
- Стеклопластиковые;
- Углепластиковые;
- Базальтопластиковые.
Это современный материал усиления бетонных конструкций, который появился лишь в конце прошлого века. Наиболее часто для создания композитной арматуры используются стеклопластиковые волокна. Основным преимуществом такого материала считается высокая прочность, которая в два с лишним раза превосходить сталь. Углепластиковые и базальтопластиковые волокна применяются для возведения объектов, часто испытывающих влияние неблагоприятной среды. Они способны длительное время противостоять вредному воздействию, а так же обладают высокой резистентностью к огню. Однако композитная арматура на основе таких волокон стоит гораздо дороже стальной, поэтому используется в строительстве довольно редко.
Однако композитная арматура на основе таких волокон стоит гораздо дороже стальной, поэтому используется в строительстве довольно редко.
Классификация и разновидности металлической арматуры
Несмотря на некоторые преимущества композитной основы, в большинстве случаев для усиления бетона используется металлическая арматура, прежде всего – стальная. Преимуществом таких усиливающих бетон конструкций считается простота в изготовлении, дешевизна используемых материалов, длительный срок эксплуатации. К тому же стальные материалы имеют универсальную область применения. Их можно использовать при проведении монтажных работ, при строительстве жилых или торговых комплексов. Большое значение имеет так же возможность применения стальной арматуры в промышленном строительстве. Она может различаться:
- По технологии изготовления;
- В зависимости от использования;
- По профильному рисунку;
- В зависимости от расположения в конструкции.
В зависимости от технологии изготовления стальные прутья могут быть холоднокатаными, горячекатаными или холоднодеформированными. Их легко можно различить по маркировке – литерой А обозначаются горячекатаные прутья, В – холоднодеформированные, К – катаные. По вариантам использования она может быть ненапрягаемой или напрягаемой. В простых конструкциях, не предполагающих значительные нагрузки, применяется арматура ненапрягаемого типа. Если же возводимое сооружение предполагает выдержку значительных нагрузок, в ход идёт напрягаемая разновидность. В зависимости от профильного рисунка армирующие материалы разделяются на гладкие или рифлёные, последние имеют наибольшее распространение. Металлические прутья могут по-разному располагаться в бетонных конструкциях – различается поперечное и продольное размещение.
Их легко можно различить по маркировке – литерой А обозначаются горячекатаные прутья, В – холоднодеформированные, К – катаные. По вариантам использования она может быть ненапрягаемой или напрягаемой. В простых конструкциях, не предполагающих значительные нагрузки, применяется арматура ненапрягаемого типа. Если же возводимое сооружение предполагает выдержку значительных нагрузок, в ход идёт напрягаемая разновидность. В зависимости от профильного рисунка армирующие материалы разделяются на гладкие или рифлёные, последние имеют наибольшее распространение. Металлические прутья могут по-разному располагаться в бетонных конструкциях – различается поперечное и продольное размещение.
Большое значение при выборе армирующих материалов имеет металл, из которого они изготовлены. Наибольшее распространение получили рифлёные прутья, изготовленные из стандартной низколегированной стали, относящиеся к классу А1 (сейчас маркировка постепенно заменяется на А240). К этой категории относится разновидностей, обладающих схожими эксплуатационными характеристиками, к примеру А5-АV-А600 или А3-АIII-А400. Более прочным вариантами считаются термически усиленные металлические прутья. Подобное усиление происходит за счёт процесса ускоренного охлаждения в процессе изготовления. Отличить такую разновидность армирующих материалов можно по маркировке, в которую входит литера Т. Примером может служить термическая арматура АТ600 или АТ1000. Усиливающие бетон элементы различаются также в зависимости от степени окисления и подразделяются на:
Более прочным вариантами считаются термически усиленные металлические прутья. Подобное усиление происходит за счёт процесса ускоренного охлаждения в процессе изготовления. Отличить такую разновидность армирующих материалов можно по маркировке, в которую входит литера Т. Примером может служить термическая арматура АТ600 или АТ1000. Усиливающие бетон элементы различаются также в зависимости от степени окисления и подразделяются на:
- Кипящие;
- Полуспокойные;
- Спокойные.
В соответствии с этим они получили обозначение КП, ПС, СП. Наиболее простым и дешёвым вариантом является арматура, изготовленная на основе кипящей стали. Процесс её изготовления проходит быстрее, но в процессе кипения металл теряет некоторые свои прочностные качества. Поэтому для зданий и сооружений, испытывающих значительные нагрузки, рекомендуется использовать конструкции с маркировкой СП, т.е. спокойные. Их производство занимает больше времени и стоят они гораздо дороже. Компромиссным вариантом может стать применения арматуры с полуспокойной степенью окисления.
Существует так же разделение на арматурные классы, от которых зависит область применения тех или иных металлических прутьев. Различается арматура монтажная, строительная и промышленная. Монтажная арматура относится к наиболее простой и распространённой категории и маркируется как А1 или А240. Материалы, обозначенные в разбросе от А200 до А400 относятся по классификации к строительным конструкциям. Именно они в основном используются при возведении жилых зданий или офисных центров. Для создания производственных помещений используется арматура более высоких, промышленных классов.
При обозначении особенностей тех или иных материалов могут быть использованы специальные обозначения. Так, литера С указывает на то, что это арматура, с которой можно проводить сварочные работы. Буква К означает, что конструкция имеет антикоррозийное покрытие.
Важное значение имеет и форма профиля, которой обладают металлические прутья. Кроме гладкого профиля различаются три основных разновидности рифлёной арматуры:
- Кольцевая;
- Серповидная;
- Смешанная.
До последнего времени практически все металлические прутья, используемые для усиления бетонных конструкций, имели профиль кольцевого типа. До сих пор такой вариант считается самым распространённым, его стандарты регулируются ГОСТ 57-81. В конце прошлого века в практике появляется европейский серповидный арматурный профиль. Он считается более эффективным в использовании, но его изготовление занимает больше времени. По этой причине на сегодняшний день всё большее распространение в строительстве получает арматурный профиль смешанного типа, сочетающий в себе элементы кольцевой и серповидной разновидности.
Классификация арматуры и технические требования к сталям
Классификация арматуры и технические требования к сталям
Классификация арматуры. Арматура железобетонных конструкций воспринимает в основном растягивающие усилия. Это дает возможность, применяя ее совместно с бетоном, изготовлять железобетонные конструкции разнообразного назначения.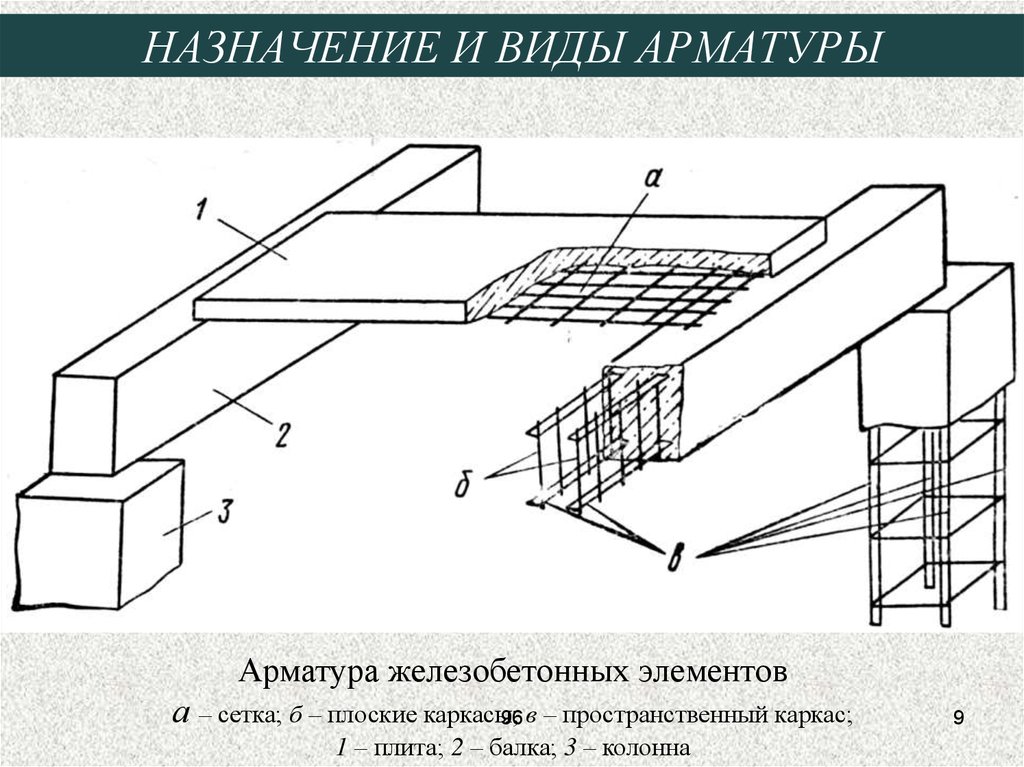 Из железобетона выполняют конструктивные элементы зданий и сооружений, работающие не только на сжатие, например колонны, но и на изгиб и растяжение — плиты, балки, фермы для перекрытия больших пролетов. Стальную арматуру классифицируют по назначению, способу изготовления и последующего упрочнения, форме поверхности и способу применения.
Из железобетона выполняют конструктивные элементы зданий и сооружений, работающие не только на сжатие, например колонны, но и на изгиб и растяжение — плиты, балки, фермы для перекрытия больших пролетов. Стальную арматуру классифицируют по назначению, способу изготовления и последующего упрочнения, форме поверхности и способу применения.
По назначению различают арматуру рабочую и монтажную. Рабочая арматура воспринимает усилия, возникающие под действием нагрузок на конструкцию. Количество арматуры рассчитывают в соответствии с этими нагрузками. В зависимости от ориентации в железобетонной конструкции рабочая арматура может быть продольной или поперечной.
Продольная рабочая арматура воспринимает усилия растяжения или сжатия, действующие по продольной оси элемента. Например, в изображенной на рис. 15 балке, опирающейся по концам, продольная рабочая арматура выполнена из стержней, которые сопротивляются растягивающим усилиям в нижней зоне конструкции. Для восприятия усилий, действующих при изгибе под углом 45° к продольной оси балки, стержни отгибают. В колоннах продольную арматуру устанавливают для повышения сопротивляемости усилиям сжатия.
В колоннах продольную арматуру устанавливают для повышения сопротивляемости усилиям сжатия.
Рис. 15. Армирование балки:
1 — распределительная арматура, 2, 3. 5 — продольные рабочие арматурные стержни, 4 — поперечная арматура (хомуты), 6 — монтажные петли
Поперечная арматура воспринимает усилия, действующие поперек оси балки. Такую арматуру выполняют в виде хомутов либо расположенных поперечно отрезков стержней в сварных каркасах и сетках.
Монтажную арматуру устанавливают в зависимости от конструктивных и технологических требований. Ее подразделяют на распределительную и конструктивную. Распределительная арматура позволяет закреплять рабочую арматуру в проектном положении. В этом важное технологическое значение распределительной арматуры. Кроме того, она служит для более равномерного распределения усилий между отдельными стержнями рабочей арматуры. Стерэкни рабочей и распределительной арматуры сваривают либо связывают в единый пространственный каркас или плоские сетки.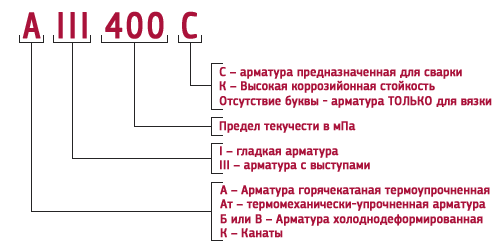 Иногда распределительную арматуру используют для тОго, чтобы придать арматурному каркасу необходимую жесткость.
Иногда распределительную арматуру используют для тОго, чтобы придать арматурному каркасу необходимую жесткость.
Конструктивная арматура служит для восприятия таких усилий, на которые конструкцию не рассчитывают. В частности, сюда относятся усилия от усадки бетона, температурных изменений. Конструктивную арматуру обязательно устанавливают в местах резкого изменения сечения конструкций, где происходит концентрация напряжений. Конструкции, подвергающиеся действию динамических нагрузок, например подкрановые балки и консоли колонн, на которые они опираются, также нуждаются в конструктивной арматуре.
По способу изготовления стальную арматуру железобетонных конструкций подразделяют на горячекатаную стержневую и холоднотянутую проволочную.
Стержневую арматуру поставляют в прутках диаметром не менее 12 мм и длиной до 13 м, проволочную диаметром З…8мм — в мотках или бунтах массой до 1300 кг.
По способу последующего упрочнения горячекатаная арматура может быть термически упрочненной, т. е. подвергнутой термической обработке, или упрочненной в холодном состоянии — вытяжкой, волочением.
е. подвергнутой термической обработке, или упрочненной в холодном состоянии — вытяжкой, волочением.
По форме поверхности различают арматуру периодического профиля и гладкую. Стержни арматуры периодического профиля снабжены выступами, благодаря которым улучшается сцепление ее с бетоном. На поверхности проволочной арматуры для этой цели создают рифы (вмятины). Гладкую арматуру выпускают в виде горячекатаных стержней диаметром 6…40 мм или проволоки диаметром 3…8 мм. Чтобы исключить проскальзывание гладкой арматуры в бетоне, ее заанкери-вают.
По способу применения при армировании железобетонных конструкций различают напрягаемую арматуру, подвергаемую предварительному натяжению, и ненапрягаемую.
В некоторых случаях используют так называемую жесткую арматуру в отличие от обычно применяемых гибких стержней и проволоки. Жесткую арматуру выполняют из сортового проката — швеллеров, двутавров, равнобоких и неравнобоких уголков. До отвердевания бетона такая арматура работает как металлическая конструкция на нагрузку от собственного веса, веса прикрепляемой к ней опалубки и свежеуложенной бетонной смеси. Жесткую арматуру применяют при бетонировании большепролетных перекрытий, сильно загруженных колонн нижних этажей многоэтажных зданий.
Жесткую арматуру применяют при бетонировании большепролетных перекрытий, сильно загруженных колонн нижних этажей многоэтажных зданий.
Рис. 16. Сцепление арматуры с бетоном:
1 — бетон, 2—гладкая арматура, 3 — арматура периодического профиля
Технические требования к арматурной стали. К ним относятся требования по прочности, пластичности, свариваемости, хладноломкости.
Прочность определяют путем испытания образцов стали на растяжение. Основной характеристикой прочности малоуглеродистых арматурных сталей служит предел текучести.
Прочность горячекатаной стержневой арматурной стали существенно — в несколько раз — повышают термическим или термомеханическим упрочнением, проволочной — холодным деформированием. Термическое упрочнение состоит из закалки и частичного отпуска стали. Закалку осуществляют нагревом стержней до температуры 800…900 °С и быстрым охлаждением, отпуск — нагревом до температуры 300…400 °С и постепенным охлаждением. Термомеханическое упрочнение производят путем нагрева, пластического деформирования и последующей термообработки арматуры. Это повышает прочность стержневой арматуры до 1800 МПа.
Это повышает прочность стержневой арматуры до 1800 МПа.
Проволочную арматурную сталь упрочняют холодным деформированием, пропуская ее через несколько последовательно уменьшающихся в диаметре отверстий. Чтобы получить структуру стали, необходимую для такого холодного волочения, проволоку подвергают предварительной термообработке — патентированию. Оно заключается в нагреве проволоки до температуры 870…950 °С, быстром охлаждении до температуры 500 °С, выдержке и охлаждении на воздухе. По такой технологии изготовляют высокопрочную арматурную проволоку.
Прочностные характеристики арматуры нормируют, как правило, по сопротивлению растягивающим усилиям. В некоторых конструкциях арматуру используют как элемент, усиливающий работу бетона на сжатие. В этом случае нормируют сопротивление арматуры сжатию. Его принимают равным расчетному сопротивлению при растяжении, но не более 400 МПа.
Пластические свойства арматурных сталей важны для нормальной работы железобетонных конструкций под нагрузкой, механизации арматурных работ. Снижение пластических свойств стали может стать причиной хрупкого (внезапного) разрыва арматуры в конструкциях, хрупкого излома напрягаемой арматуры в местах резкого перегиба или при закреплении в захватах. Поэтому пластические свойства арматурных сталей обязательно нормируют. Пластичность характеризуют полным относительным удлинением после разрыва образца, %, а также по результатам испытания на загиб в холодном состоянии.
Снижение пластических свойств стали может стать причиной хрупкого (внезапного) разрыва арматуры в конструкциях, хрупкого излома напрягаемой арматуры в местах резкого перегиба или при закреплении в захватах. Поэтому пластические свойства арматурных сталей обязательно нормируют. Пластичность характеризуют полным относительным удлинением после разрыва образца, %, а также по результатам испытания на загиб в холодном состоянии.
Свариваемость арматурных сталей характеризуется надежным сварным соединением, отсутствием трещин и других пороков металла в швах и прилегающих зонах. Это свойство используют при изготовлении сварных каркасов и сеток, стыковке стержневой арматуры. Горячекатаные малоуглеродистые и низколегированные арматурные стали свариваются хорошо. Нельзя сваривать стали, упрочненные термически или вытяжкой, так как в результате сварки эффект упрочнения утрачивается: в термически упрочненной стали происходят отпуск и потеря закалки, а в проволоке, упрочненной вытяжкой, — отжиг и потеря наклепа.
Хладноломкость характеризуется склонностью арматурных сталей к хрупкому разрушению при температурах ниже —30 °С. Хладноломкостью обладают горячекатаные стали периодического профиля, изготовленные из полуспокойной мартеновской или конвертерной стали. Менее склонны к хрупкому разрушению при низкой температуре термически упрочненные арматурные стали, а также высокопрочная проволока.
Читать далее:
Теплоизоляционные материалы
Основные свойства строительных материалов
Фиксаторы арматуры
Материалы для смазывания форм
Сборные бетонные и железобетонные конструкции
Арматурные изделия и закладные детали
Проволочная арматура
Стержневая арматура
Обработка давлением
Термическая и химико-термическая обработка стали
Классификация трубопроводной арматуры — ТД «НХИ-Групп»
Содержание:
- Базовая классификация: назначение трубопроводной арматуры
- Классификация по сфере эксплуатации
- Классификация по способу управления
- Классификация по параметрам
- Классификация по способу крепления
Различают несколько классификаций трубопроводной арматуры: по месту уплотнения, типу управления, присоединения к трубам, параметрам изделий, материалу изготовления, области применения. Самая популярная – базовая классификация по назначению устройства.
Самая популярная – базовая классификация по назначению устройства.
Базовая классификация: назначение трубопроводной арматуры
Выделяют семь типов трубопроводной арматуры:
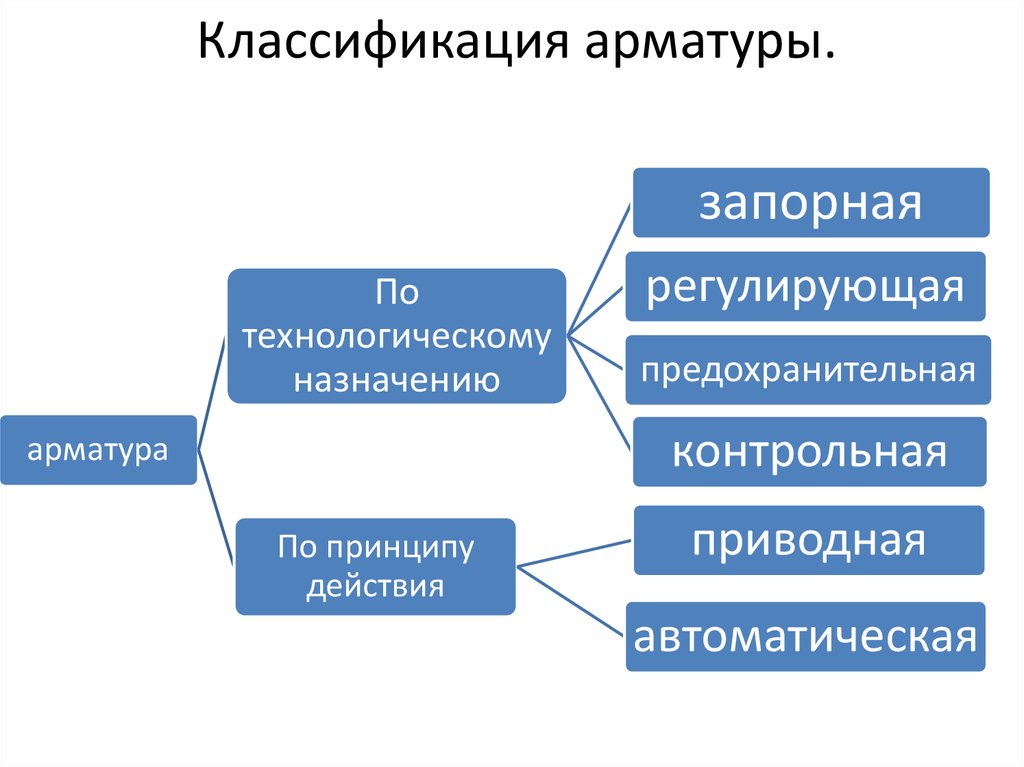
Запорная арматура – самая обширная группа, в которую входят различные изделия, предназначенные для перекрытия потока рабочей среды (заслонки, краны, задвижки). Их функция заключается в создании герметичного перекрытия сети.
Регулирующая арматура – специальный тип изделий, позволяющий менять уровень потока рабочей среды, его напор, давление, температуру и другие параметры. С ее помощью можно максимально точно настроить расход рабочей среды и оптимизировать технологические процессы. В эту группу входят такие устройства, как клапаны, вентили, дроссели и специальные приспособления для регулировки потока.
Предохранительная арматура – изделия, обеспечивающие автоматическое открытие клапана для стравления/сброса давления или рабочей среды при возникновении факторов риска, способных привести к аварийной ситуации. В этот класс входят предохранительные клапаны, импульсные изделия и мембранные приспособления.
В этот класс входят предохранительные клапаны, импульсные изделия и мембранные приспособления.
Защитная арматура – устройства, предназначенные для защиты приборов и трубопровода при критических колебаниях параметров рабочей среды. Их основная функция заключается в полном перекрытии участка трубопроводной сети или всего трубопровода при возникновении угрозы. Наиболее популярные представители типа – обратные и отсечные клапаны, пневмозадвижки, заслонки.
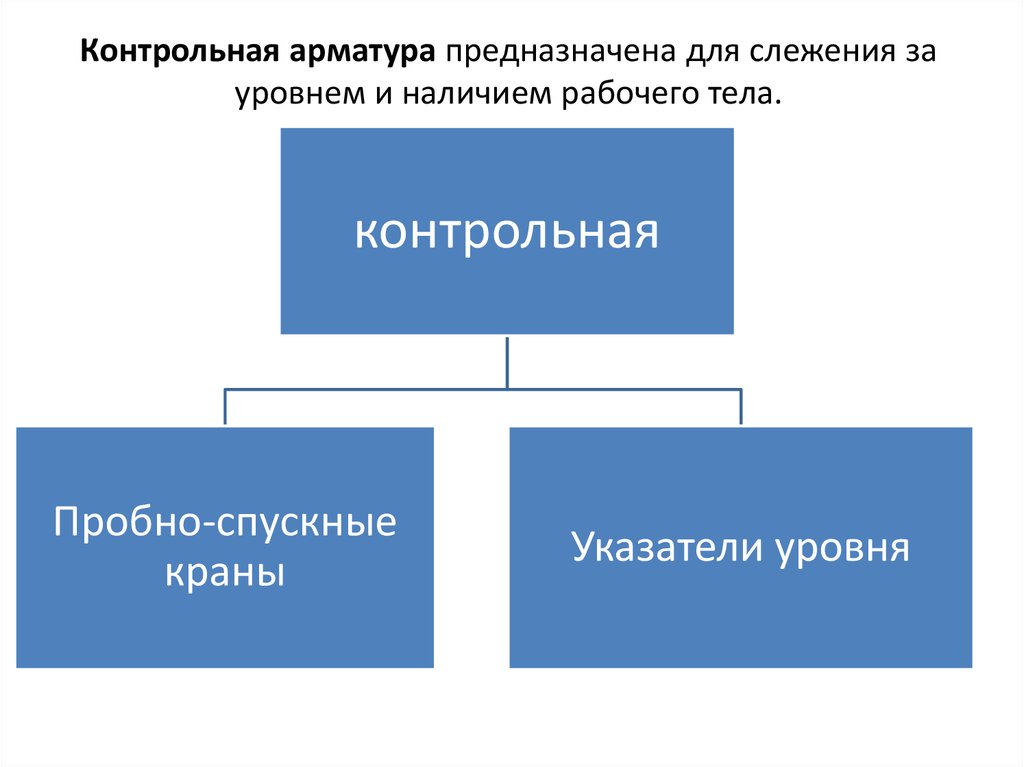
Контрольная арматура – устройства для определения движения среды и ее уровня. Они представлены датчиками уровня, пробно-спускными клапанами.
Фазоразделительная арматура – специальные изделия, предназначенные для автоматического разделения фаз рабочего материала, находящегося в разных агрегатных состояниях. Сюда входят маслоотделители, конденсатоотводчики.
Смесительно-распределительная арматура используется для перемешивания несколько потоков в один, разветвления единого потока на несколько. В нее входят смесители, клапана и другие специальные смешивающие устройства.
В нее входят смесители, клапана и другие специальные смешивающие устройства.
Классификация по сфере эксплуатации
По типу эксплуатации выделяют всего пять классов арматуры:
- Универсальную, применяемую в различных трубопроводных системах. Она не имеет четкой привязки к предприятию, которое ее будет использовать. Продукция серийного изготовления.
- Специальную, изготавливаемую под конкретные условия эксплуатации и параметры, специфику предприятия.
- Устройства для особых условий эксплуатации, которые устанавливаются трубопроводы с повышенными требованиями к надежности и безопасности. Они монтируются на магистральных трубопроводах, транспортирующих токсичные и агрессивные среды, взрывоопасные вещества.
- Изделия с узким профилем, предназначенные для обустройства трубопроводов судостроительных и транспортных предприятий.
- Арматуру с санитарно-техническим уклоном для бытовых трубопроводных сетей. Изделия серийной продукции, имеющая повышенные требования к внешнему виду и простоте монтажа, замены и применения.

Классификация по способу управления
Управление трубопроводной арматуры может осуществляться различным способом.
Во-первых, вручную. Различные виды арматуры (краны, задвижки и т. п.) оснащаются специальными ручками, рычагами или маховиками для управления устройством вручную. Также ручные устройства могут оснащаться адаптером для дистанционного управления.
Во-вторых, существуют приводные изделия, у которых имеется собственный, смонтированный на корпус привод: гидравлический, пневматический, электрический привод. Ими оснащается, как правила, запорная и регулирующая арматура, такая как заслонки и клапаны.
В-третьих, имеются автоматизированные приборы, оснащенные специальными датчиками и управляемыми по программе без участия человека. Они реагируют на изменения рабочей среды и сами корректируют параметры.
Классификация по параметрам
В обозначении трубопроводной арматуры шифруется множество параметров, определяющих сферу их применения и размер. Оно регламентируется ГОСТ Р52720. Основные характеристики, по которым подбирается изделие:
Оно регламентируется ГОСТ Р52720. Основные характеристики, по которым подбирается изделие:
- Условное давление среды PN. Эта характеристика обозначает давление, при котором трубопровод и все подключенные к нему устройства работают безаварийно в течение определенного промежутка времени. Классификация по условному давлению содержится в ГОСТ 26349.
- Условный проход DN. Этот показатель нужен для описания трубопроводных систем для подгонки различных элементов друг к другу. Он указывается в мм и характеризуется ГОСТ 28338.
Классификация по способу крепления
Другая популярная классификация — по методу присоединения арматуры к трубе:
- Сварной способ используется для создания неразъемного соединения с трубопроводной арматурой. Он отличается надежностью и применяется на участках, где не требуется или невозможно обслуживание системы.
- Муфтовая арматура крепится к трубопроводу с помощью муфт (цилиндрических, трубных, резьбовых, конических и т.
 п.). Так монтируются небольшие клапаны, вентили и заслонки. Обычно, с DN до 80 мм.
п.). Так монтируются небольшие клапаны, вентили и заслонки. Обычно, с DN до 80 мм. - Арматура с фланцевым присоединением широко применяется в трубопроводных системах любого назначения. Крепеж осуществляется с помощью болтов или шпилек.
- Изделия со штуцерным присоединением имеет резьбовые патрубки (с внутренней или наружной резьбой в зависимости от типа арматуры).
Также существуют изделия, применяемые для монтажа цапковое крепление с буртиком для уплотнения и наружную резьбу.
Компания НХИ занимается изготовлением и поставкой трубопроводной арматуры всех типов. В каталоге представлен широкий ассортимент изделий с различным условным проходом, давлением. Вы можете самостоятельно выбрать арматуру из списка товаров или обратиться за подбором подходящего устройства к специалистам компании.
Можно ли использовать обучение с подкреплением для классификации?
8 минут чтения
После изучения обучения с подкреплением кто не задается вопросом, будет ли оно полезно для задач, которые обычно зарезервированы
для контролируемого обучения.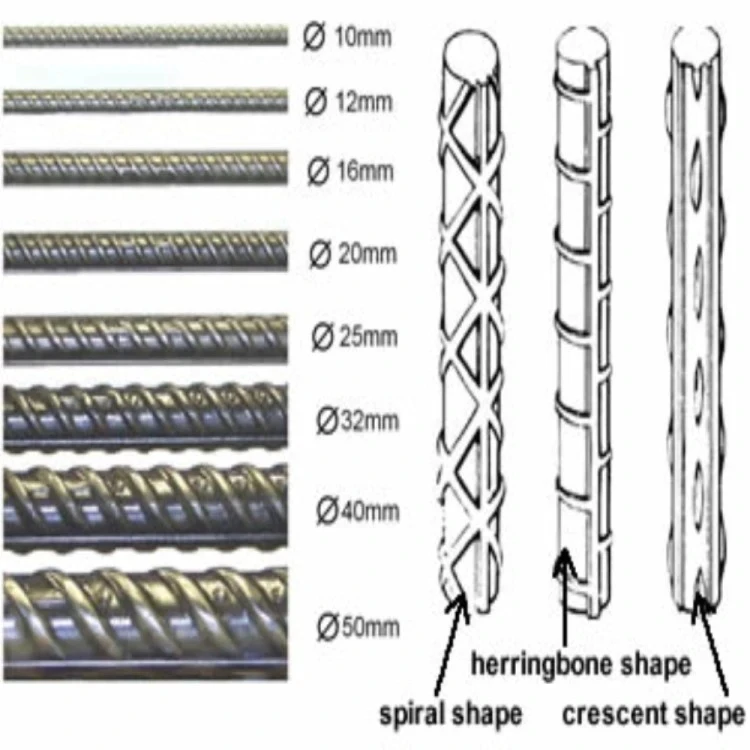
В конце концов, это естественный вопрос.
Итак, я решил выяснить это наилучшим из известных мне способов: написав кучу кода.
Загрузите блокнот Jupyter.
Загрузка экспериментальных данных
В попытке ответить на вопрос, не поглощая свой единственный графический процессор за несколько недель обучения, я выбрал набор данных MNIST.
в качестве экспериментальной базы.
MNIST — это достаточно простая задача, которую можно решить всего за несколько секунд, но в то же время достаточно сложная задача, чтобы ответить на
вопрос о том, можно ли использовать обучение с подкреплением для обучения классификатора.
Если вы не знакомы с этим, MNIST представляет собой набор изображений рукописных цифр (0-9) в черно-белом режиме.
Задача классификации состоит в том, чтобы определить, какую цифру представляет каждое изображение.
Изображения выглядят так:
Итак, давайте закодируем этого плохого мальчика.
Настройка
Наши единственные зависимости — это tensorflow и OpenAI Baselines. Давайте возьмем те
установка пакетов в сторону:
pip установить тензорный поток-gpu-1.15.5 pip install git+https://github.com/openai/[электронная почта защищена]
Затем весь импорт сразу:
время импорта импортный тренажерный зал импортировать случайный импортировать numpy как np из тензорного потока импортировать керас из слоев импорта tensorflow.keras из baselines.ppo2 импортировать ppo2 из baselines.common.vec_env.dummy_vec_env импортировать DummyVecEnv импортировать из исходных данных deepq скамья импорта базовых показателей регистратор импорта из базовых показателей импортировать тензорный поток как tf из baselines.common.tf_util импортировать make_session
Теперь мы готовы погрузиться в код.
Получение данных
# Модель/параметры данных число_классов = 10 input_shape = (28, 28, 1) # данные, разделенные между обучающими и тестовыми наборами (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data() # Масштабировать изображения в диапазоне [0, 1] x_train = x_train.astype("float32") / 255 x_test = x_test.astype("float32") / 255 # Убедитесь, что изображения имеют форму (28, 28, 1) x_train = np.expand_dims (x_train, -1) x_test = np.expand_dims (x_test, -1) print("Форма x_train:", x_train.shape) print(x_train.shape[0], "образцы поездов") print(x_test.shape[0], "тестовые образцы") # преобразовать векторы классов в бинарные матрицы классов y_train_one_hot = keras.utils.to_categorical (y_train, num_classes) y_test_one_hot = keras.utils.to_categorical (y_test, num_classes)
С помощью этого кода мы используем встроенные утилиты keras для загрузки набора данных mnist и загрузки его в память.
Он скопирован прямо со страницы примера keras.
Если вы смотрели какое-либо из моих видео, вы, вероятно, знаете, что я предпочитаю PyTorch, но, учитывая, что я решил
использовать базовые уровни для алгоритмов RL, keras создан как более простая альтернатива базовому уровню контролируемого обучения.
Базовый уровень Кераса
Даже если RL сработает, мы не узнаем, хороша ли она, если нам не с чем ее сравнить.
Давайте исправим это, обучив классификатор на наборе данных MNIST с помощью традиционного контролируемого обучения с использованием Keras.
по определению keras_train (batch_size = 32, эпохи = 2):
модель = keras.Sequential(
[
keras.Input(форма=input_shape),
слои.Свести(),
слои.Dense(64, активация='relu'),
слои.Dense(64, активация='relu'),
слои.Dense (количество_классов, активация = "softmax")
]
)
модель.резюме()
model.compile(loss="categorical_crossentropy", оптимизатор="adam", metrics=["точность"])
start_time = время.время()
model.fit(x_train, y_train_one_hot, batch_size=batch_size, epochs=epochs, validation_split=0,1)
end_time = время.время()
оценка = model.evaluate (x_test, y_test_one_hot, подробный = 0)
print("Потеря теста:", оценка[0])
print("Точность теста:", оценка[1])
print("Время обучения:", end_time - start_time)
keras_train()
Обратите внимание, что он использует MLP с двумя скрытыми слоями по 64 модуля. Это довольно классический размер сети для RL, и я хочу, чтобы все попытки имели примерно одинаковое количество параметров.
Это довольно классический размер сети для RL, и я хочу, чтобы все попытки имели примерно одинаковое количество параметров.
Кроме того, он имеет размер пакета 32, так как это типичный размер пакета, используемый в DQN.
Когда я запускаю его, я получаю такой вывод:
Потеря теста: 0,11103802259191871 Точность теста: 0,9658 Время обучения: 14.185736656188965
Это 96% точности всего за 14 секунд тренировки. Довольно внушительный!
RL Тренировочная среда (gym.Env)
С тех пор, как OpenAI выпустила свою библиотеку тренажерного зала, она стала стандартом де-факто для RL.
среды обучения алгоритмам.
Давайте создадим такой, который адаптирует парадигму вознаграждения среды RL к проблеме классификации.
Идея проста: каждый класс изображения — это уникальное действие, которое может выполнить агент. Если он предпримет действие, которое
соответствует правильному классу, даем +1 награду. В противном случае мы даем 0 наград.
Кроме того, ошибка временной разницы делает предположение, что действия на одном этапе влияют на вознаграждение на следующих шагах. Что
в нашей среде это не так. Таким образом, эпизоды, которые длятся дольше одного временного шага, не имеют никакого смысла в этом контексте.
класс MnistEnv (спортзал. Env):
def __init__(self, images_per_episode=1, набор данных=(x_train, y_train), random=True):
супер().__инит__()
self.action_space = спортзал.spaces.Discrete(10)
self.observation_space = gym.spaces.Box (низкий = 0, высокий = 1,
форма=(28, 28, 1),
dtype=np.float32)
self.images_per_episode = images_per_episode
self.step_count = 0
self.x, self.y = набор данных
self.random = случайный
self.dataset_idx = 0
шаг защиты (я, действие):
сделано = ложь
награда = int (действие == self.expected_action)
obs = self.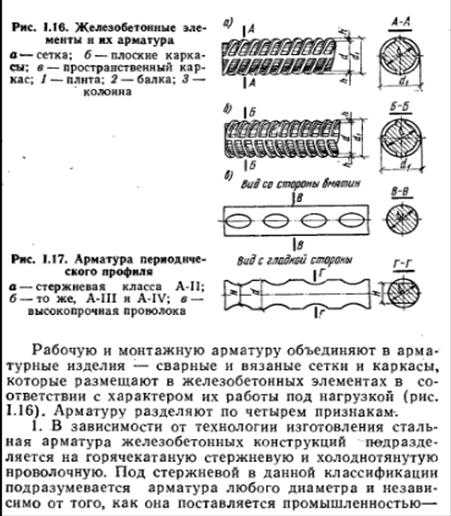 _next_obs()
self.step_count += 1
если self.step_count >= self.images_per_episode:
сделано = верно
вернуть наблюдения, награда, сделано, {}
сброс защиты (сам):
self.step_count = 0
obs = self._next_obs()
возврат наблюдений
защита _next_obs(я):
если self.random:
next_obs_idx = random.randint(0, len(self.x) - 1)
self.expected_action = int(self.y[next_obs_idx])
obs = self.x[next_obs_idx]
еще:
obs = self.x[self.dataset_idx]
self.expected_action = int(self.y[self.dataset_idx])
self.dataset_idx += 1
если self.dataset_idx >= len(self.x):
поднять StopIteration()
возврат наблюдений
_next_obs()
self.step_count += 1
если self.step_count >= self.images_per_episode:
сделано = верно
вернуть наблюдения, награда, сделано, {}
сброс защиты (сам):
self.step_count = 0
obs = self._next_obs()
возврат наблюдений
защита _next_obs(я):
если self.random:
next_obs_idx = random.randint(0, len(self.x) - 1)
self.expected_action = int(self.y[next_obs_idx])
obs = self.x[next_obs_idx]
еще:
obs = self.x[self.dataset_idx]
self.expected_action = int(self.y[self.dataset_idx])
self.dataset_idx += 1
если self.dataset_idx >= len(self.x):
поднять StopIteration()
возврат наблюдений
Полученный код для тренажерного зала Env довольно прост.
Единственное, что следует отметить, это то, что мы можем поменять местами набор данных и случайных параметров на функцию __init__ для
превратить тренажерный зал в оценочную скамью на тестовом наборе.
Момент истины
Теперь узнаем раз и навсегда. Можно ли использовать RL для классификации?
Сначала мы будем тренироваться с дуэльной глубокой Q-сетью.
определение mnist_dqn():
logger.configure(dir='./logs/mnist_dqn', format_strs=['stdout', 'tensorboard'])
env = MnistEnv (images_per_episode = 1)
env = скамейка.Monitor (env, logger.get_dir())
модель = deepq.learn(
окружение,
"млп",
количество_слоев=1,
номер_скрытый = 64,
активация=tf.nn.relu,
скрытые=[32],
дуэль = правда,
лр=1е-4,
total_timesteps=int(1.2e5),
размер_буфера=10000,
исследовательская_фракция = 0,1,
explore_final_eps=0,01,
поезд_частота = 4,
Learning_starts=10000,
target_network_update_freq=1000,
)
model.save('dqn_mnist.pkl')
env.close()
модель возврата
start_time = время.время()
dqn_model = mnist_dqn()
print("Время обучения DQN:", time.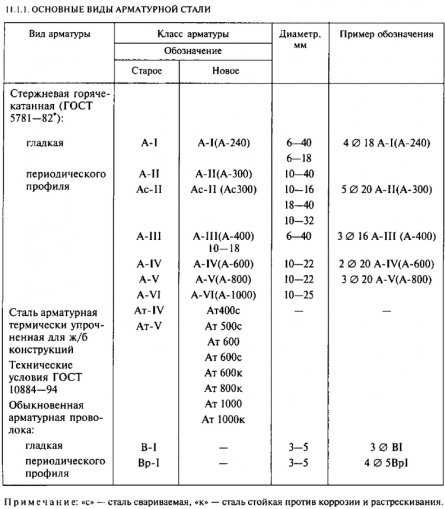 time() - start_time)
time() - start_time)
Это довольно стандартные вещи, ничего необычного не происходит. Мы используем реализацию DQN из
Базовые показатели OpenAI.
Размер пакета равен 32, как и в модели keras, а общее количество временных шагов равно 120 000, что в два раза превышает количество выборок.
в тренировочном наборе. Это имитирует 2 эпохи, как мы используем в модели keras.
По сравнению с контролируемым базовым планом существует архитектурная разница. Дуэльная часть алгоритма ломается
вместо этого последний слой на два отдельных слоя по 32 единицы. Эти две головки сходятся по отдельности в один выход, и
вывод для каждого действия.
В конечном счете, это означает, что параметров станет на несколько меньше, но мы все еще на том же уровне.
Окончательный вывод после обучения выглядит так:
-------------------------------------- | % времени, потраченного на изучение | 1 | | эпизоды | 1.2e+05 | | средняя награда за 100 эпизодов | 1 | | шаги | 1.2e+05 | -------------------------------------- Время обучения DQN: 461,527117729187
потребовалось намного больше времени (более чем в 30 раз), чем контролируемый базовый уровень, но похоже, что точность была достигнута на 100%.
на тренировочном комплексе!
Давайте запустим оценку и посмотрим, как она выдержит испытание на тестовом наборе.
определение mnist_dqn_eval (dqn_model):
попытки, верно = 0,0
env = MnistEnv (images_per_episode = 1, набор данных = (x_test, y_test), random = False)
пытаться:
пока верно:
obs, выполнено = env.reset(), False
пока не сделано:
obs, rew, done, _ = env.step(dqn_model(obs[None])[0])
попытки += 1
если рев > 0:
правильно += 1
кроме StopIteration:
Распечатать()
print('проверка завершена...')
print('Точность: {0}%'.format((число с плавающей запятой (верно) / количество попыток) * 100))
mnist_dqn_eval (dqn_model)
Аааааанннндддд… результаты:
Точность: 93,47869573914784%
Точность 93,4%!
Ну, я думаю, это ответ, обучение с подкреплением определенно можно использовать в качестве классификатора.
То есть до тех пор, пока вы готовы ждать в 30 раз больше времени, чтобы обучить его с помощью RL.
Можем ли мы сделать лучше? Может это просто алгоритм. DQN, в конце концов, не король алгоритмов RL.
Тестирование с королем
Чтобы выяснить, можем ли мы добиться большего успеха, мы собираемся провести еще один эксперимент с королем алгоритмов RL.
… барабанная дробь …
Оптимизация проксимальной политики (PPO), представленная
Джон Шульман в 2017 году уже некоторое время занимает место короля алгоритмов.
Это алгоритм, который достаточно гибок, чтобы применяться ко многим типам задач, и достаточно надежен, чтобы не требовать многого.
настройка гиперпараметров.
На самом деле он оказался настолько хорош, что всех удивило, когда OpenAI использовал его для обучения ботов DOTA 2, которые нас раздавили
простые смертные в профессиональной игре.
Итак, давайте посмотрим, как он работает в качестве скромного классификатора.
определение mnist_ppo():
logger.configure(dir='./logs/mnist_ppo', format_strs=['stdout', 'tensorboard'])
env = DummyVecEnv([лямбда: скамейка.Monitor(MnistEnv(images_per_episode=1), logger.get_dir())])
модель = ppo2.learn(
окружение = окружение,
сеть = 'млп',
число_слоев = 2,
номер_скрытый = 64,
nшагов=32,
total_timesteps=int(1.2e5),
семя = целое (время. время ()))
модель возврата
start_time = время.время()
ppo_model = mnist_ppo()
print("Время обучения PPO:", time.time() - start_time)
То же самое, что и с DQN, это стандартная установка с использованием базовой реализации PPO в нашей среде.
Архитектурно модель PPO добавляет стоимостную главу с одним выходом после последнего уровня MLP. В конце концов, это означает
еще несколько параметров по сравнению с контролируемым базовым уровнем.
После обучения вывод выглядит следующим образом:
-------------------------------------- | среднее значение | 1 | | средний | 0,95 | | кадров в секунду | 177 | | потеря/оккл | 0,131 | | потеря/усечение | 0,0625 | | потеря/policy_entropy | 0,0253 | | потеря/policy_loss | -0,0292 | | убыток/значение_убыток | 0,0271 | | разное/explained_variance | 0,115 | | разное/обновления | 3.75e+03 | | разное/serial_timesteps | 1.2e+05 | | разное/time_elapsed | 638 | | разное/общее_время | 1.2e+05 | -------------------------------------- Время обучения PPO: 638.657053232193
ВОУ! Более 10 минут тренировочного времени, и это даже не на 100% на тренировочном наборе.
Выглядит не очень хорошо, но давайте посмотрим, как это работает на тренировочном наборе.
определение mnist_ppo_eval (ppo_model):
попытки, верно = 0,0
env = DummyVecEnv([лямбда: MnistEnv(images_per_episode=1, набор данных=(x_test, y_test), random=False)])
пытаться:
пока верно:
obs, выполнено = env.reset(), [False]
пока не сделано[0]:
obs, rew, done, _ = env.step(ppo_model.step(obs[None])[0])
попытки += 1
если рев[0] > 0:
правильно += 1
кроме StopIteration:
Распечатать()
print('проверка завершена...')
print('Точность: {0}%'.format((число с плавающей запятой (верно) / количество попыток) * 100))
mnist_ppo_eval(ppo_model)
Функция eval почти копирует/вставляет функцию eval DQN, но учитывает пакетную среду.
Вывод:
Точность: 95,1995199519952%
Точность 95%! Похоже, что PPO имеет преимущество перед DQN, хотя обучение занимает на 150% больше времени.
Тем не менее, мы примерно в 40 раз тратим больше времени на обучение с помощью обучения с учителем, и все еще не с более высокой точностью.
Важно то, что мы ответили на наш вопрос!
Reinforcement Learning
CAN можно использовать для обучения классификатора.
НО только маньяк будет ждать в 40 раз дольше!
Если вам понравилась эта статья, посетите мой канал на YouTube.
где я обсуждаю различные темы ИИ с упором на RL.
Категории:
ай,
обучение с подкреплением
Обновлено:
Обучение с подкреплением: современная классификация методов машинного обучения (часть 3) | Донни Со
В этой третьей части серии под названием «Обучение машинному обучению» мы обсудим последний класс методов машинного обучения: обучение с подкреплением.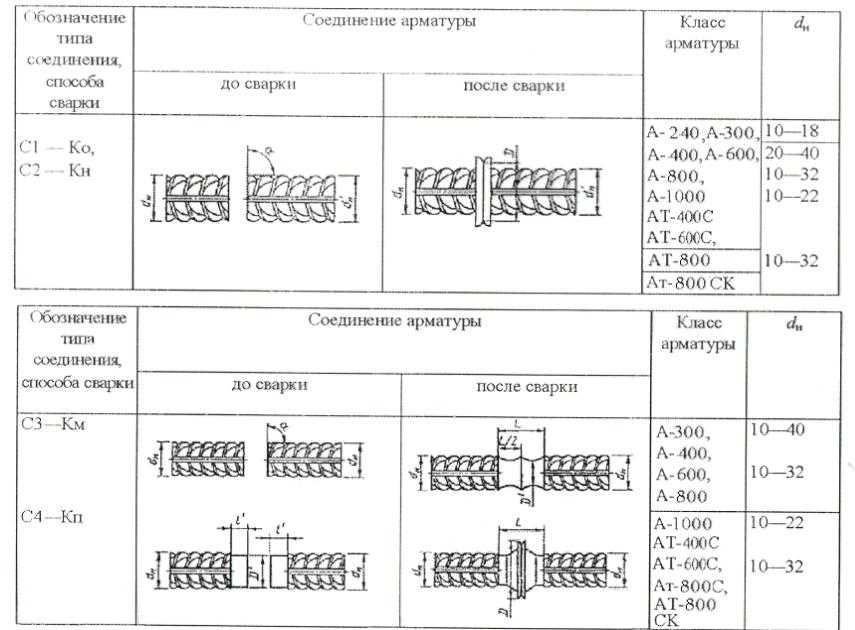 Если вы хотите прочитать мой взгляд на контролируемое/неконтролируемое обучение, вы можете прочитать его здесь и здесь .
Если вы хотите прочитать мой взгляд на контролируемое/неконтролируемое обучение, вы можете прочитать его здесь и здесь .
Как уже упоминалось, современные алгоритмы машинного обучения можно разделить на один из трех классов: обучение с учителем, обучение без учителя и обучение с подкреплением. Это разделение выбрано из-за того, как эти алгоритмы изучают модель машинного обучения. В частности:
Стремительный рост индустрии машинного обучения возродил интерес людей к искусственному…
Во время наших предыдущих обсуждений мы упоминали, что обучение с учителем обычно состоит из помеченных данных, тогда как обучение без учителя работает с данными без обучающих меток.
Вы можете считать обучение с подкреплением (RL) другим, потому что вы не начинаете с каких-либо данных. Скорее вы начинаете с понимания проблемы, которую пытаетесь решить. Например, если вы хотите решить навигационную задачу о перемещении из пункта А в пункт Б с помощью обучения с подкреплением, вам необходимо определить следующее:
- Агент
- в точку B.
 Это может включать различные промежуточные этапы вознаграждения между точками A и B.
Это может включать различные промежуточные этапы вознаграждения между точками A и B. - Среда ( состояние ) и то, как агент наблюдает среду, в которой находятся точки A и B. двигаться вверх, вниз, влево, вправо)
В этом навигационном примере агент находится в среде, и его цель — добраться из точки А в точку Б. Агент достигает этой цели, выполняя действий . Эти действия агента могут привести к вознаграждает , чтобы мотивировать агента, когда он делает правильный выбор. Эти действия также могут изменить состояние среды. Наконец, это новое состояние среды наблюдает агент, который затем решает, какое следующее наилучшее действие следует предпринять. Это резюмируется изображением ниже.
Рисунок 1: Взаимодействие между агентом и средой. Источник: http://rll.berkeley.edu/deeprlcourse-fa15/
Давайте используем этот пример маршрутизации в качестве простой иллюстрации того, как может работать RL. Мы начинаем без данных, но агент будет генерировать несколько вариантов маршрутизации, чтобы добраться из точки А в точку Б методом проб и ошибок. Предполагая, что действия, которые мы можем предпринять, следующие:
Мы начинаем без данных, но агент будет генерировать несколько вариантов маршрутизации, чтобы добраться из точки А в точку Б методом проб и ошибок. Предполагая, что действия, которые мы можем предпринять, следующие:
- Вверх
- Вниз
- Влево
- Вправо
Награда выдается при достижении точки B. Предположим также, что в этой ситуации агент может сделать только четыре шага, прежде чем игра закончится. Затем агент выполняет ряд действий, которые могут выглядеть следующим образом:
Каким должен быть результат строки 3? Ну, это действительно зависит. Если предположить, что агент находится в лабиринте только с тремя горизонтальными квадратами, а состояние окружающей среды до Действия 1 всегда следующее:
Тогда становится ясно, что важнее всего то, что агенту нужно два раза переместиться вправо, чтобы достичь точки B (Действия агента, движущегося вверх или вниз, становятся несущественными). Действия, предпринятые для ID 3, приводят агента к точке B.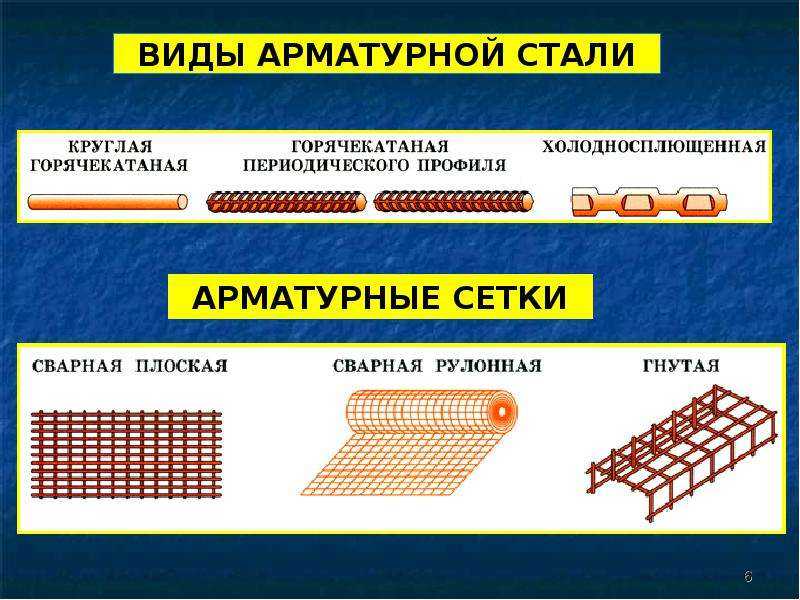
Предположим, что у нас есть альтернативная среда лабиринта как таковая:
Тогда важнее всего то, что агенту нужно спуститься один раз и дважды пройти вправо, чтобы добраться до Точка B. Действия, предпринятые для ID 3, приводят агента к точке B.
В другой альтернативной среде предположим, что теперь у нас есть области в лабиринте, куда агент не может попасть (затемненные области). В этом случае ID 0 и ID 2 перемещают Агента из точки A в точку B, а ID 3 не может. (Вам потребуется, чтобы агент сначала переместился вправо, прежде чем двигаться вниз.)
В задачах RL мы не знаем об окружающей среде. Проблема в RL заключается в том, как мы узнаем, какое следующее наилучшее действие следует предпринять, чтобы максимизировать вознаграждение. Это делается путем генерации данных посредством этого итеративного процесса проб и ошибок, когда агент наблюдает за окружающей средой и предпринимает следующее наилучшее действие.
Есть два основных метода, которые можно изучить из сгенерированных данных, и это методы Q Learning (обучение на основе ценности) и градиенты политики. Чтобы объяснить эти два метода, я буду решать вводную игру из тренажерного зала OpenAI, известную как CartPole-v0. Мой подход будет заключаться в том, чтобы попытаться объяснить эти методы с точки зрения программирования, и, надеюсь, оттуда мы получим интуицию для любого метода.
Чтобы объяснить эти два метода, я буду решать вводную игру из тренажерного зала OpenAI, известную как CartPole-v0. Мой подход будет заключаться в том, чтобы попытаться объяснить эти методы с точки зрения программирования, и, надеюсь, оттуда мы получим интуицию для любого метода.
Стойка прикреплена к тележке. Когда начинается игровой эпизод, шест находится в вертикальном положении. Тележка может двигаться как влево, так и вправо. В каждый момент времени тележка должна двигаться либо влево, либо вправо. Перемещение тележки влияет на шест. Цель состоит в том, чтобы удерживать шест под определенным углом более 19 секунд.5 моментов времени более 100 серий подряд. Интуиция такова, что если алгоритм RL способен сбалансировать полюс более чем на 195 моментов времени в 100 эпизодах, это означает, что алгоритм RL понял, как правильно играть в игру.
Рисунок 2: CartPole-v0
Вкратце:
Награда: Агент получает награду +1 каждый раз, когда шест остается в вертикальном положении.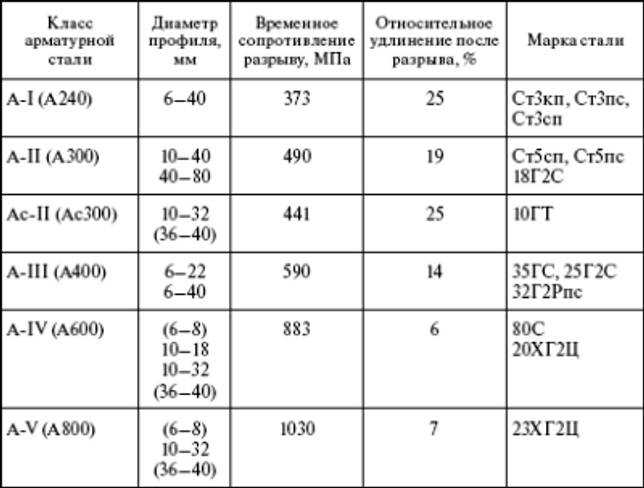
Действия: Тележка может двигаться только влево или вправо.
Наблюдения: Агент наблюдает за окружающей средой с помощью этих четырех значений:
Дополнительную информацию можно найти здесь.
Интуиция для Q Learning следующая: учитывая определенные наблюдения, какова ожидаемая награда за каждое действие, которое может предпринять агент. Следовательно, Q Learning сродни созданию огромной таблицы поиска, где в каждой точке наблюдения таблица сообщает вам ожидаемые награды за выполнение любого из возможных действий. Давайте разберем это на эти пять деталей:
По сути, основной цикл Q-обучения выглядит просто так:
- Выберите следующее наилучшее действие для выполнения
- Выполните действие в среде
- Наблюдайте/дискретизируйте новое состояние в среде
- Обновите Q-таблицы
- Повторяйте до завершения
В RL есть концепция известный как эксплуатация против разведки. Это означает, что на каждом временном шаге агент может либо выполнить действие, которое в настоящее время он считает лучшим ходом (эксплуатация), либо агент может выполнить новый ход (исследование).
Это можно сделать с помощью жадного эпсилон-метода. Жадный эпсилон генерирует случайное число и проверяет, меньше ли оно переменной (эпсилон). Если это так, используется случайное действие (исследование). В противном случае используется лучшее действие для наблюдения (эксплуатация).
И последнее замечание: в самом начале Q-таблицы в основном пусты, поэтому вам нужно, чтобы агент выполнял больше исследовательских действий. Однако вы хотели бы, чтобы агент становился все более и более эксплуатирующим, поскольку Q-таблицы начинают заполняться, увеличивая эпсилон с течением времени.
Как мы видели ранее, наблюдения, возвращенные из окружающей среды, идут непрерывно. Однако при создании Q-таблиц эти числа проще преобразовать в дискретную форму. Это достигается с помощью следующей функции:
Этот элегантный способ дискретизации приписывается этой статье.
Наконец, мы обновляем Q-таблицы, используя формулу:
Полученное значение представляет собой ожидаемую будущую награду за новое действие.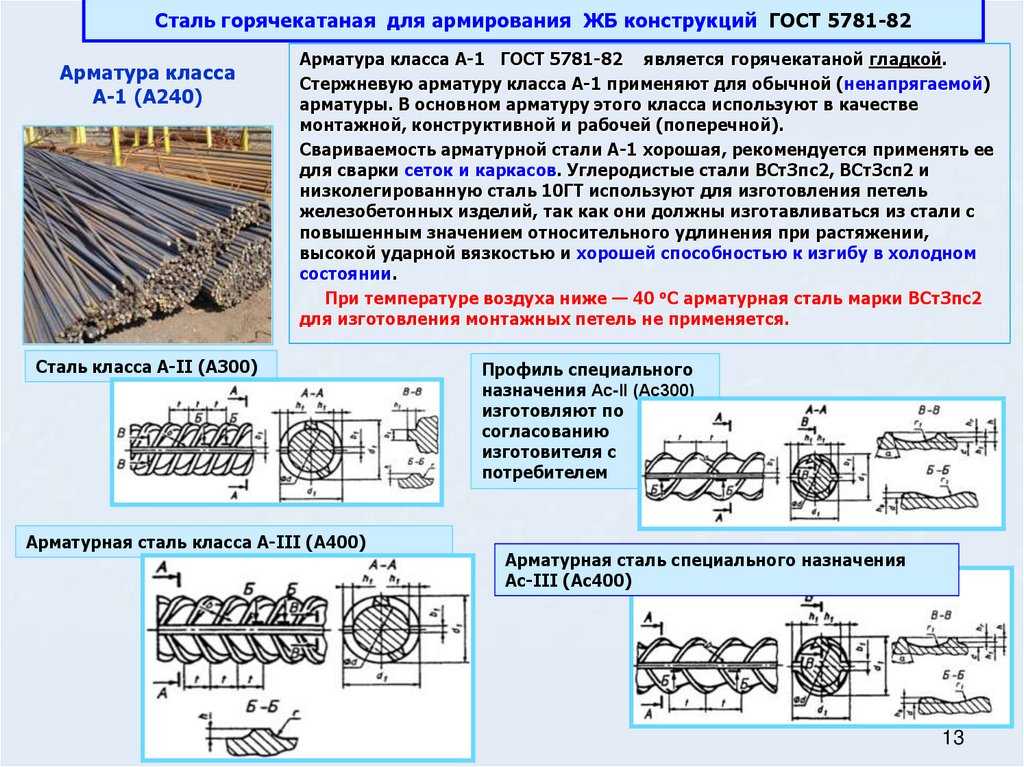 Полученная ценность состоит из двух частей: текущей награды и дисконтированной будущей награды. Это обесцененное будущее вознаграждение является оценкой оптимальной будущей стоимости после совершения действия, умноженной на коэффициент дисконтирования (чтобы учесть, что это будущее вознаграждение).
Полученная ценность состоит из двух частей: текущей награды и дисконтированной будущей награды. Это обесцененное будущее вознаграждение является оценкой оптимальной будущей стоимости после совершения действия, умноженной на коэффициент дисконтирования (чтобы учесть, что это будущее вознаграждение).
Переменная альфа управляет скоростью обновления существующих значений Q-таблицы.
Последний шаг обновляет альфа-скорость обучения. Как и в случае с epsilon, вначале вы можете захотеть, чтобы обновления были более агрессивными. Однако со временем вы, вероятно, захотите сократить количество обновлений, чтобы сделать вашу таблицу более стабильной.
Интуиция для градиентов политики такова: при определенных наблюдениях какая политика является наилучшей для агента. Градиенты политики немного сложнее, но стоит отметить, что недавние достижения в области RL относятся к градиентам политики.
Программно вы можете представить, что существует основной цикл, который определяет, какими должны быть политики.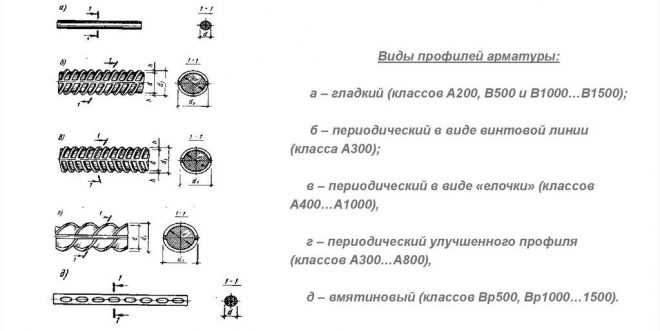 В этом случае мы будем использовать нейронную сеть и основной цикл, чтобы узнать эти политики. Следовательно, мы будем описывать нейронную сеть и три основные детали этого цикла:
В этом случае мы будем использовать нейронную сеть и основной цикл, чтобы узнать эти политики. Следовательно, мы будем описывать нейронную сеть и три основные детали этого цикла:
- Нейронная сеть
- Прямой проход (вычисление выходных действий из нейронной сети) нейронная сеть)
- Функция потерь
- Обратный проход (обновление весов нейронной сети)
Мы показываем построенную нами нейронную сеть. Он состоит из двух скрытых слоев по 32 узла.
Detail two передает в нейронную сеть текущее состояние окружающей среды и генерирует вероятности действий. Мы вызываем случайный выбор (на основе вероятностей действий, предоставляемых нейронной сетью), чтобы решить, какое действие мы предпримем.
Во-вторых, мы генерируем список действий из прямых проходов для передачи в среду. Когда мы скармливаем эти действия окружающей среде, мы получаем список вознаграждений благодаря этому списку действий.
Из списка действий мы вычисляем вектор, известный как текущее вознаграждение. Это постоянное вознаграждение рассчитывается с учетом вознаграждений, полученных от этой текущей временной метки до конечной точки. Однако награды, заработанные дальше, будут обесценены.
Это постоянное вознаграждение рассчитывается с учетом вознаграждений, полученных от этой текущей временной метки до конечной точки. Однако награды, заработанные дальше, будут обесценены.
Чтобы описать функцию потерь градиентов политики, мы сначала опишем функцию отрицательного логарифмического правдоподобия контролируемого обучения как
Это похоже на максимизацию вероятностного члена в левой части уравнения. Для градиентов политики формула аналогична, но с добавлением члена A , который известен как преимущество. В RL преимущество заменяется кумулятивным вознаграждением со скидкой.
Следовательно, это дает нам следующую реализацию, где мы берем журнал:
- результат модели (вероятность предпринятого действия) умножается на
- фактическое действие предпринято
Этот логарифмический член умножается далее по льготному вознаграждению.
Наконец, мы используем оптимизатор Adam для обновления весов нейронной сети на основе функции потерь журнала.
Эндрю Нг сказал, что ажиотаж и рекламная шумиха вокруг обучения с подкреплением немного непропорциональны экономической ценности, которую оно создает сегодня (источник). Сказав это, были некоторые конкретные отрасли, которые добились успеха в применении RL. Примеры:
- Финансы (Осуществление сделок в JP Morgan Chase)
- Проблемы управления/робототехники (управление светофором, навигация по охлаждению центра обработки данных)
- Спонсируемые поисковые торги в режиме реального времени (Alibaba)
Вы можете сказать, что все эти приложения имеют общую черту RL. А именно, способ определения проблемы в качестве агента, наблюдения и принятия мер в среде с очень четкими результатами вознаграждения (например, охлаждение центра обработки данных вознаграждает экономию затрат; управление светофором снижает вознаграждение за задержки / перегрузки).
Сопутствующую серию коротких видеолекций можно найти на YouTube здесь.
На этом завершается вводная серия из трех частей, посвященная современным классификациям машинного обучения.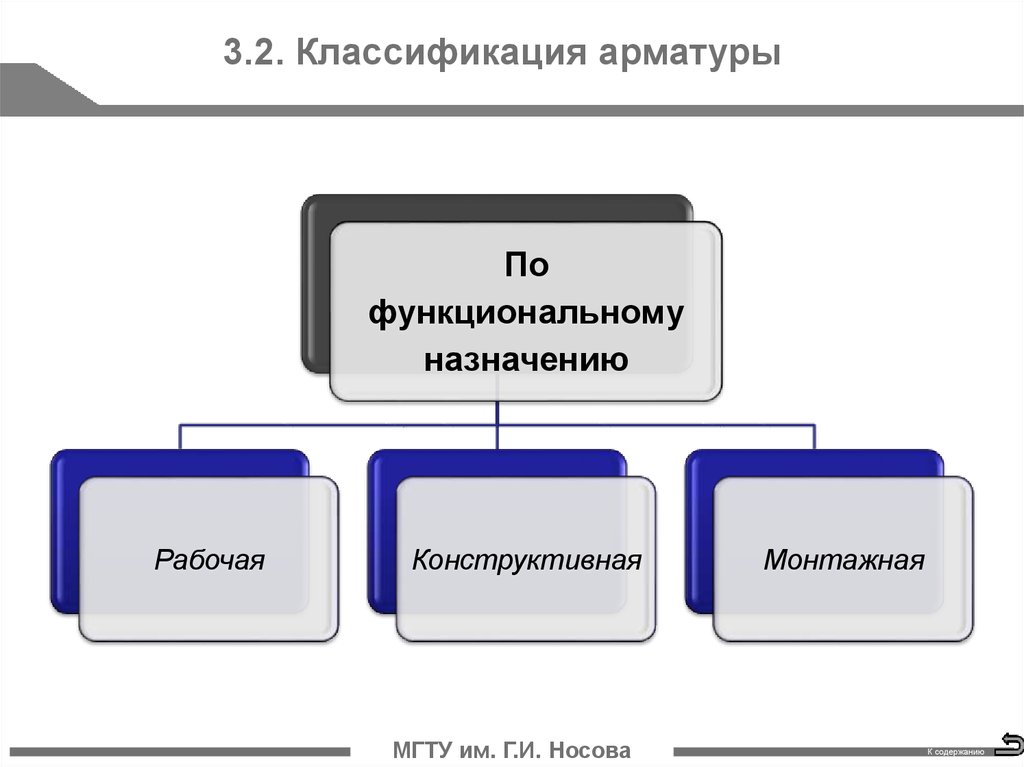 Надеюсь, вам было так же интересно их читать, как мне их писать!
Надеюсь, вам было так же интересно их читать, как мне их писать!
Автор является доцентом Сингапурского технологического института (SIT). Он имеет степень доктора компьютерных наук Имперского колледжа. Он также имеет степень магистра компьютерных наук NUS по программе Singapore MIT Alliance (SMA).
Мнения, изложенные в этой статье, принадлежат автору и не обязательно отражают официальную политику или позицию каких-либо организаций, с которыми связан автор. Автор также не имеет аффилированных лиц и не получает никаких вознаграждений от каких-либо продуктов, курсов или книг, упомянутых в этой статье.
Суть решения CartPole с Q-Learning можно найти здесь:
Суть решения CartPole с градиентами политики можно найти здесь:
Глубокое обучение с подкреплением для несбалансированной классификации
Japkowicz N, Stephen S (2002 ) Проблема дисбаланса классов: систематическое исследование. Intel Data Anal 6 (5):429–449
Статья
Google ученый
 «>
«>Weiss GM (2004) Горное дело с редкостью: объединяющая структура. Информационный бюллетень ACM Sigkdd Explorations 6(1):7–19
Артикул
Google ученый
He H, Garcia EA (2008) Изучение несбалансированных данных. IEEE Trans Knowl Data Eng 9: 1263–1284
Google ученый
Haixiang G, Yijing L, Shang J, Mingyun G, Yuanyue H, Bing G (2017) Обучение на несбалансированных по классам данных: обзор методов и приложений. Expert Syst Appl 73:220–239
Статья
Google ученый
Мних В., Кавукчуоглу К., Сильвер Д., Грейвс А., Антоноглу И., Вирстра Д., Ридмиллер М. (2013) Игра в atari с глубоким обучением с подкреплением. архив: 1312.5602
Gu S, Holly E, Lillicrap T, Levine S (2017) Глубокое обучение с подкреплением для роботизированных манипуляций с асинхронными обновлениями вне политики.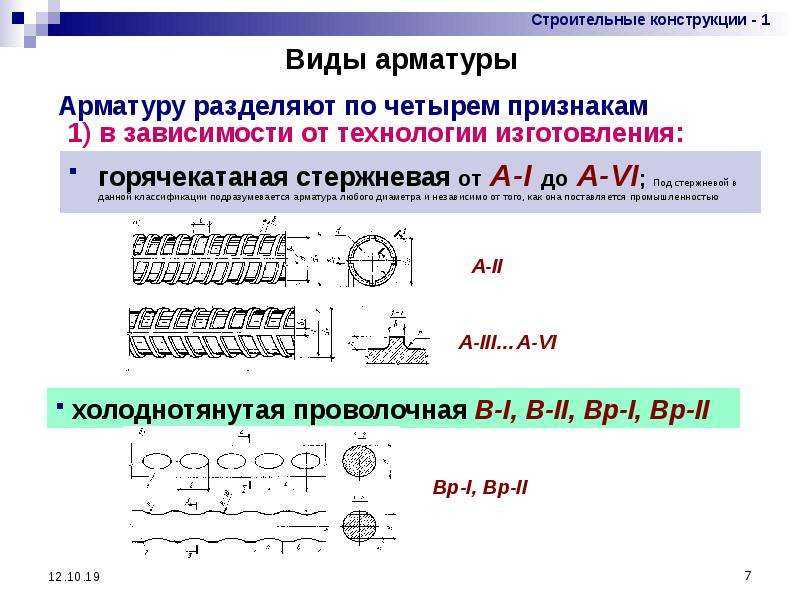 В: Международная конференция IEEE по робототехнике и автоматизации (ICRA), 2017 г., IEEE, стр. 3389–3396
В: Международная конференция IEEE по робототехнике и автоматизации (ICRA), 2017 г., IEEE, стр. 3389–3396
Чжао С., Чжан Л., Дин З., Инь Д., Чжао И., Тан Дж. (2017) Глубокое обучение с подкреплением для списка- мудрые рекомендации. архив: 1801.00209
Feng J, Huang M, Zhao L, Yang Y, Zhu X (2018) Обучение с подкреплением для классификации отношений на основе зашумленных данных. В: Труды AAAI
Мартинес С., Перрин Г., Рамассо Э., Ромбаут М. (2018) Подход к глубокому обучению с подкреплением для ранней классификации временных рядов. В: EUSIPCO, 2018
Drummond C, Holte RC, et al. (2003) С4. 5, дисбаланс классов и чувствительность к затратам: почему недостаточная выборка побеждает избыточную выборку. В: Семинар по обучению на несбалансированных наборах данных II, том 11, Citeseer, стр. 1–8
Хань Х., Ван Уай, Мао БХ (2005) Пограничный удар: новый метод избыточной выборки при обучении несбалансированным наборам данных. В: Международная конференция по интеллектуальным вычислениям, Springer, стр. 878–887
В: Международная конференция по интеллектуальным вычислениям, Springer, стр. 878–887
Мани I (2003) И Чжан, известный подход к несбалансированному распределению данных: тематическое исследование, связанное с извлечением информации. В: Материалы семинара по обучению на несбалансированных наборах данных, том 126
Batista GE, Prati RC, Monard MC (2004) Исследование поведения нескольких методов балансировки обучающих данных машинного обучения. Информационный бюллетень исследований ACM SIGKDD 6 (1): 20–29
Артикул
Google ученый
Аккаси А., Вароглу Э., Димилилер Н. (2017) Сбалансированная недостаточная выборка: новый метод недостаточной выборки на основе предложений для улучшения распознавания именованных объектов в химических и биомедицинских текстах. Appl Intell, стр. 1–14
Гупта Д., Ричхария Б. (2018) Метод двойных опорных векторов на основе нечетких наименьших квадратов на основе энтропии для изучения дисбаланса классов. Приложение Intell 48(11):4212–4231
(2018) Метод двойных опорных векторов на основе нечетких наименьших квадратов на основе энтропии для изучения дисбаланса классов. Приложение Intell 48(11):4212–4231
Статья
Google ученый
Wu G, Chang EY (2005) Kba: Выравнивание границ ядра с учетом несбалансированного распределения данных. IEEE Trans Knowl Data Eng 17(6):786–795
Статья
Google ученый
Тан Ю., Чжан Ю.-К., Чавла Н.В., Крассер С. (2009) Моделирование Svms для сильно несбалансированной классификации. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) 39(1):281–288
Статья
Google ученый
Su C, Cao J (2018) Улучшение ленивого дерева решений для несбалансированной классификации с использованием нечувствительных к перекосу критериев. Applied Intelligence
 «>
«>Zadrozny B, Elkan C (2001) Изучение и принятие решений, когда затраты и вероятности неизвестны. В: Материалы седьмой Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных, ACM, стр. 204–213
Задрозный Б., Лэнгфорд Дж., Эйб Н. (2003) Чувствительное к затратам обучение путем взвешивания пропорционального стоимости примера. В: ICDM, 2003 г., Третья международная конференция IEEE по интеллектуальному анализу данных, 2003 г., IEEE, стр. 435–442
Чжоу Z-H, Liu X-Y (2006) Обучение нейронных сетей, чувствительных к затратам, с помощью методов, решающих проблему дисбаланса классов. IEEE Trans Knowl Data Eng 18(1):63–77
Статья
MathSciNet
Google ученый
Кравчик Б., Возняк М. (2015) Чувствительная к стоимости нейронная сеть с порогом перемещения на основе roc для несбалансированной классификации. В: Международная конференция по интеллектуальной инженерии данных и автоматизированному обучению, Springer, стр. 45–52 9.0004
В: Международная конференция по интеллектуальной инженерии данных и автоматизированному обучению, Springer, стр. 45–52 9.0004
Чен Дж., Цай С.А., Мун Х., Ан Х., Янг Дж., Чен С.Х. (2006) Корректировка порога принятия решения в прогнозировании класса. SAR QSAR Environ Res 17(3):337–352
Статья
Google ученый
Yu H, Sun C, Yang X, Yang W, Shen J, Qi Y (2016) Odoc-elm: Оптимальное решение выводит машину экстремального обучения на основе компенсации для классификации несбалансированных данных. Основанная на знаниях система 92:55–70
Статья
Google ученый
Тинг К.М. (2000) Сравнительное исследование экономичных алгоритмов повышения. В: Материалы 17-й Международной конференции по машинному обучению Citeseer
Яниш Дж., Певно Т., Лисо В. (2017) Классификация с дорогостоящими функциями с использованием глубокого обучения с подкреплением. архив: 1711.07364
архив: 1711.07364
Wang S, Liu W, Wu J, Cao L, Meng Q, Kennedy PJ (2016) Обучение глубоких нейронных сетей на несбалансированных наборах данных в Neural Networks (IJCNN). В: 2016 Международная совместная конференция по. IEEE, стр. 4368–4374
Huang C, Li Y, Change Loy C, Tang X (2016) Изучение глубокого представления для несбалансированной классификации. В: Материалы конференции IEEE по компьютерному зрению и распознаванию образов, стр. 5375–5384
Yan Y, Chen M, Shyu ML, Chen SC (2015)Глубокое обучение для несбалансированной классификации мультимедийных данных. В: Мультимедиа (ISM). В: 2015 Международный симпозиум IEEE по. IEEE, стр. 483–488
Хан С.Х., Хаят М., Беннамун М., Сохел Ф.А., Тогнери Р. (2018) Чувствительное к стоимости изучение глубоких представлений признаков на основе несбалансированных данных. IEEE Trans Neural Network Learning Syst 29(8):3573–3587
Артикул
Google ученый
 «>
«>Донг К., Гонг С., Чжу С. (2018) Несбалансированное глубокое обучение путем постепенного исправления класса меньшинства. IEEE Transactions on Pattern Analysis and Machine Intelligence
Wiering MA, van Hasselt H, Pietersma AD, Schomaker L (2011) Алгоритмы обучения с подкреплением для решения задач классификации. В: Симпозиум IEEE по адаптивному динамическому программированию и обучению с подкреплением (ADPRL), 2011 г., IEEE, стр. 9.1–96
Чжан Т., Хуанг М., Чжао Л. (2018) Обучение структурированному представлению для классификации текста с помощью обучения с подкреплением. AAAI
Лю Д., Цзян Т. (2018) Глубокое обучение с подкреплением для сегментации и классификации хирургических жестов. архив: 1806.08089
Zhao D, Chen Y, Lv L (2017) Глубокое обучение с подкреплением и визуальным вниманием для классификации транспортных средств. IEEE Trans Cogn Develop Syst 9(4):356–367
Статья
Google ученый
 «>
«>Абди Л., Хашеми С. (2014) Подход к сокращению ансамбля, основанный на обучении с подкреплением в присутствии несбалансированных данных нескольких классов. В: Proceedings of the Third International Conference on Soft Computing for Problem Solving, Springer, pp 589–600
Dixit AK, Sherrerd JJ, et al. (1990) Оптимизация в экономической теории. Издательство Оксфордского университета по запросу
Лин Т.Ю., Гоял П., Гиршик Р., Хе К., Доллар П. (2017) Потеря фокуса при обнаружении плотных объектов. В: Материалы Международной конференции IEEE по компьютерному зрению, стр. 29.80–2988
Gu Q, Zhu L, Cai Z (2009) Меры оценки эффективности классификации несбалансированных наборов данных. В: Международный симпозиум по интеллектуальным вычислениям и приложениям, Springer, стр. 461–471
Bengio Y (2012) Практические рекомендации по градиентному обучению глубоких архитектур.
