Вм 127м технические характеристики: ВМ127М технические характеристики | Станок фрезерный вертикальный с УЦИ
Содержание
ВМ127М технические характеристики | Станок фрезерный вертикальный с УЦИ
Технические характеристики фрезерного станка ВМ127М реализуют возможность механической обработки деталей из чугуна методом фрезерования.
Наименование характеристики | Ед. изм. | Параметры |
Класс точности по ГОСТ 8-82 |
| Н |
Стол | ||
Размеры рабочей поверхности стола (Д х Ш) | мм | 1600 х 400 |
Число Т-образных пазов |
| 3 |
Перемещение стола |
|
|
продольное (Х) | мм | 1010 |
поперечное (Y) | мм | 320 |
вертикальное (Z) | мм | 420 |
Количество подач стола |
| 18 |
Пределы подач стола |
|
|
Продольных | мм/мин | 25…1250 |
Поперечных | мм/мин | 25…1250 |
Вертикальных | мм/мин | 8,3…416,6 |
Расстояния от торца шпинделя до стола | мм | 30…500 |
Расстояние от оси шпинделя до вертикальных направляющих станины | мм | 420 |
Скорость быстрого перемещения стола |
|
|
Продольного и поперечного | мм/мин | 3000 |
Вертикального | мм/мин | 1000 |
Наибольшая масса обрабатываемой детали (с приспособлениями) | кг | 300 |
Перемещение стола на одно деление лимба |
|
|
продольное, поперечное | мм | 0,05 |
вертикальное | мм | 0,05 |
Перемещение стола на один оборот лимба |
|
|
продольное | мм | 4 |
поперечное | мм | 6 |
вертикальное | мм | 2 |
Шпиндель | ||
Количество ступеней скоростей шпинделя |
| 18 |
Внутренний конус шпинделя |
| 50 |
Частота вращения шпинделя | об/мин | 40…2000 |
Наибольшее осевое перемещение пиноли шпинделя | мм | 80 |
Перемещение пиноли на один оборот лимба | мм | 4 |
Перемещение пиноли на одно деление лимба | мм | 0,05 |
Наибольший угол поворота шпиндельной головки | град | ±45 |
Механика станка | ||
Выключающие упоры подачи |
| Есть |
Блокировка ручной и механической подач |
| Есть |
Блокировка рукояток |
| Есть |
Блокировка раздельного включения подачи |
| Есть |
Автоматическая прерывная подача |
|
|
продольная |
| Есть |
поперечная и вертикальная |
| Нет |
Торможение шпинделя |
| Есть |
Предохранение от перегрузки (муфта) |
| Есть |
Электрооборудование | ||
Количество электродвигателей на станке (с электронасосом) |
| 4 |
Главный привод станка |
|
|
Мощность | кВт | 11 |
Электродвигатель привода подач |
|
|
Мощность | кВт | 2,1 |
Электронасос подачи охлаждающей жидкости |
|
|
Мощность | кВт | 0,12 |
Тип |
| П-32МС10 |
Производительность | л/мин | 22 |
Электродвигатель зажима инструмента |
|
|
Тип |
| АИР56В2У3 |
Габариты и масса | ||
Габаритные размеры станка |
|
|
длина | мм | 2560 |
ширина | мм | 2260 |
высота | мм | 2500 |
Масса станка | кг | 4250 |
Цена на вертикально-фрезерный станок вм127м
Цена на 05. 10.2022
10.2022
Под заказ
Производитель:
Россия
Вертикальные фрезерные машины востребованы предприятиями, занимающимися выпуском деталей, изделий, конструкций в серийном масштабе. Покупка фрезерного станка вм127м обеспечит возможность оперативно осуществлять качественное формирование фрез разной формы на деталях из цветных и черных металлических сплавов.
С помощью вертикально фрезерного станка вм127 можно нарезать не только прямолинейные фрезы с простым и фасонным сечением, но и винтовые фаски, для создания которых агрегат оборудован поворотным столом.
- Благодаря варьированию величины передаваемой приводом энергии создаются условия для полноценного использования всего диапазона технических возможностей вертикально фрезерного станка вм127.
- Простая конструкция позволяет в краткие сроки проводить переналадку и смену оснастки, не вызывают затруднений освоение, эксплуатация и обслуживание.
- Смазка рабочих систем и узлов осуществляется автоматически, что существенно продлевает срок безупречной работоспособности фрезерной машины.

Немалым достоинством является стоимость, предложенная нашей фирмой за фрезерный станок вм 127 – цена производительного оборудования быстро окупится при рациональной нагрузке.
ТЕХНИЧЕСКИЕ ХАРАКТЕРИСТИКИ ФРЕЗЕРНОГО СТАНКА ВМ127М
|
Характеристика |
ВМ127М |
|---|---|
|
Размеры рабочей поверхности стола (ширина х длина), мм |
400 х 1600 |
|
Число Т-образных пазов |
3 |
|
Максимальная нагрузка на стол (по центру), кг |
800 |
|
Наибольшее перемещение стола, мм: | |
|
— продольное механическое/ручное |
1010/1010 |
|
— поперечное механическое/ручное |
300(280)/320 |
|
— вертикальное механическое/ручное |
400/420 |
|
Перемещение стола на одно деление лимба (продольное поперечное, вертикальное), мм |
0,05 |
|
Перемещение стола на один оборот лимба, мм: | |
|
— продольное |
4 |
|
— поперечное |
6 |
|
— вертикальное |
2 |
|
Точность линейных координатных перемещений стола (при оснащении БЦИ) , мкм: | |
|
— продольное (координата “Х”) |
50 |
|
— поперечное ( координата “Y”) |
50 |
|
— вертикальное (координата “Z”) |
50 |
|
Конус шпинделя |
АТ50 |
|
Наибольшее перемещение пиноли шпинделя, мм |
80 |
|
Наибольшее и наименьшее перемещение от торца шпинделя до рабочей | |
|
поверхности стола при ручном перемещении, мм |
30-500* |
|
Расстояние от оси шпинделя до вертикальных направляющих станины, мм |
420 |
|
Угол поворота шпиндельной головки, град. 
|
±45 |
|
Количество скоростей шпинделя |
18 |
|
Пределы бесступенчатой регулировки скорости подач, мм/мин : | |
|
— продольной рабочая/ускоренная |
25-1250/3000 |
|
— поперечной рабочая/ускоренная |
25-1250/3000 |
|
— вертикальной рабочая/ускоренная |
8,3-416,6/1000 |
|
Мощность электродвигателей, кВт: | |
|
— главного движения |
11 |
|
— привода подач |
2,1 |
|
Мощность электронасоса охлаждающей жидкости, к Вт |
0,12 |
|
Производительность электронасоса охлаждающей жидкости, л/мин |
22 |
|
Класс точности станка |
Н |
|
Габариты, мм |
2560х2260х2500 |
Цветная электросхема фрезерного станка ВМ 127М
Собрать электрическую схему своими руками совсем несложно, если вы обладаете должным уровнем знаний по электротехнике, даже отличным знанием электротехники.
Как ы понимаете это дело не для новичков и тех, кто не понимает ничего в электрических схемах. Разберем этапы работы на примере фрезерного станка и узнаем что такое принципиальная электрическая схема фрезерного станка.
Включение, выключение и торможение шпинделя
Для включения шпинделя необходимо нажать кнопку SB7, включаются пускатель KM1 и реле времени KT1, KT2. Пускатель KM1 подает напряжение 380 В на двигатель M1, а KT2 своими замыкающими контактами блокирует выключатель SB7.
Для выключения шпинделя необходимо нажать кнопку SB4, отключаются пускатель KM1 и реле времени KT1, KT2. Через 1, 2 с включится пускатель K2, который своими замыкающими контактами включит динамическое торможение шпинделя. Через 5, 6 с замыкающие контакты реле времени KT2 выключают пускатель K2, а K2 соответственно отключит динамическое торможение шпинделя.
Электропривод подач
Электропривод подач представляет собой электромеханическую систему. Включение и отключение подачи осуществляется рукоятками, которые имеют три фиксированных положения, а также выключателями SQ6, SQ8 для продольной; SQ5, SQ7 для вертикальной или поперечной подачи.
Включение и отключение подачи осуществляется рукоятками, которые имеют три фиксированных положения, а также выключателями SQ6, SQ8 для продольной; SQ5, SQ7 для вертикальной или поперечной подачи.
Быстрый ход подачи происходит при нажатии кнопки SB9, включается пускатель K3 и электромагнит быстрого хода YA. На станке электрической блокировкой исключается возможность одновременного включения продольной и поперечной или вертикальной подачи.
Принцип действия
Принцип действия основан на отображении работы каких-либо конечных приемников электрической энергии от работы или взаимодействия остальных компонентов, входящий в данную принципиальную электрическую схему фрезерного станка.
На нашем примере — это отработка магнитных пускателей в зависимости от положения рукояток управления, положения концевых выключателей, состояния тепловых реле и т. п.
Принципиальная электрическая схема управления ЭП вертикально-фрезерного станка
Функциональное назначение
KM1 — подключает напряжение 380 В к приводу главного движения M1 и двигателю насоса охлаждения M2; KM2, KM3 — подключают напряжение 380 В к приводу подач M3; KM4, KM5 — подключают напряжение 380 В к двигателю механизма крепления инструмента; K2 — включает динамическое торможение шпинделя; K3 — включает быстрый ход привода подач и импульсное включение привода главного движения при переключении скоростей шпинделя; K5 — подготавливает цепь включения привода главного движения после зажима инструмента: KT1 — задает время вращения шпинделя после его выключения до включения торможения.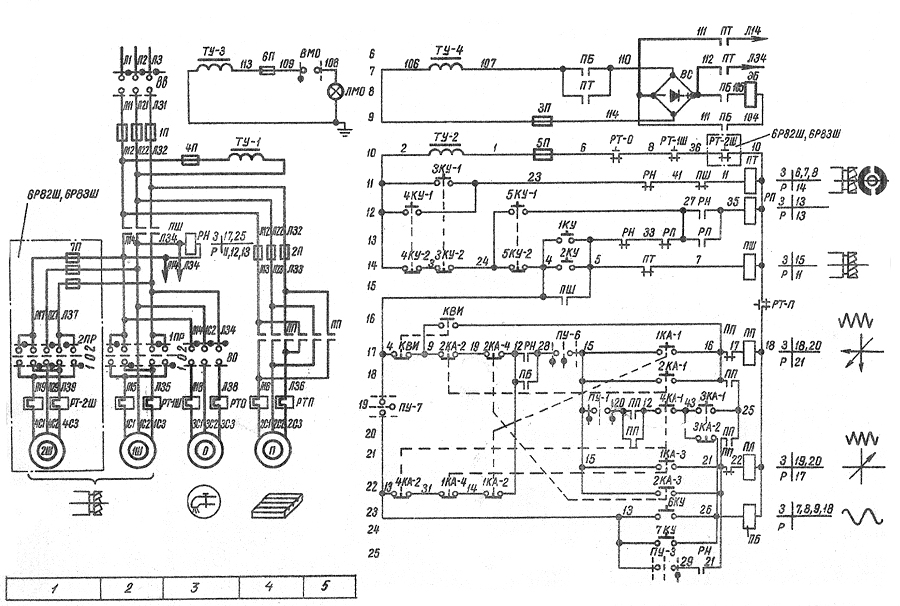 KT2 — задает время торможения шпинделя; QF1 — вводной выключатель; QS2 — переключатель насоса охлаждения; SQ3 — выключатель импульсного включения привода подач при переключении скоростей; SQ5, SQ7 — выключатель привода стола «вперед-назад» и «вверх-вниз»; SQ6, SQ8 — выключатель привода стола «влево-вправо»; SQ10 — выключатель блокировки главного движения и подач при зажиме инструмента.
KT2 — задает время торможения шпинделя; QF1 — вводной выключатель; QS2 — переключатель насоса охлаждения; SQ3 — выключатель импульсного включения привода подач при переключении скоростей; SQ5, SQ7 — выключатель привода стола «вперед-назад» и «вверх-вниз»; SQ6, SQ8 — выключатель привода стола «влево-вправо»; SQ10 — выключатель блокировки главного движения и подач при зажиме инструмента.
Зажим инструмента
Для зажима инструмента необходимо тумблер SA3 (на боковом пульте) установить в положение «Зажим» и удерживать рукой. При этом срабатывает пускатель КМ4, который подает напряжение на двигатель механизма зажима инструмента М4. Идет зажим инструмента. Прощелкивание муфты в механизме зажима свидетельствует об окончании зажима инструмента. Микровыключатель SQ10 своими контактами включает пускатель К5.1, который становится на самопитание, отключает двигатель М4 и подготовит цепь пуска двигателя шпинделя.
Разжим инструмента: тумблер SA3 установить в положение «Разжим» и удерживать рукой. При этом срабатывают пускатели КМ5.1. Пускатель КМ5.3. подает напряжение на двигатель М4. Идет отжим инструмента. Окончание отжима инструмента контролируется визуально. Примечание: Во избежание получения травм при разжиме инструмента пуск шпинделя блокируется замыкающими контактами К5 При вращающемся шпинделе разжим инструмента заблокирован размыкающими контактами К5 в цепи включения двигателя М4 При зажиме и разжиме инструмента, с целью исключения проворачивания шпинделя, необходимо установить низкую скорость оборотов шпинделя (не выше 400об/мин)
При этом срабатывают пускатели КМ5.1. Пускатель КМ5.3. подает напряжение на двигатель М4. Идет отжим инструмента. Окончание отжима инструмента контролируется визуально. Примечание: Во избежание получения травм при разжиме инструмента пуск шпинделя блокируется замыкающими контактами К5 При вращающемся шпинделе разжим инструмента заблокирован размыкающими контактами К5 в цепи включения двигателя М4 При зажиме и разжиме инструмента, с целью исключения проворачивания шпинделя, необходимо установить низкую скорость оборотов шпинделя (не выше 400об/мин)
Фрезерный станок для производства рекламы с ЧПУ
Особенности 1. Фрезерный станок для производства рекламы SK1218 имеет современный дизайн. Наш фрезерный станок для производства рекламы отличается высокой точностью работы, высокой жёсткостью и низким уровнем производственных ошибок. 2. Наш фрезерный станок имеет совершенную конструкцию с шариковым винтом высокой точности и мощным диском, что позволило добиться очень высокой точности гравировки. 3. Наш фрезерные станок для производства рекламы с ЧПУ SK1218 удобен в обслуживании. В своей конструкции, он использует модульную структуру, которая позволяет гарантировать быструю разборку и сборку станка, что значительно облегчает ремонтные работы. 4. Основные конструкционные детали нашего станка произведены иностранными компаниями, что позволяет гарантировать их качество.
3. Наш фрезерные станок для производства рекламы с ЧПУ SK1218 удобен в обслуживании. В своей конструкции, он использует модульную структуру, которая позволяет гарантировать быструю разборку и сборку станка, что значительно облегчает ремонтные работы. 4. Основные конструкционные детали нашего станка произведены иностранными компаниями, что позволяет гарантировать их качество.
Применение Фрезерный станок для производства рекламы с ЧПУ SK1218 имеет широкую сферу применения, например, используется в процессе производства рекламных щитов, при строительных работах, при резки акрила, при термическом формировании моделей, при изготовлении изделий из дерева и т.д. Наш фрезерный станок для производства рекламы может обрабатывать железо, медь, алюминий, пластик и многие другие материалы.
Технические параметры фрезерного станка для производства рекламы SK1218 Модель Фрезерный станок SK1218 Рабочая зона XY 1200*1800мм Рабочая зона Z 80мм Мотор шпинделя 1.5кВт или 2.2кВт Рабочий режим Шаговый Система управления DSP или PCI система контроля Точность позиционирования 0. 02/300мм Точность перемещения 0.01мм Мак. скорость 0 — 4,000мм/мин Мак.высота подачи 120мм Программное обеспечение Тип 3, ArtCAM, NC Studio Гравирующий инструмент G код x, u00 x, mmg x, plt Движение X Y Шариковый винт Операционное напряжение AC220В/ 50-60Гц Операционная температура 0-45º Операционная влажность 35%-70% Вес нетто 550кг Размер упаковки 250*175*150см
02/300мм Точность перемещения 0.01мм Мак. скорость 0 — 4,000мм/мин Мак.высота подачи 120мм Программное обеспечение Тип 3, ArtCAM, NC Studio Гравирующий инструмент G код x, u00 x, mmg x, plt Движение X Y Шариковый винт Операционное напряжение AC220В/ 50-60Гц Операционная температура 0-45º Операционная влажность 35%-70% Вес нетто 550кг Размер упаковки 250*175*150см
Электропривод подач
Электропривод подач представляет собой электромеханическую систему. Включение и отключение подачи осуществляется рукоятками, которые имеют три. фиксированных положения, а также выключателями SQ6, SQ8 для продольной; SQ5, SQ7 для вертикальной или поперечной подачи.
Быстрый ход подачи происходит при нажатии кнопки SВ9, включается пускатель КЗ и электромагнит быстрого хода УА. На станке электрической блокировкой исключается возможность одновременного включения продольной и поперечной или вертикальной подачи.
Виды
Различают такие виды электросхем:
- структурная, которая определяет взаимосвязь частей электрооборудования;
- функциональная, определяющая электрические процессы в отдельном узле, полностью для чпу станка;
- принципиальная, в которой отражены все элементы, дается представление относительно принципа работы;
- соединения монтажного плана для подключений к электросети;
- расположения частей электроустройств, проводниковой и кабельной продукции.

Техническая документация устройства обычно содержит принципиальную электросхему и схемы расположения электрооборудования. Ее выполняют, не придерживаясь масштаба и не указывая, как в действительности расположены отдельные элементы.
Регулировка цепи торможения шпинделя
Регулировка цепи торможения производится после замены или ремонта реле времени КТ1, КТ2, а также в случае, когда временные характеристики цепи торможения не соответствуют указанным в п. 7.6.5.
Для проведения регулировки необходимо: подать питание на станок включить шпиндель
Одновременно с выключателем шпинделя включить секундомер и остановить его при срабатывании К2. Если зафиксированное время превышает I сек., повернуть регулятор реле времени КТ1 по часовой стрелке. Повторить включение и выключение шпинделя, добиваясь включения пускателя К2 через 1 сек. Если пускатель К2 срабатывает менее , чем 1 сек. после отключения шпинделя, тогда регулятор реле КТ1 повернуть против часовой стрелки. Регулировку реле КТ2 проводить аналогично КТ1. Выключить шпиндель станка, одновременно с нажатием кнопки SB4, запустить секундомер и остановить его после остановки шпинделя. Зафиксированное время не Должно быть более 6 сек.
Регулировку реле КТ2 проводить аналогично КТ1. Выключить шпиндель станка, одновременно с нажатием кнопки SB4, запустить секундомер и остановить его после остановки шпинделя. Зафиксированное время не Должно быть более 6 сек.
Мини фрезерный станок с ЧПУ
Разрезание различных материалов с помощью движущей фрезы производится на фрезерных станках, которые представлены многими видами. Это горизонтальный, широкоуниверсальный, консольный вертикальный, безконсольный, продольный станок. Управление на них производится вручную, автоматизировано с помощью Числового программного обеспечения (ЧПУ). Станки, имеющие ЧПУ, отличаются высокой скоростью, точностью изготовления деталей. При работе на фрезерном станке с ЧПУ на обработку детали требуется значительно меньше времени, чем при работе на аналогах с ручным или автоматизированным управлением.
Мини фрезерный станок с ЧПУФрезерование корпусов металлических деталей на мелкосерийном производстве, в ремонтных мастерских, при выпуске деталей небольших размеров, в автосервисах, школьных мастерских нет необходимости иметь стационарный фрезерный станок. Вполне подойдет мини фрезерный станок с ЧПУ. Это настольный станок, имеющий прекрасные технические характеристики и приемлемую в сравнении с другими станками цену. Они имеют небольшие габариты, просты в конструкции. При установке такого станка не требуется прокладывать усиленный кабель для электропитания. Станку требуется питание 220В, а не 380В.
Вполне подойдет мини фрезерный станок с ЧПУ. Это настольный станок, имеющий прекрасные технические характеристики и приемлемую в сравнении с другими станками цену. Они имеют небольшие габариты, просты в конструкции. При установке такого станка не требуется прокладывать усиленный кабель для электропитания. Станку требуется питание 220В, а не 380В.
Мини фрезерный станок с ЧПУНебольшой станок дает возможность качественно выполнять раскрой материала, изготавливать изделия сложной плоской и пространственной формы. Человеческий фактор уходит на последнее место, так как вся работа ведется на основе программ.
Мини фрезерный станок с ЧПУ выполняется с достаточно жесткой станиной, с точными узлами привода для устранения люфтов и зазоров. Материалы на изготовление ходовой части используют износоустойчивые.
Система электронного оборудования защищает работающего от возможных ошибок, как неправильная последовательность или иная ошибка предупреждается подачей звукового оповещающего сигнала. Поэтому брак при работе практически исключен. Станки с ЧПУ оснащены системой, которая заранее просматривает процесс, проводит анализ, при необходимости сокращает движение. Мини фрезерный станок с ЧПУАвтоматическая система, поддерживающая двойной проход, позволяет добиться высокого качества при работе с МДФ, пластиком. Пакетная обработка повышает отдачу при работе с партиями изделий. При этом значительно сокращается время. Для небольших мастерских, гаражей подойдет мини фрезерный станок с ЧУП со стандартной комплектацией. Размеры рабочего поля стола обычно имеют от 300х300, 400х400, 600х900 миллиметров.
Поэтому брак при работе практически исключен. Станки с ЧПУ оснащены системой, которая заранее просматривает процесс, проводит анализ, при необходимости сокращает движение. Мини фрезерный станок с ЧПУАвтоматическая система, поддерживающая двойной проход, позволяет добиться высокого качества при работе с МДФ, пластиком. Пакетная обработка повышает отдачу при работе с партиями изделий. При этом значительно сокращается время. Для небольших мастерских, гаражей подойдет мини фрезерный станок с ЧУП со стандартной комплектацией. Размеры рабочего поля стола обычно имеют от 300х300, 400х400, 600х900 миллиметров.
Фрезерная и токарная обработка в Москве
Токарная обработка – это процесс механической обработки цилиндрических поверхностей деталей резанием. При токарной обработке режущий инструмент совершает линейно-поступательные движения, сама же заготовка – вращательное движение. Основные виды токарной обработки: обточка наружных и внутренних цилиндрических, конических и фасонных поверхностей, растачивание, прорезание канавок, нарезание резьбы, торцевание, сверление, зенкерование и другие. Режущим инструментом служат резцы, сверла, зенкера.
Режущим инструментом служат резцы, сверла, зенкера.
Фрезерная обработка – это процесс механической обработки деталей, при котором режущий инструмент совершает вращательное движение, а обрабатываемая заготовка – поступательное. Существует два основных вида фрезерования: цилиндрическое и торцовое. Фрезерную обработку применяют для плоского и фасонного строгания кромок изделия, формирования прямых и винтовых канавок, нарезания резьбы, шлиц, зубчатых колес, сверлильных и расточных работ. Режущим инструментом служат различные виды фрез, прорезные диски, плоские ножи.
Мы предлагаем широкий спектр услуг по фрезерной и токарной обработке металлов: токарные и фрезерные работы, сверление, растачивание, нарезание резьбы, зубчатых колес, вырубку контура, вытачивание канавок, шлифовку, обработку внутренней поверхности, а также продольно-строгальную обработку крупногабаритных заготовок и другие работы.
Наше оборудование
На нашем производстве используется парк универсальных металлообрабатывающих станков:
- вертикальный консольно-фрезерный станок ВМ127М
- вертикальный консольно-фрезерный станок 6Т13УП
- горизонтально-фрезерный станок 6М82Г
- горизонтально-фрезерный станок 6Р82Г
- горизонтально-фрезерный станок 6Р81
- токарно-винторезный станок CU-500M
- токарно-винторезный станок CU-730
- токарно-винторезный станок 16К25
- токарно-винторезный станок 16К20
- токарно-винторезный станок 1М63Ф101
- токарно-карусельный станок 1541
- продольно-строгальный станок 7231А
- поперечно-строгальный станок 7Б35
На нашем производстве используются также автоматизированные станки с ЧПУ для токарной обработки – токарный обрабатывающий центр с ЧПУ Samsung PL45LM и горизонтальный токарный станок с ЧПУ CJK61160.
Фрезерная обработка
Фрезерные станки предназначены для фрезерования всевозможных деталей из стали, чугуна и цветных металлов и сплавов торцевыми, концевыми, цилиндрическими, радиусными и другими фрезами. На таких станках можно обрабатывать горизонтальные, вертикальные и наклонные плоскости, пазы, углы, рамки, зубчатые колеса и т.д.
Вертикальный консольно-фрезерный станок ВМ127М
Технические характеристики станка ВМ127М
| Размеры рабочей поверхности стола, мм | 400×1600 | |
| Наибольшее перемещение стола, мм | продольное | 1000 |
| поперечное | 320 | |
| вертикальное | 420 | |
| Наибольшее перемещение пиноли шпинделя, мм | 80 | |
| Угол поворота шпиндельной головки, градусов | ±45 | |
Вертикальный консольно-фрезерный станок 6Т13УП
Технические характеристики станка 6Т13УП
| Класс точности по ГОСТ 8-82 | Н | |
| Размеры рабочей поверхности стола, мм | 400×1600 | |
| Наибольшее перемещение стола, мм | продольное | 1010 |
| поперечное | 400 | |
| вертикальное | 420 | |
Горизонтально-фрезерный станок 6Р82Г
Технические характеристики станка 6Р82Г
| Класс точности | Н | |
| Размеры рабочей поверхности стола, мм | 1250×320 | |
| Наибольшее перемещение стола, мм | продольное | 800 |
| поперечное | 250 | |
| вертикальное | 420 | |
Токарная обработка
Токарно-винторезные станки являются наиболее универсальными станками токарной группы и используются главным образом в условиях единичного и серийного производства.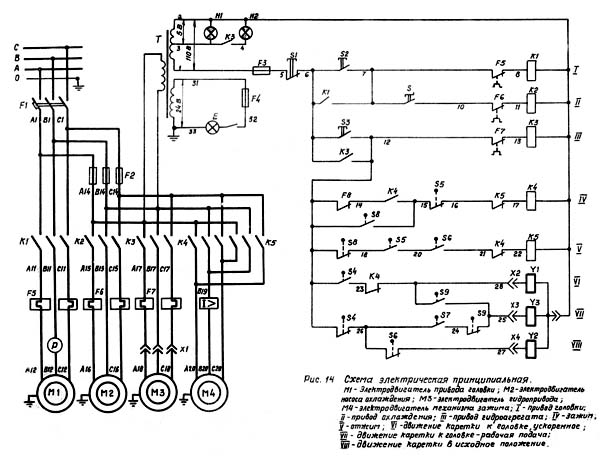 Позволяют выполнять все виды токарных и резьбонарезных работ.
Позволяют выполнять все виды токарных и резьбонарезных работ.
Токарно-винторезный станок CU-500M
Технические характеристики станка CU-500M
| Наибольший диаметр заготовки обрабатываемой над станиной, мм | 500 |
| Наибольший диаметр заготовки обрабатываемой над суппортом, мм | 300 |
| РМЦ, мм | 2000 |
Токарно-винторезный станок CU-730
Технические характеристики станка CU-730
| Наибольший диаметр заготовки обрабатываемой над станиной, мм | 730 |
| Наибольший диаметр заготовки обрабатываемой над суппортом, мм | 500 |
| РМЦ, мм | 3000 |
Токарно-винторезный станок 16К25
Технические характеристики станка 16К25
| Наибольший диаметр заготовки обрабатываемой над станиной, мм | 500 |
| Наибольший диаметр заготовки обрабатываемой над суппортом, мм | 290 |
| РМЦ, мм | 1000 |
Продольно-строгальная обработка
Обработка крупногабаритных заготовок с разноориентированными поверхностями выполняется продольно-строгальной операцией на продольно-строгальном станке. Эта операция особенно важна для заготовок с широкими плоскостями, с которых сложно снимать припуск фрезерованием. Заготовка прочно закрепляется на консольном столе станка, который совершает рабочее возвратно-поступательное движение. Строгальный резец установлен на суппорте, который совершает движение подачи. Снятие заданного припуска происходит при движении стола вперед. После обратного хода стола резец смещается на определенную величину для снятия нового припуска. Сила и глубина врезания резца в заготовку, скорость рабочего движения устанавливается в соответствии с техническим заданием.
Эта операция особенно важна для заготовок с широкими плоскостями, с которых сложно снимать припуск фрезерованием. Заготовка прочно закрепляется на консольном столе станка, который совершает рабочее возвратно-поступательное движение. Строгальный резец установлен на суппорте, который совершает движение подачи. Снятие заданного припуска происходит при движении стола вперед. После обратного хода стола резец смещается на определенную величину для снятия нового припуска. Сила и глубина врезания резца в заготовку, скорость рабочего движения устанавливается в соответствии с техническим заданием.
Продольно-строгальный станок 7231А
Технические характеристики станка 7231А
| Максимальная длина заготовки, мм | 3000 |
| Максимальная ширина заготовки, мм | 1000 |
| Максимальная высота заготовки, мм | 830 |
Преимущества работы с Механическим заводом «Спецмашмонтаж»
Важным преимуществом работы с нами является широкий спектр предоставляемых нашим заводом услуг по обработке металла. Наше предприятие имеет оборудование для резки, рубки, гибки листового и профильного проката, сварки, токарных, фрезерных, окрасочных и других операций. Фрезерная и токарная обработка может быть только частью технологических операций, необходимых заказчику. Обратившись к нам, Вы получите требуемый набор операций для производства конечных изделий.
Наше предприятие имеет оборудование для резки, рубки, гибки листового и профильного проката, сварки, токарных, фрезерных, окрасочных и других операций. Фрезерная и токарная обработка может быть только частью технологических операций, необходимых заказчику. Обратившись к нам, Вы получите требуемый набор операций для производства конечных изделий.
Механический завод «Спецмашмонтаж» предлагает полный комплекс услуг:
Проектирование металлоконструкций
Металлообработка
Изготовление металлоконструкций
Доставка
Монтаж металлоконструкций
Неразрушающий контроль
Любую интересующую Вас информацию по услугам фрезерной и токарной обработки можно получить у сотрудников нашей компании, связавшись с нами по телефону +7(495)583-78-86, по электронной почте Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра. или воспользовавшись формой обратной связи.
Если Вы хотите рассчитать стоимость услуги, пожалуйста, заполните форму обратной связи и приложите чертежи деталей. Наш менеджер свяжется с вами и предоставит предварительный расчет стоимости.
Наш менеджер свяжется с вами и предоставит предварительный расчет стоимости.
Технические характеристики виртуальной машины
Технические характеристики виртуальной машины
Red Hat Enterprise
Linux 6.2 (32-разрядная версия)Ред Хэт Энтерпрайз
Linux 6.4 (32-разрядная версия)Ред Хэт Энтерпрайз
Linux 6.7 (64-разрядная версия)CentOS Linux 7.3 (64-разрядная версия)
Ред Хэт Энтерпрайз
Linux 6.2 (32-разрядная версия)
Ниже приведены характеристики BDN 2.3.0.xxx.
Версия хоста xxx.ovf ( ххх = последний
номер сборки и версии).
| Операционная система и Минимальные технические характеристики оборудования для виртуальной машины | |
| Операционная система на виртуальной машине | Red Hat Enterprise Linux 6.2 32-битный |
| Минимальные требования к установке по умолчанию |
|
| Ethernet-адаптер 0 (статический IP-адрес) /etc/sysconfig/сетевые скрипты/ifcfg-eth0 | Устройство = eth0 BOOTPRTO = нет ТИП = Ethernet HWADDR = 00:0c:29:09:a9:f2 ЗАГРУЗКА = Да Сетевая маска = 255.255.255.0 IPV6INIT = Нет |
| Ethernet-адаптер 1 (DHCP) /etc/sysconfig/сетевые скрипты/ifcfg-eth2 | Устройство = eth2 BOOTPRTO = DHCP ТИП = Ethernet HWADDR = 00:0c:29:09:a9:fc ПЕРДНС = да |
 168.1.100
168.1.100
| Процессы и полезные команды | ||
| Процесс | Каталог | Описание |
| монитор | /etc/init.d/monit | monit — утилита для управления ./монит стоп ./монитор старт ./мониторинг перезагрузки Должен быть root или суперпользователь для выполнения |
| веб-сайт | /etc/init.d/webuid | Полезные команды ./веб-стоп ./webuid начало ./webuid перезапустить Должен быть root или суперпользователь для выполнения |

Установленные пакеты
Установленные пакеты Red Hat Enterprise
Linux 6.2 (PDF)
Ред Хэт Энтерпрайз
Linux 6.4 (32-разрядная версия)
Ниже приведены характеристики BDN 2.3.0.xxx.
Версия хоста xxx.ovf ( xxx = последняя
номер сборки и версии).
| Операционная система и Минимальные технические характеристики оборудования для виртуальной машины | |
| Операционная система на виртуальной машине | Red Hat Enterprise Linux 6. 4 432-битный |
| Минимальные требования к установке по умолчанию |
|
| Ethernet-адаптер 0 (статический IP-адрес) /etc/sysconfig/сетевые скрипты/ifcfg-eth0 | УСТРОЙСТВО=eth0 ТИП=Ethernet НА ЗАГРУЗКЕ=да NM_CONTROLLED=да BOOTPROTO=нет IP-АДРЕС=192.168.1.100 ПРЕФИКС=24 DEFROUTE=да IPV4_FAILURE_FATAL=да IPV6INIT=нет ИМЯ=»Система |
| Ethernet-адаптер 1 (DHCP) /etc/sysconfig/network-scripts/ifcfg-eth2 | УСТРОЙСТВО=eth2 ТИП=Ethernet НА ЗАГРУЗКЕ=нет NM_CONTROLLED=да ЗАГРУЗКА_ПРОТО=DHCP HWADDR=00:0C:29:07:62:3A DEFROUTE=да PEERDNS=да РАСШИРЕННЫЕ МАРШРУТЫ=да IPV4_FAILURE_FATAL=да IPV6INIT=нет ИМЯ=»Система |
| Процессы и полезные команды | ||
| Процесс | Каталог | Описание |
| монитор | /etc/init. d/monit d/monit | monit — утилита для управления ./монит стоп ./монитор старт ./мониторинг перезагрузки Должен быть root или суперпользователь для выполнения |
| веб-сайт | /etc/init.d/webuid | Полезные команды ./веб-стоп ./webuid начало ./webuid перезапустить Должен быть root или суперпользователь для выполнения |

Установленные пакеты
Установленные пакеты Red Hat Enterprise
Linux 6.4 (PDF)
Ред Хэт Энтерпрайз
Linux 6.7 (64-разрядная версия)
Ниже приведены характеристики BDN 2.3.0.xxx.
Версия хоста xxx.ovf ( xxx = последняя
номер сборки и версии).
| Операционная система и Минимальные технические характеристики оборудования для виртуальной машины | |
| Операционная система на виртуальной машине | Red Hat Enterprise Linux 6.7 64-битный |
| Минимальные требования к установке по умолчанию |
|
| Ethernet-адаптер 0 (статический IP-адрес) /etc/sysconfig/сетевые скрипты/ifcfg-eth0 | УСТРОЙСТВО=eth0 ТИП=Ethernet НА ЗАГРУЗКЕ=да NM_CONTROLLED=да BOOTPROTO=нет IP-АДРЕС=192. ПРЕФИКС=24 DEFROUTE=да IPV4_FAILURE_FATAL=да IPV6INIT=нет ИМЯ=»Система |
| Ethernet-адаптер 1 (DHCP) /etc/sysconfig/network-scripts/ifcfg-eth2 | УСТРОЙСТВО=eth2 ТИП=Ethernet НА ЗАГРУЗКЕ=нет NM_CONTROLLED=да ЗАГРУЗКА_ПРОТО=DHCP HWADDR=00:0C:29:5A:24:35 DEFROUTE=да PEERDNS=да РАСШИРЕННЫЕ МАРШРУТЫ=да IPV4_FAILURE_FATAL=да IPV6INIT=нет ИМЯ=»Система |
 168.1.100
168.1.100
| Процессы и полезные команды | ||
| Процесс | Каталог | Описание |
| монитор | /etc/init.d/monit | monit — утилита для управления ./монит стоп ./монитор старт ./мониторинг перезагрузки Должен быть root или суперпользователь для выполнения |
| веб-сайт | /etc/init.d/webuid | Полезные команды ./веб-стоп ./webuid начало ./webuid перезапустить Должен быть root или суперпользователь для выполнения |
 Monit проводит автоматическое техническое обслуживание и ремонт, а также
Monit проводит автоматическое техническое обслуживание и ремонт, а такжеУстановленные пакеты
Установленные пакеты Red Hat Enterprise
Linux 6. 7 (PDF)
7 (PDF)
CentOS Linux 7.3 (64-разрядная версия)
Ниже приведены характеристики BDN 2.3.0.xxx.
Версия хоста xxx.ovf ( xxx = последняя
номер сборки и версии).
| Операционная система и Минимальные технические характеристики оборудования для виртуальной машины | |
| Операционная система на виртуальной машине | CentOS Linux 7.3 (1611), 64-разрядная версия |
| Минимальные требования к установке по умолчанию |
|
| Ethernet-адаптер 0 (DHCP) /etc/sysconfig/сетевые скрипты/ifcfg-eth0 | ТИП=Ethernet ЗАГРУЗКА_ПРОТО=DHCP DEFROUTE=да IPV4_FAILURE_FATAL=нет IPV6INIT=да IPV6_AUTOCONF=да IPV6_DEFROUTE=да IPV6_FAILURE_FATAL=нет IPV6_ADDR_GEN_MODE=стабильная конфиденциальность ИМЯ=eth0 УСТРОЙСТВО=eth0 НА ЗАГРУЗКЕ=да PEERDNS=да РАСШИРЕННЫЕ МАРШРУТЫ=да IPV6_PEERDNS=да IPV6_PEERROUTES=да |
| Процессы и полезные команды | ||
| Процесс | Каталог | Описание |
| монитор | /etc/init. d/monit d/monit | monit — утилита для управления сервис запуск службы мониторинга перезапуск сервисного монитора Должен быть root или суперпользователь для выполнения |
| веб-сайт | /etc/init.d/webuid | Полезные команды ./веб-стоп ./webuid начало . Должен быть root или суперпользователь для выполнения |
 /webuid перезапустить
/webuid перезапуститьУстановленные пакеты
Установленные пакеты для CentOS
7.3 (PDF)
MICHELIN X® MULTI™ Z/D (17,5
МИШЛЕН
X ® MULTI™ Z/D (17,5–19,5)
- Универсальность
- Всесезонная мобильность
MICHELIN X MULTI Z/D (17,5–19,5)
- Универсальность
- Всесезонная мобильность
Безопасность, мобильность и устойчивость на дороге для вашего легкого грузовика
- Потенциал пробега и надежность
- Надежное обращение
- Мобильность в любое время года
Возможность восстановления (Подробнее)
восстанавливаемый
Ассортимент шин MICHELIN X® MULTI™ адаптирован для крупногабаритных грузовых автомобилей до 19 тонн (жесткие/легкие грузовики) для ваших городских перевозок и доставки посылок .
Шины доступны для жестких дисков 4×2 или 6×2, а также для небольших автобусов с дисками 17,5 или 19,5 дюймов.
Предлагается шириной от 205 до 285, в частности, 215/75 R17,5, 265/70 R19,5 и 285/70 R19,5.
Ассортимент шин MICHELIN X® MULTI™ адаптирован для крупногабаритных грузовых автомобилей до 19 тонн (жесткие/легкие грузовики) для ваших городских перевозок и доставки посылок .
Шины доступны для жестких дисков 4×2 или 6×2, а также для небольших автобусов с дисками 17,5 или 19,5 дюймов.
Предлагается шириной от 205 до 285, в частности, 215/75 R17,5, 265/70 R19,5 и 285/70 R19,5.
ПОЧЕМУ ВЫБРАТЬ ЭТУ ШИНУ?
пикто евро экономия скорректирована
ВЫПОЛНЯЙТЕ СРОКИ СНИЖАЙТЕ ВАШИ РАСХОДЫ
Вы сократите время простоя вашего автомобиля , так как вы оптимизируете свои расходы, проезжая дольше (1) с теми же шинами: их срок службы до 2 на 6 месяцев дольше (2), чем у их предшественника MICHELIN XDE 2.
Logo picto Safety small Tire
ЕЗДИТЕ СО СПОКОЙСТВИЕМ В ПОЛНОЙ БЕЗОПАСНОСТИ
Если вам нужно объехать препятствие в последнюю минуту или срочно затормозить во время дождя, линейка MICHELIN X® MULTI™ в размерах 17,5 и 19.5 прошел тщательные испытания. Доказательство можно увидеть в наших видео ниже.
Логотип всесезонная малая шина
ВЕДИТЕ СВОЙ БИЗНЕС КРУГЛЫЙ ГОД
Максимально используйте свое время и снизьте расходы, сохраняя свои шины независимо от погодных условий. Вся линейка шин MICHELIN X® MULTI™ размером 17,5 и 19,5 мм имеет маркировку 3PMSF , обеспечивающую оптимальное сцепление в условиях снега.
MICHELIN — Gamme Petit Poids Lourd — Prêt à afffronter toutes les climatiques — FR/EN
Ваша мобильность сохраняется даже в снегу
Вы работаете 365/7, и ваши клиенты ожидают получить свою доставку независимо от погодных условий. Шины MICHELIN X® MULTI™ — это настоящие всесезонные шины (маркировка 3PMSF), чтобы оставаться активными круглый год.
Шины MICHELIN X® MULTI™ — это настоящие всесезонные шины (маркировка 3PMSF), чтобы оставаться активными круглый год.
MICHELIN — Gamme Petit Poids Lourd — Претендент на вызов городским джунглям — FR/EN
Маневренность без компромиссов для вашей безопасности
Никогда не знаешь, что встретится перед твоим грузовиком, особенно в городских районах: шины MICHELIN X® MULTI™ 17,5–19,5 помогут вам подготовиться к любым ситуациям. Вы сохраните контроль для большей безопасности.
MICHELIN — Gamme Petit Poids Lourd — Prêt à freiner court en toutescies — FR/EN
Безопасность при торможении даже при ношении
Вы знаете, что в городе или других городских районах счетчик может иметь значение. Хотя новая шина безопасна, что делать, если она изношена? Узнайте, как линейка MICHELIN X® MULTI ™ позволяет вам оставаться в безопасности: испытание на торможение на мокрой дороге с шинами, на 2/3 изношенными, под бдительным надзором независимой организации TÜV.
Безрезультатно
Ваш поиск
Все размеры (20)
Многопозиционный
- 9.5R17.5 TL 129/127L ВМ МИ
- 205/75R17.5 ТЛ 124/122М ВГ МИ
- 205/75R17.5 ТЛ 124/122М ВК МИ
- 205/75R17.5 ТЛ 124/122М ВК МИ
- 215/75R17.
 5 ТЛ 126/124М ВМ МИ
5 ТЛ 126/124М ВМ МИ - 225/75R17.5 ТЛ 129/127М ВГ МИ
- 235/75R17.5 ТЛ 132/130М ВГ МИ
- 245/70R17.5 ТЛ 136/134М ВМ МИ
- 265/70R17.5 ТЛ 140/138М ВГ МИ
- 245/70R19.5 ТЛ 136/134М ВГ МИ
 5 ТЛ 140/138М ВГ МИ
5 ТЛ 140/138М ВГ МИ- 285/70R19.5 TL 146/144L VM МИ
Положение привода
- 205/75R17.5 ТЛ 124/122М ВГ МИ
- 215/75R17.5 ТЛ 126/124М ВГ МИ
- 225/75R17.5 ТЛ 129/127М ВГ МИ
- 235/75R17.5 ТЛ 132/130М ВГ МИ
- 245/70R17.
 5 ТЛ 136/134М ВГ МИ
5 ТЛ 136/134М ВГ МИ - 265/70R19.5 ТЛ 140/138М ВГ МИ
- 285/70R19.5 ТЛ 146/144Л ВГ МИ
Технические характеристики
Товар | MICHELIN X MULTI Z 17,5″-19,5″ — 9,5R17,5 |
|---|---|
Должность | Все позиции |
М+С | нет |
3PMSF | нет |
RFID | да |
Индекс нагрузки | 129 |
Индекс скорости | л |
ЦАИ | 425633 |
Эта шина также может вас заинтересовать
Правовая информация
(1) Рыночные испытания среди пользователей, 2011/2012 гг. — Результаты показали увеличение срока службы на 18 % по сравнению с шиной MICHELIN XDE 2.
— Результаты показали увеличение срока службы на 18 % по сравнению с шиной MICHELIN XDE 2.
(2) Гипотеза: если шина MICHELIN XDE 2 прослужит 12 месяцев, то шина MICHELIN X® MULTI™ D прослужит 14 месяцев, или на 18 % больше.
Michelin X® MULTI™ Z / D (17,5–19,5) Грузовая шина
МИШЛЕН
Х ® MULTI™ Z/D (17,5–19,5)
- Универсальность
- Всесезонная мобильность
MICHELIN X MULTI Z/D (17,5–19,5)
- Универсальность
- Всесезонная мобильность
Безопасность, мобильность и устойчивость на дороге для вашего легкого грузовика
- Потенциал пробега и надежность
- Надежное обращение
- Мобильность в любое время года
Возможность восстановления (Подробнее)
Восстанавливаемый (Подробнее)
Ассортимент шин MICHELIN X® MULTI™ адаптирован для крупногабаритных грузовых автомобилей до 19 тонн (жесткие/легкие грузовики) для ваших городских перевозок и доставки посылок .
Шины доступны для жестких дисков 4×2 или 6×2, а также для небольших автобусов с дисками 17,5 или 19,5 дюймов.
Предлагается шириной от 205 до 285, в частности, 215/75 R17,5, 265/70 R19,5 и 285/70 R19,5.
Ассортимент шин MICHELIN X® MULTI™ адаптирован для крупногабаритных грузовых автомобилей до 19 тонн (грузовики с жесткой рамой/легкие грузовики) для вашей городской службы доставки и доставки посылок .
Шины доступны для жестких дисков 4×2 или 6×2, а также для небольших автобусов размером 17,5 или 19.5-дюймовые диски.
Предлагается шириной от 205 до 285, в частности, 215/75 R17,5, 265/70 R19,5 и 285/70 R19,5.
ПОЧЕМУ ВЫБРАТЬ ЭТУ ШИНУ?
Logo picto saves small Tire
ВЫПОЛНЯЙТЕ СРОКИ
СНИЖАЙТЕ ВАШИ РАСХОДЫ
Вы сократите время простоя вашего автомобиля , так как вы оптимизируете свои расходы, проезжая дольше (1) с теми же шинами: их срок службы истек на 2–6 месяцев дольше (2), чем у их предшественника MICHELIN XDE 2.
ES Logo picto безопасность малая шина
ЕЗДИТЕ СО СПОКОЙСТВИЕМ
В ПОЛНОЙ БЕЗОПАСНОСТИ
Если вам нужно объехать препятствие в последнюю минуту или срочно затормозить во время дождя, линейка MICHELIN X® MULTI™ в размерах 17,5 и 19,5 прошла тщательные испытания. Доказательство можно увидеть в наших видео ниже.
Логотип всесезонная малая шина
ВЕДИТЕ СВОЙ БИЗНЕС
КРУГЛЫЙ ГОД
Максимально используйте свое время и снизьте расходы, сохраняя свои шины независимо от погодных условий. Весь ассортимент MICHELIN X® MULTI™ в размерах 17,5 и 19.5 имеет маркировку 3PMSF , обеспечивающую оптимальное сцепление в условиях снега.
Конфиденциальность файлов cookie
Чтобы посмотреть это видео, вам необходимо принять некоторые файлы cookie с платформы Youtube. Просто нажмите на кнопку ниже, чтобы открыть модуль cookie.
Принять куки ютуба
MICHELIN — Gamme Petit Poids Lourd — Prêt à afffronter toutes les climatiques — FR/EN
Ваша мобильность сохраняется даже в снегу
Вы работаете 365/7, и ваши клиенты ожидают получить свою доставку независимо от погодных условий. Шины MICHELIN X® MULTI™ — это настоящие всесезонные шины (маркировка 3PMSF), чтобы оставаться активными круглый год.
Конфиденциальность файлов cookie
Чтобы посмотреть это видео, вам необходимо принять некоторые файлы cookie с платформы Youtube. Просто нажмите на кнопку ниже, чтобы открыть модуль cookie.
Принять куки ютуба
MICHELIN — Gamme Petit Poids Lourd — Prêt à afffronter la Jungle urbaine — FR/EN
Маневренность без компромиссов для вашей безопасности
Особенно в городских районах, вы никогда не знаете, что может произойти перед вашим грузовиком: шины MICHELIN X® MULTI™ 17,5–19,5 помогут вам подготовиться к любым ситуациям. Вы сохраните контроль для большей безопасности.
Вы сохраните контроль для большей безопасности.
Конфиденциальность файлов cookie
Чтобы посмотреть это видео, вам необходимо принять некоторые файлы cookie с платформы Youtube. Просто нажмите на кнопку ниже, чтобы открыть модуль cookie.
Принять куки ютуба
MICHELIN — Gamme Petit Poids Lourd — Prêt à freiner court en toutescies — FR/EN
Безопасность при торможении даже при ношении
Вы знаете, что в городе или других городских районах счетчик может иметь значение. Хотя новая шина безопасна, что делать, если она изношена? Узнайте, как линейка MICHELIN X® MULTI ™ позволяет вам оставаться в безопасности: испытание на торможение на мокрой дороге с шинами, на 2/3 изношенными, под бдительным надзором независимой организации TÜV.
Безрезультатно
Ваш поиск
Все размеры (18)
Многопозиционный
- 205/75R17.
 5 ТЛ 124/122М ВГ МИ
5 ТЛ 124/122М ВГ МИ - 215/75R17.5 ТЛ 126/124М ВМ МИ
- 225/75R17.5 ТЛ 129/127М ВГ МИ
- 235/75R17.5 ТЛ 132/130М ВГ МИ
- 245/70R17.5 ТЛ 136/134М ВМ МИ
- 265/70R17.5 ТЛ 140/138М ВГ МИ
- 245/70R19.
 5 ТЛ 136/134М ВГ МИ
5 ТЛ 136/134М ВГ МИ - 285/70R19.5 TL 146/144L VM МИ
Положение привода
- 205/75R17.5 ТЛ 124/122М ВГ МИ
- 215/75R17.5 ТЛ 126/124М ВГ МИ
- 225/75R17.5 ТЛ 129/127М ВГ МИ
- 235/75R17.
 5 ТЛ 132/130М ВГ МИ
5 ТЛ 132/130М ВГ МИ - 245/70R17.5 ТЛ 136/134М ВГ МИ
- 265/70R17.5 ТЛ 140/138М ВГ МИ
- 265/70R19.5 ТЛ 140/138М ВГ МИ
- 285/70R19.5 ТЛ 146/144Л ВГ МИ
Маркировка
Этикетка
- КЛАСС ТОПЛИВНОЙ ЭФФЕКТИВНОСТИ
Д
- КЛАСС ВЛАЖНОГО СЦЕПЛЕНИЯ
Б
- ВНЕШНИЙ КЛАСС ШУМА ПРИ КАЧЕНИИ
70 дБ
Технические характеристики
Товар | MICHELIN X MULTI Z 17,5″-19,5″ — 205/75R17,5 |
|---|---|
Должность | Z — Многопозиционный |
М+С | Да |
3PMSF | Да |
RFID | Да |
Общий диаметр | 755 мм |
Общая ширина | 210 мм |
Рекомендуемые диски | 6. |
Одобренные диски | 6,00×17,5 |
Минимальный двойной интервал | 238 мм |
Максимальная скорость (км/ч) | 130 |
Максимальная нагрузка на одну шину | 3200 кг |
Максимальная нагрузка на шину двойная | 6000 кг |
Индекс нагрузки | 124 |
Индекс скорости | М |
ЦАИ | 812426 |
 00
00Информация о нарезке
| Теоретическая глубина нарезки | 2 |
|---|---|
| Ширина нарезки | 7 — 8 |
| Лезвие | R3 |
| Шаблон повторной канавки |
Эта шина также может вас заинтересовать
Правовая информация
(1) Рыночные испытания среди пользователей, 2011/2012 гг. — Результаты показали увеличение срока службы на 18 % по сравнению с шиной MICHELIN XDE 2.
— Результаты показали увеличение срока службы на 18 % по сравнению с шиной MICHELIN XDE 2.
(2) Гипотеза: если шина MICHELIN XDE 2 прослужит 12 месяцев, то шина MICHELIN X® MULTI™ D прослужит 14 месяцев, или на 18 % больше.
63-узловой кластер EKS, работающий на одном экземпляре с Firecracker
Этот пост является частью серии постов, посвященных автоматизации Firecracker . В настоящее время он состоит из
следующие сообщения:
- Часть I:
Автоматизация запуска виртуальных машин на основе ванильных облачных образов на Firecracker - Часть II (текущая)
.
Разрабатывая исходный код, созданный для автоматизации создания виртуальных машин Firecracker, этот пост покажет, как мы можем
создать кластер, совместимый с EKS (как в Amazon EKS), с несколькими узлами, где каждый
узел будет виртуальной машиной, работающей на одном хосте, благодаря Firecracker .
Весь исходный код доступен в
этот репозиторий GitLab.
Создание кластера EKS из виртуальных машин Firecracker
EKS? Разве это не управляемый AWS сервис Kubernetes? Это, конечно, так, но это также недавно объявленный открытый исходный код и
предоставлен Amazon Web Services. Последний
более точно называется EKS Distro (EKS-D), а его исходный код доступен на
этот репозиторий Github.
В частности, будет использоваться совместимый с EKS-D дистрибутив Ubuntu на основе оснастки, поскольку он
довольно прост в установке и эксплуатации на виртуальных машинах Ubuntu. Интересно, что это распределение основано на
microk8s, и помечен как « EKS-совместимый Kubernetes ». « Совместимость » в этом контексте
похоже, что это своего рода microk8s, «одетый как» EKS, поскольку он включает в себя бинарный файл eks , который работает, как и ожидалось.
в другом месте. Но поскольку он основан на microk8s, то, наверное, подходит только для тех случаев, когда есть microk8s.
С помощью кода, разработанного в рамках предыдущего поста, можно создать настраиваемое количество виртуальных машин Firecracker.
автоматически, с SSH без пароля, настроенным с пользователем fc , который также может без пароля sudo . Учитывая это и
что нам нужно установить и настроить экземпляры для установки EKS-D Ubuntu, Ansible был
идеальный кандидат для этой автоматизации.
Весь код Ansible можно найти в
доступный /
папка. Я не являюсь экспертом по Ansible, поэтому код подлежит множеству улучшений (не стесняйтесь присылать MR!). Код должен быть
совершенно не требует пояснений — за исключением части инвентаря, которая потребовала некоторых дополнительных сценариев оболочки, которые можно найти
в
05-install_eks_via_ansible.sh
файл.
Есть две проблемы, которые нам нужно решить с помощью сценария оболочки:
Создать динамическую инвентаризацию. По сути, количество виртуальных машин основано на переменной
NUMBER_VMS, определенной в
переменныхфайла. Первый узел будет считаться ведущим EKS, а все остальные узлы рабочими.После установки оснастки
екскаждый узел будет отдельным «мастером». Для формирования единого кластера нам нужно запустить 9Команда 1152 eks add-node в мастере для каждого узла и эквивалентная команда
Для формирования единого кластера нам нужно запустить 9Команда 1152 eks add-node в мастере для каждого узла и эквивалентная команда eks joinв узлах. Обе команды используют токен,
который может быть сгенерирован автоматически (не удобно для этого варианта использования) или предоставлен. Сценарий оболочки генерирует эти токены
и предоставить их как переменные: токен для каждого узла и список всех токенов для главного узла.
Вы можете запустить этот код в своей среде. Обзор
README.md
файл и убедитесь, что firecracker установлен и правильно настроен, как описано в
первый пост. 4 ГБ и 2
ядер кажется разумным минимумом ресурсов, необходимых для каждой виртуальной машины для запуска успешного кластера, совместимого с EKS-D. Регулировать
переменных файла в вашу среду.
Создание кластера EKS с 63 узлами на экземпляре r5d.metal
Было бы здорово создать большой кластер EKS, работающий на множестве виртуальных машин… и все это на одном «большом» хосте? Это
эксперимент я провожу. Я выбрал экземпляр
Я выбрал экземпляр r5d.metal (96 ядер, 768 ГБ ОЗУ,
Локальный твердотельный накопитель NVMe емкостью 3,6 ТБ) как лучшее сочетание большого количества ядер, оперативной памяти и локального хранилища (поскольку мы будем создавать
«тома» для виртуальных машин, и это должно быть максимально быстро). Затем запустил 100 виртуальных машин Firecracker и создал EKS.
кластер…
Я установил
количество вилок Ansible
до 32, чтобы иметь больше параллелизма. Однако похоже даже при низком параллелизме есть ошибки с экс джоин
операция вызвана ограничениями на максимальное количество запросов к kubeapi-серверу, поэтому
эта часть кода Ansible сериализуется.
Виртуальные машины с 2 ядрами и 4 ГБ ОЗУ. Код сработал. Скрипты, ансибл, все заработало. Чуть позже, через 4 часа,
Кластер EKS из 100 узлов, созданный в одном экземпляре, работал:
Однако нагрузка превышала 200 , и хотя использование памяти было приемлемым (2/3 оперативной памяти системы), кластер был
непригодный для использования. Но что более важно, я обнаружил интересный факт:
Но что более важно, я обнаружил интересный факт: узла kubectl get вернули бы только 63 узла, несмотря на
99 операций соединения узлов были возвращены как успешные. Я особо не копал, но тут видимо есть ограничение
(внутреннее ограничение microk8s? В любом случае не уверен, что microk8s был тщательно протестирован с таким большим количеством кластеров
экземпляры…).
Поэтому я решил повторить операцию, но с «всего» 63 ВМ (ведь kubectl get узлов больше не вернут…) и
увеличьте характеристики ВМ до 4-ядерных (виртуальная машина главного узла также была загружена более чем на 100%) и 16 ГБ ОЗУ (16 ГБ * 63 — это
больше, чем доступная оперативная память системы, но Firecracker допускает чрезмерную нагрузку как на память, так и на ЦП, если не все
процессы используют всю выделенную оперативную память). Это сработало лучше, кластер был успешно создан и kubectl получили узлы .
сообщил на этот раз все узлы. Все примерно за 3 часа, сейчас при приемлемой загрузке процессора:
ubuntu@ip-172-31-93-220:~$ kubectl получить узлы ИМЯ СТАТУС РОЛИ ВОЗРАСТ ВЕРСИЯ id13090 Готов <нет> 116м v1.
18.9-екс-1-18-1 id08
735 Готов <нет> 93м v1.18.9-екс-1-18-1 id1865400204 Готов <нет> 85м v1.18.9-екс-1-18-1 id3176525421 Готов <нет> 79м v1.18.9-екс-1-18-1 id0289819564 Готов <нет> 97м v1.18.9-екс-1-18-1 id2364814864 Готов <нет> 101м v1.18.9-экс-1-18-1 id1576708969 Готов <нет> 62м v1.18.9-екс-1-18-1 id083
1 Готов <нет> 94м v1.18.9-екс-1-18-1 id13544 Готов <нет> 83м v1.18.9-екс-1-18-1 id25090 Готов <нет> 95м v1.18.9-eks-1-18-1 id23855 Готов <нет> 122м v1.18.9-екс-1-18-1 id2162009048 Готов <нет> 99м v1.18.9-екс-1-18-1 id003241 Готов <нет> 72м v1.18.9-екс-1-18-1 id13
381 Готов <нет> 56м v1.18.9-экс-1-18-1 id3180021860 Готов <нет> 132м v1.18.9-екс-1-18-1 id2766207659 Готов <нет> 130м v1.18.9-eks-1-18-1 id2417208994 Готов <нет> 67м v1.18.9-екс-1-18-1 id0037315342 Готов <нет> 126м v1.18.9-екс-1-18-1 id2870
2 Готов <нет> 124м v1.18.9-екс-1-18-1 id0303528979 Готов <нет> 96м v1.18.9-екс-1-18-1 id2443620467 Готов <нет> 100м v1.18.9-eks-1-18-1 id2671116621 Готов <нет> 89м v1.18.9-экс-1-18-1 id1153
1 Готов <нет> 127м v1.18.9-екс-1-18-1 id1618117867 Готов <нет> 114м v1.18.9-екс-1-18-1 id1345427105 Готов <нет> 128м v1.18.9-екс-1-18-1 id1578112374 Готов <нет> 133м v1.18.9-екс-1-18-1 id2260431270 Готов <нет> 134м v1.18.9-екс-1-18-1 id11052 Готов <нет> 131м v1.18.9-екс-1-18-1 id00056 Готов <нет> 86м v1.18.9-екс-1-18-1 id0772428726 Готов <нет> 112м v1.18.9-экс-1-18-1 id2345631371 Готов <нет> 115м v1.18.9-екс-1-18-1 id0866401320 Готов <нет> 90м v1.18.9-eks-1-18-1 id22569 Готов <нет> 121м v1.18.9-екс-1-18-1 id31 619 Готов <нет> 105м v1.18.9-екс-1-18-1
id3212514411 Готов <нет> 64м v1.18.9-екс-1-18-1
id2530228284 Готов <нет> 58м v1.18.9-екс-1-18-1
id1582731567 Готов <нет> 125м v1.18.9-екс-1-18-1
id0234531685 Готово <нет> 104 м v1.18.9-экс-1-18-1
id1170407709 Готов <нет> 129м v1.18.9-екс-1-18-1
id2377401525 Готов <нет> 129м v1.18.9-екс-1-18-1
id27829 Готов <нет> 109м v1.18.9-екс-1-18-1
id2316206444 Готов <нет> 88м v1.18.9-екс-1-18-1
id0886017938 Готов <нет> 120м v1.18.9-eks-1-18-1
id2886224137 Готов <нет> 135м v1.18.9-екс-1-18-1
id2137806005 Готов <нет> 74м v1.18.9-екс-1-18-1
id3252717927 Готов <нет> 136м v1.18.9-экс-1-18-1
id1421103858 Готов <нет> 111м v1.18.9-екс-1-18-1
id2048704797 Готов <нет> 102м v1.18.9-екс-1-18-1
id18011 Готов <нет> 106м v1.18.9-екс-1-18-1
id07146 Готов <нет> 61м v1.18.9-екс-1-18-1
id1134505657 Готов <нет> 82м v1.18.9-екс-1-18-1
id0023523299 Готов <нет> 118м v1.18.9-екс-1-18-1
id2477116066 Готов <нет> 81м v1.18.9-екс-1-18-1
id04618 Готов <нет> 77м v1.18.9-экс-1-18-1
id1020429150 Готов <нет> 113м v1.18.9-екс-1-18-1
id1471722684 Готов <нет> 91м v1.18.9-екс-1-18-1
id1417322458 Готов <нет> 75м v1.18.9-eks-1-18-1
id0107720352 Готов <нет> 69м v1.18.9-екс-1-18-1
id29576 Готов <нет> 108м v1.18.9-екс-1-18-1
id0573606644 Готов <нет> 3ч54м v1.18.9-экс-1-18-1
id1377114631 Готов <нет> 117м v1.18.9-екс-1-18-1
id0468822693 Готов <нет> 119м v1.18.9-экс-1-18-1
id0660532190 Готов <нет> 71м v1.18.9-екс-1-18-1Несмотря на все это, кластер нельзя было использовать.
Большинство операций выполнялись долго, а некоторые приводили к ошибкам.
Вероятно, микрок8, на котором основан этот ЭКС-Д, не предназначен для этих целей 😉Заключительные слова
Эксперимент с 63 и 100 узлами был скорее забавным упражнением и проверкой скриптов и кода Ansible. Однако,
код представлен
весьма полезен, особенно для тестирования сценариев. Я могу создать на своем ноутбуке 3-узловой кластер EKS (2 ядра, 4 ГБ ОЗУ на
узел) менее чем за 5 минут, и все это с помощью однострочной команды. И уничтожь все это за секунды еще одной строчкой . Этот
позволяет быстро тестировать EKS-совместимые кластеры Kubernetes. Все благодаря Firecracker и EKS-D, оба с открытым исходным кодом
компоненты, выпущенные AWS. Спасибо!Задачи узла | Конфигурация после установки
- Добавление вычислительных машин RHEL в кластер OpenShift Container Platform
- О добавлении вычислительных узлов RHEL в кластер
- Системные требования для вычислительных узлов RHEL
- Подготовка машины к запуску playbook
- Подготовка вычислительного узла RHEL
- Добавление вычислительной машины RHEL в ваш кластер
- Обязательные параметры для файла хостов Ansible
- Необязательно: удаление вычислительных машин RHCOS из кластера
- Добавление вычислительных машин RHCOS в кластер OpenShift Container Platform
- Предпосылки
- Создание дополнительных машин RHCOS с использованием образа ISO
- Создание дополнительных машин RHCOS с помощью загрузки PXE или iPXE
- Утверждение запросов на подпись сертификатов для ваших машин
- Добавление нового рабочего узла RHCOS с пользовательским разделом
/varв AWS- Развертывание проверки работоспособности компьютера
- О проверках работоспособности машины
- Образец ресурса MachineHealthCheck
- Создание ресурса MachineHealthCheck
- Масштабирование машинного набора вручную
- Понимание разницы между наборами машин и пулом конфигурации машин
- Рекомендуемые методы размещения узла
- Создание CRD KubeletConfig для редактирования параметров kubelet
- Изменение количества недоступных рабочих узлов
- Размер узла плоскости управления
- Настройка диспетчера ЦП
- Огромные страницы
- Что делают огромные страницы
- Как огромные страницы потребляются приложениями
- Настройка огромных страниц
- Общие сведения о подключаемых модулях устройств
- Методы развертывания подключаемого модуля устройства
- Общие сведения о диспетчере устройств
- Включение диспетчера устройств
- Пороки и допуски
- Понимание недостатков и допусков
- Добавление недостатков и допусков
- Добавление примесей и допусков с помощью машинного набора
- Привязка пользователя к узлу с использованием taints и допусков
- Управление узлами с помощью специального оборудования с использованием исправлений и допусков
- Удаление пороков и допусков
- Менеджер топологии
- Политики менеджера топологии
- Настройка менеджера топологии
- Взаимодействие модулей с политиками Topology Manager
- Запросы ресурсов и чрезмерное выделение ресурсов
- избыточная фиксация на уровне кластера с использованием оператора переопределения ресурсов кластера
- Установка оператора переопределения ресурсов кластера с помощью веб-консоли
- Установка оператора переопределения ресурсов кластера с помощью интерфейса командной строки
- Настройка избыточной фиксации на уровне кластера
- избыточная фиксация на уровне узла
- Общие сведения о вычислительных ресурсах и контейнерах
- Понимание чрезмерной ответственности и качества обслуживания классов
- Общие сведения о памяти подкачки и QOS
- Понимание чрезмерной фиксации узлов
- Отключение или применение ограничений ЦП с помощью квот ЦП CFS
- Резервирование ресурсов для системных процессов
- Отключение чрезмерной фиксации для узла
- Ограничения на уровне проекта
- Отключение чрезмерной фиксации для проекта
- Освобождение ресурсов узла с помощью сборки мусора
- Понимание того, как завершенные контейнеры удаляются с помощью сборки мусора
- Понимание того, как изображения удаляются при сборке мусора
- Настройка сборки мусора для контейнеров и образов
- Использование оператора настройки узла
- Доступ к примеру спецификации оператора настройки узла
- Спецификация пользовательской настройки
- Профили по умолчанию, установленные на кластере
- Поддерживаемые подключаемые модули демона TuneD
- Настройка максимального количества модулей на узел
После установки OpenShift Container Platform вы можете дополнительно расширить и настроить свой
кластер в соответствии с вашими требованиями с помощью определенных задач узла.Добавление вычислительных машин RHEL в кластер OpenShift Container Platform
Понимание и работа с вычислительными узлами RHEL.
О добавлении вычислительных узлов RHEL в кластер
В OpenShift Container Platform 4.10 у вас есть возможность использовать машины Red Hat Enterprise Linux (RHEL) в качестве вычислительных машин в вашем кластере, если вы используете установку инфраструктуры, предоставленную пользователем на
x86_64архитектура. Вы должны использовать компьютеры Red Hat Enterprise Linux CoreOS (RHCOS) для компьютеров плоскости управления в вашем кластере.Если вы решили использовать вычислительные машины RHEL в своем кластере, вы несете ответственность за управление и обслуживание всего жизненного цикла операционной системы. Вы должны выполнять обновления системы, применять исправления и выполнять все другие необходимые задачи.
Поскольку удаление OpenShift Container Platform с компьютера в кластере требует уничтожения операционной системы, вы должны использовать выделенное оборудование для любых компьютеров RHEL, которые вы добавляете в кластер.
Подкачка памяти отключена на всех компьютерах RHEL, которые вы добавляете в свой кластер OpenShift Container Platform. Вы не можете включить память подкачки на этих машинах.
Все вычислительные машины RHEL необходимо добавить в кластер после инициализации плоскости управления.
Системные требования для вычислительных узлов RHEL
Хосты вычислительных машин Red Hat Enterprise Linux (RHEL) в вашей среде OpenShift Container Platform должны соответствовать следующим минимальным спецификациям оборудования и системным требованиям:
У вас должна быть активная подписка на OpenShift Container Platform в вашей учетной записи Red Hat. Если нет, обратитесь к торговому представителю для получения дополнительной информации.
Производственные среды должны предоставлять вычислительные машины для поддержки ожидаемых рабочих нагрузок. Как администратор кластера, вы должны рассчитать ожидаемую рабочую нагрузку и добавить около 10% накладных расходов.
Для рабочих сред выделите достаточно ресурсов, чтобы сбой хоста узла не повлиял на вашу максимальную емкость.
Каждая система должна соответствовать следующим требованиям к оборудованию:
Физическая или виртуальная система или экземпляр, работающий в общедоступной или частной IaaS.
Базовая ОС: RHEL 8.4 или 8.5 с «минимальной» установкой.
Добавление вычислительных машин RHEL 7 в кластер OpenShift Container Platform не поддерживается.
Если у вас есть вычислительные машины RHEL 7, которые ранее поддерживались в предыдущей версии OpenShift Container Platform, вы не можете обновить их до RHEL 8. Необходимо развернуть новые хосты RHEL 8, а старые хосты RHEL 7 следует удалить. Дополнительные сведения см. в разделе «Удаление узлов».
Самый последний список основных функций, которые устарели или были удалены в OpenShift Container Platform, см. в разделе Устаревшие и удаленные функции примечаний к выпуску OpenShift Container Platform.
Если вы развернули OpenShift Container Platform в режиме FIPS, вы должны включить FIPS на компьютере RHEL перед его загрузкой. См. Установка системы RHEL 8 с включенным режимом FIPS в документации RHEL 8.
Использование криптографических библиотек с проверкой FIPS/модулей в процессе поддерживается только в развертываниях OpenShift Container Platform на архитектуре
x86_64.
NetworkManager 1.0 или выше.
1 виртуальный ЦП.
Минимум 8 ГБ ОЗУ.
Минимум 15 ГБ свободного места на жестком диске для файловой системы, содержащей
/вар/.Минимум 1 ГБ свободного места на жестком диске для файловой системы, содержащей
/usr/local/bin/.Минимум 1 ГБ свободного места на жестком диске для файловой системы, содержащей временный каталог.
Временный системный каталог определяется в соответствии с правилами, определенными в модуле tempfile стандартной библиотеки Python.
Каждая система должна соответствовать любым дополнительным требованиям вашего системного провайдера. Например, если вы установили свой кластер на VMware vSphere, ваши диски должны быть настроены в соответствии с его рекомендациями по хранению и
disk.enableUUID=trueАтрибут должен быть установлен.Каждая система должна иметь возможность доступа к конечным точкам API кластера, используя DNS-разрешаемые имена хостов. Любой имеющийся контроль доступа к сетевой безопасности должен разрешать системе доступ к конечным точкам службы API кластера.
Дополнительные ресурсы
Удаление узлов
Управление запросами на подпись сертификата
Поскольку ваш кластер имеет ограниченный доступ к автоматическому управлению машинами при использовании предоставляемой вами инфраструктуры, вы должны предоставить механизм утверждения запросов на подпись сертификата кластера (CSR) после установки.

kube-controller-managerутверждает только CSR клиента kubelet. Утверждающий компьютерне может гарантировать действительность обслуживающего сертификата, запрошенного с использованием учетных данных kubelet, поскольку он не может подтвердить, что правильный компьютер выдал запрос. Вы должны определить и внедрить метод проверки действительности kubelet, обслуживающего запросы сертификатов, и их утверждения.Подготовка машины к запуску playbook
Прежде чем добавлять вычислительные машины, использующие Red Hat Enterprise Linux (RHEL) в качестве операционной системы, в кластер OpenShift Container Platform 4.10, необходимо подготовить машину RHEL 7 или 8 для запуска Ansible playbook, который добавляет новый узел в кластер. Эта машина не является частью кластера, но должна иметь к нему доступ.
Предпосылки
Процедура
Убедитесь, что файл
kubeconfigдля кластера и программа установки, которую вы использовали для установки кластера, находятся на компьютере RHEL.Один из способов добиться этого — использовать тот же компьютер, который вы использовали для установки кластера.
Настройте компьютер для доступа ко всем хостам RHEL, которые вы планируете использовать в качестве вычислительных компьютеров. Вы можете использовать любой метод, разрешенный вашей компанией, включая бастион с SSH-прокси или VPN.
Настройте пользователя на компьютере, на котором вы запускаете playbook, который имеет доступ SSH ко всем хостам RHEL.
Если вы используете аутентификацию на основе ключа SSH, вы должны управлять ключом с помощью агента SSH.
Если вы еще этого не сделали, зарегистрируйте машину в RHSM и прикрепите к ней пул с подпиской
OpenShift:
Зарегистрируйте машину в RHSM:
# регистрация менеджера подписки --username=<имя_пользователя> --password=<пароль>Получить последние данные подписки из RHSM:
# обновление менеджера подпискиСписок доступных подписок:
# список менеджеров подписок --доступен --matches '*OpenShift*'В выходных данных предыдущей команды найдите идентификатор пула для подписки OpenShift Container Platform и прикрепите его:
# менеджер подписки прикрепить --pool=Включить репозитории, необходимые для OpenShift Container Platform 4.
10:
В системе RHEL 8 выполните следующую команду:
# репозиторий менеджера подписки \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="ansible-2.9-for-rhel-8-x86_64-rpm" \ --enable="rhocp-4.10-for-rhel-8-x86_64-rpm"В системе RHEL 7 выполните следующую команду:
# репозиторий менеджера подписки \ --enable="rhel-7-server-rpms" \ --enable="rhel-7-server-extras-rpms" \ --enable="rhel-7-server-ansible-2.9-rpms" \ --enable="rhel-7-server-ose-4.10-rpms"
Начиная с OpenShift Container Platform 4.10.23, запуск Ansible playbooks на RHEL 7 устарел и предлагается только с целью обновления существующих установок. Начиная с OpenShift Container Platform 4.11, книги воспроизведения Ansible предоставляются только для RHEL 8.
Установите необходимые пакеты, включая
openshift-ansible:# yum install openshift-ansible openshift-clients jqПакет
openshift-ansibleсодержит утилиты программы установки и извлекает другие пакеты, необходимые для добавления вычислительного узла RHEL в ваш кластер, такие как Ansible, плейбуки и соответствующие файлы конфигурации.
openshift-клиентовобеспечиваютocCLI, а пакетjqулучшает отображение вывода JSON в командной строке.Подготовка вычислительного узла RHEL
Перед добавлением компьютера Red Hat Enterprise Linux (RHEL) в кластер OpenShift Container Platform необходимо зарегистрировать каждый хост в Red Hat Subscription Manager (RHSM), подключить активную подписку OpenShift Container Platform, и включите необходимые репозитории.
На каждом хосте зарегистрируйтесь в RHSM:
# регистрация менеджера подписки --username=<имя_пользователя> --password=<пароль>Получить последние данные подписки из RHSM:
# обновление менеджера подпискиСписок доступных подписок:
# список менеджеров подписок --доступен --matches '*OpenShift*'В выходных данных предыдущей команды найдите идентификатор пула для подписки OpenShift Container Platform и прикрепите его:
# менеджер подписки прикрепить --pool=Отключить все репозитории yum:
Отключить все включенные репозитории RHSM:
# репозиторий менеджера подписки --disable="*"Перечислите оставшиеся репозитории yum и запишите их имена под
repo id, если есть:# ням реполистИспользуйте
yum-config-manager, чтобы отключить остальные репозитории yum:# yum-config-manager --disableВ качестве альтернативы можно отключить все репозитории:
# yum-config-manager --disable \*Обратите внимание, что это может занять несколько минут, если у вас большое количество доступных репозиториев
Включить только репозитории, необходимые для OpenShift Container Platform 4.
10:
# репозиторий менеджера подписки \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.10-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpm"Остановить и отключить firewalld на хосте:
# systemctl отключить --now firewalld.service
Вы не должны включать firewalld позже. Если вы это сделаете, вы не сможете получить доступ к журналам OpenShift Container Platform на рабочем месте.
Добавление вычислительной машины RHEL в кластер
Вы можете добавить вычислительные машины, использующие Red Hat Enterprise Linux в качестве операционной системы, в кластер OpenShift Container Platform 4.10.
Предварительные условия
Процедура
Выполните следующие действия на машине, подготовленной для запуска playbook:
Создайте файл инвентаризации Ansible с именем
/<путь>/inventory/hosts, который определяет хосты вашей вычислительной машины и необходимые переменные:[все:вары] ansible_user=root (1) #ansible_become=Истина (2) openshift_kubeconfig_path="~/.kube/config" (3) г. [new_workers] (4) mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com
1 Укажите имя пользователя, который запускает задачи Ansible на удаленных вычислительных машинах. 2 Если вы не укажете rootдляansible_user, вы должны установить дляansible_becomeзначениеTrueи назначить пользователю разрешения sudo.3 Укажите путь и имя файла kubeconfigдля вашего кластера.4 Перечислите все машины RHEL для добавления в ваш кластер. Вы должны указать полное доменное имя для каждого хоста. Это имя является именем хоста, которое кластер использует для доступа к машине, поэтому задайте правильное общедоступное или частное имя для доступа к машине. Перейдите в каталог Ansible playbook:
$ cd /usr/share/ansible/openshift-ansibleЗапустить плейбук:
$ ansible-playbook -i //inventory/hosts playbooks/scaleup.yml (1)
1 Для <путь>укажите путь к созданному вами файлу инвентаризации Ansible.Обязательные параметры для файла узлов Ansible
Перед добавлением вычислительных машин Red Hat Enterprise Linux (RHEL) в кластер необходимо определить следующие параметры в файле узлов Ansible.
Параметр Описание Значения
ansible_userПользователь SSH, который разрешает аутентификацию на основе SSH без ввода пароля.
Если вы используете аутентификацию на основе ключа SSH, вы должны управлять ключом с помощью агента SSH.
Имя пользователя в системе. Значение по умолчанию —
root.
ansible_becomeЕсли значения
ansible_userне root, вы должны установитьansible_becomeнаTrue, а пользователь, указанный вами какansible_user, должен быть настроен для доступа sudo без пароля.
Правда. Если значение не равноTrue, не указывайте и не определяйте этот параметр.
openshift_kubeconfig_pathУказывает путь и имя файла к локальному каталогу, содержащему файл
kubeconfigдля вашего кластера.Путь и имя файла конфигурации.
Необязательно: удаление вычислительных машин RHCOS из кластера
После добавления вычислительных машин Red Hat Enterprise Linux (RHEL) в кластер можно при желании удалить вычислительные машины Red Hat Enterprise Linux CoreOS (RHCOS), чтобы освободить Ресурсы.
Предпосылки
Процедура
Просмотрите список машин и запишите имена узлов вычислительных машин RHCOS:
$ oc получить узлы -o широкийДля каждой вычислительной машины RHCOS удалите узел:
Пометьте узел как незапланированный, выполнив команду
oc adm Cordon:$ oc adm Cordon(1)
1 Укажите имя узла одной из вычислительных машин RHCOS. Слить все поды с ноды:
$ oc adm сток--force --delete-emptydir-data --ignore-daemonsets (1)
1 Укажите имя узла вычислительной машины RHCOS, которую вы изолировали. Удалить узел:
$ oc удалить узлы(1)
1 Укажите имя узла вычислительной машины RHCOS, которую вы слили. Просмотрите список вычислительных машин, чтобы убедиться, что остались только узлы RHEL:
$ oc получить узлы -o широкийУдалите машины RHCOS из балансировщика нагрузки для вычислительных машин вашего кластера. Вы можете удалить виртуальные машины или повторно создать образ физического оборудования для вычислительных машин RHCOS.
Добавление вычислительных машин RHCOS в кластер OpenShift Container Platform
Вы можете добавить дополнительные вычислительные машины Red Hat Enterprise Linux CoreOS (RHCOS) в свой кластер OpenShift Container Platform на «голом железе».
Прежде чем добавлять дополнительные вычислительные машины в кластер, установленный в инфраструктуре «голого железа», необходимо создать для него машины RHCOS. Вы можете использовать ISO-образ или сетевую загрузку PXE для создания машин.
Предпосылки
Вы установили кластер на голое железо.
У вас есть установочный носитель и образы Red Hat Enterprise Linux CoreOS (RHCOS), которые вы использовали для создания кластера. Если у вас нет этих файлов, вы должны получить их, следуя инструкциям в процедуре установки.
Создание дополнительных машин RHCOS с помощью образа ISO
Вы можете создать больше вычислительных машин Red Hat Enterprise Linux CoreOS (RHCOS) для своего кластера на «голом железе», используя образ ISO для создания машин.
Предпосылки
Процедура
Используйте файл ISO для установки RHCOS на большее количество вычислительных машин. Используйте тот же метод, который вы использовали при создании машин до установки кластера:
.
После загрузки экземпляра нажмите клавишу
TABилиE, чтобы отредактировать командную строку ядра.Добавьте параметры в командную строку ядра:
coreos.inst.install_dev=sda (1) г. coreos.inst.ignition_url=http://example.com/worker.ign (2)
1 Укажите блочное устройство системы для установки. 2 Укажите URL-адрес файла конфигурации Ignition вычислений. Поддерживаются только протоколы HTTP и HTTPS. Нажмите
Введитедля завершения установки. После установки RHCOS система перезагружается. После перезагрузки система применяет указанный вами файл конфигурации Ignition.Продолжайте создавать дополнительные вычислительные машины для своего кластера.
Создание дополнительных машин RHCOS с помощью загрузки PXE или iPXE
Вы можете создать больше вычислительных машин Red Hat Enterprise Linux CoreOS (RHCOS) для своего кластера на «голом железе», используя загрузку PXE или iPXE.
Предпосылки
Получите URL-адрес файла конфигурации Ignition для вычислительных машин вашего кластера. Вы загрузили этот файл на свой HTTP-сервер во время установки.
Получите URL-адреса ISO-образа RHCOS, сжатого металлического BIOS,
ядраифайлов initramfs, которые вы загрузили на свой HTTP-сервер во время установки кластера.У вас есть доступ к инфраструктуре загрузки PXE, которую вы использовали для создания машин для своего кластера OpenShift Container Platform во время установки. Машины должны загружаться со своих локальных дисков после установки на них RHCOS.
Если вы используете UEFI, у вас есть доступ к файлу
grub.conf, который вы изменили во время установки OpenShift Container Platform.Процедура
Подтвердите правильность установки PXE или iPXE для образов RHCOS.
Эта конфигурация не обеспечивает доступ к последовательной консоли на компьютерах с графической консолью.
Чтобы настроить другую консоль, добавьте один или несколько аргументов
console=вДОБАВИТЬстроку. Например, добавьтеconsole=tty0 console=ttyS0, чтобы установить первый последовательный порт ПК в качестве основной консоли, а графическую консоль — в качестве дополнительной консоли. Для получения дополнительной информации см. Как настроить последовательный терминал и/или консоль в Red Hat Enterprise Linux?.Эта конфигурация не обеспечивает доступ к последовательной консоли на компьютерах с графической консолью. Чтобы настроить другую консоль, добавьте один или несколько аргументов
console=в ядро 9.1153 строка. Например, добавьтеconsole=tty0 console=ttyS0, чтобы установить первый последовательный порт ПК в качестве основной консоли, а графическую консоль — в качестве дополнительной консоли. Для получения дополнительной информации см. Как настроить последовательный терминал и/или консоль в Red Hat Enterprise Linux?.
Используйте инфраструктуру PXE или iPXE для создания необходимых вычислительных машин для вашего кластера.
Утверждение запросов на подпись сертификата для ваших машин
При добавлении машин в кластер для каждой добавленной машины создаются два ожидающих запроса на подпись сертификата (CSR). Вы должны подтвердить, что эти CSR утверждены, или, при необходимости, утвердить их самостоятельно. Запросы клиента должны быть одобрены первыми, а затем запросы сервера.
Предпосылки
Процедура
Подтвердите, что кластер распознает машины:
$ oc получить узлыПример вывода
ИМЯ СТАТУС РОЛИ ВОЗРАСТ ВЕРСИЯ мастер-0 Готовый мастер 63м v1.23.0 мастер-1 Готовый мастер 63м v1.23.0 мастер-2 Готовый мастер 64м v1.23.0В выходных данных перечислены все созданные вами машины.
Предыдущие выходные данные могут не включать вычислительные узлы, также известные как рабочие узлы, до утверждения некоторых CSR.
Просмотрите ожидающие запросы CSR и убедитесь, что вы видите запросы клиентов с
PendingилиApprovedстатус для каждой машины, которую вы добавили в кластер:$ oc получить csrПример вывода
ИМЯ ВОЗРАСТ ЗАПРОСА УСЛОВИЕ csr-8b2br 15m система:serviceaccount:openshift-machine-config-operator:node-bootstrapper Ожидание csr-8vnps 15m система:serviceaccount:openshift-machine-config-operator:node-bootstrapper Ожидание ...В этом примере к кластеру присоединяются две машины. Вы можете увидеть больше утвержденных CSR в списке.
Если CSR не были утверждены, после того как все ожидающие CSR для добавленных вами машин перейдут в состояние
Pending, утвердите CSR для ваших машин кластера:
Поскольку CSR меняются автоматически, утвердите свои CSR в течение часа после добавления машин в кластер.
Если вы не одобрите их в течение часа, сертификаты будут ротироваться, и для каждого узла будет присутствовать более двух сертификатов. Вы должны утвердить все эти сертификаты. После утверждения клиентского CSR Kubelet создает вторичный CSR для обслуживающего сертификата, который требует ручного утверждения. Затем последующие запросы на продление обслуживания сертификатов автоматически утверждаются
machine-approver, если Kubelet запрашивает новый сертификат с идентичными параметрами.
Для кластеров, работающих на платформах, не поддерживающих машинный API, таких как «голое железо» и другая инфраструктура, предоставляемая пользователями, необходимо реализовать метод автоматического утверждения запросов на сертификаты (CSR) для обслуживания kubelet. Если запрос не одобрен, то
oc exec,oc rshиoc logsкоманды не могут быть выполнены, так как при подключении сервера API к kubelet требуется обслуживающий сертификат.Любая операция, которая связывается с конечной точкой Kubelet, требует утверждения этого сертификата. Метод должен отслеживать новые CSR, подтверждать, что CSR был отправлен учетной записью службы
node-bootstrapperв группахsystem:nodeилиsystem:admin, и подтверждать личность узла.
Чтобы утвердить их по отдельности, выполните следующую команду для каждого действительного CSR:
$ oc сертификат администратора утверждает(1)
1 — имя CSR из списка текущих CSR.Чтобы утвердить все ожидающие CSR, выполните следующую команду:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{ конец}}' | xargs --no-run-if-empty сертификат oc adm утвердить
: Некоторые операторы могут быть недоступны, пока не будут утверждены некоторые CSR.
Теперь, когда ваши клиентские запросы утверждены, вы должны просмотреть серверные запросы для каждой машины, которую вы добавили в кластер:
$ oc получить csrПример вывода
ИМЯ ВОЗРАСТ ЗАПРОСА УСЛОВИЕ csr-bfd72 5m26s система: узел: ip-10-0-50-126.us-east-2.compute.internal В ожидании csr-c57lv 5m26s система: узел: ip-10-0-95-157.us-east-2.compute.internal В ожидании ...Если оставшиеся CSR не утверждены и находятся в состоянии
Pending, утвердите CSR для машин вашего кластера:
Чтобы утвердить их по отдельности, выполните следующую команду для каждого действительного CSR:
$ oc сертификат администратора утверждает(1)
1 — это имя CSR из списка текущих CSR.Чтобы утвердить все ожидающие CSR, выполните следующую команду:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{ конец}}' | сертификат xargs oc adm утверждаетПосле утверждения всех клиентских и серверных CSR машины получают статус
Готов. Убедитесь в этом, выполнив следующую команду:$ oc получить узлыПример вывода
ИМЯ СТАТУС РОЛИ ВОЗРАСТ ВЕРСИЯ мастер-0 Готовый мастер 73м v1.23.0 мастер-1 Готовый мастер 73м v1.23.0 мастер-2 Готовый мастер 74м v1.23.0 worker-0 Готовый рабочий 11м v1.23.0 рабочий-1 Готовый рабочий 11м v1.23.0
После утверждения CSR сервера может пройти несколько минут, прежде чем компьютеры перейдут в состояние
Готов.Дополнительная информация
Добавление нового рабочего узла RHCOS с пользовательским разделом
/varв AWSOpenShift Container Platform поддерживает разделение устройств во время установки с помощью конфигураций компьютера, которые обрабатываются во время начальной загрузки.
Однако, если вы используете разбиение на разделы
/var, имя устройства должно быть определено при установке и не может быть изменено. Вы не можете добавлять разные типы экземпляров в качестве узлов, если они имеют другую схему именования устройств. Например, если вы настроили/varс именем устройства AWS по умолчанию для экземпляровm4.large,dev/xvdb, вы не можете напрямую добавить экземпляр AWSm5.large, так как экземплярыm5.largeиспользуют/dev /nvme1n1устройство по умолчанию. Устройство может не разбиться на разделы из-за другой схемы именования.Процедура в этом разделе показывает, как добавить новый вычислительный узел Red Hat Enterprise Linux CoreOS (RHCOS) с экземпляром, который использует имя устройства, отличное от того, которое было настроено при установке. Вы создаете пользовательский секрет данных пользователя и настраиваете новый набор компьютеров. Эти шаги относятся к кластеру AWS.
Эти принципы применимы и к другим облачным развертываниям. Однако схема именования устройств отличается для других развертываний и должна определяться в каждом конкретном случае.
Процедура
В командной строке измените пространство имен
openshift-machine-api:$ oc проект openshift-machine-apiСоздать новый секрет из секрета
worker-user-data:
Экспорт раздела секрета
userDataв текстовый файл:$ oc получить секретные рабочие данные пользователя --template='{{index .data.userData | base64decode}}' | jq > userData.txtОтредактируйте текстовый файл, чтобы добавить разделы
storage,filesystemsиsystemdдля разделов, которые вы хотите использовать для нового узла. При необходимости вы можете указать любые параметры конфигурации зажигания.
Не изменять значения в разделе
зажигания.{ "зажигание": { "конфигурация": { "слияние": [ { "источник": "https:...." } ] }, "безопасность": { "TLS": { "Уполномоченные по сертификации": [ { "источник": "данные:текст/обычный;кодировка=utf-8;base64,.....==" } ] } }, "версия": "3.2.0" }, "хранилище": { "диски": [ { "устройство": "/dev/nvme1n1", (1) "разделы": [ { "метка": "вар", "размерМиБ": 50000, (2) "стартМиБ": 0 (3) } ] } ], "файловые системы": [ { "устройство": "/dev/disk/by-partlabel/var", (4) "формат": "xfs", (5) "путь": "/var" (6) } ] }, "системд": { "единицы": [ (7) { "contents": "[Unit]\nBefore=local-fs.target\n[Mount]\nWhere=/var\nWhat=/dev/disk/by-partlabel/var\nOptions=defaults,pquota\n[Install] \nWantedBy=local-fs.target\n", "включено": правда, "имя": "var.mount" } ] } }
1 Указывает абсолютный путь к блочному устройству AWS. 2 Указывает размер раздела данных в мегабайтах. 3 Указывает начало раздела в мегабайтах. При добавлении раздела данных на загрузочный диск рекомендуется минимальное значение 25000 МБ (мебибайт). Размер корневой файловой системы автоматически изменяется, чтобы заполнить все доступное пространство до указанного смещения. Если значение не указано или если указанное значение меньше рекомендуемого минимума, результирующая корневая файловая система будет слишком маленькой, и будущие переустановки RHCOS могут перезаписать начало раздела данных. 4 Задает абсолютный путь к разделу /var.5 Задает формат файловой системы. 6 Указывает точку монтирования файловой системы во время работы Ignition относительно места монтирования корневой файловой системы. Это не обязательно то же место, где он должен быть смонтирован в реальном корне, но рекомендуется сделать его таким же. 7 Определяет модуль монтирования systemd, который монтирует устройство /dev/disk/by-partlabel/varв раздел/var.Извлечь раздел
disableTemplatingиз секрета work-user-data в текстовый файл:$ oc получить секретные рабочие данные пользователя --template='{{index .data.disableTemplating | base64decode}}' | jq > отключитьTemplating.txtСоздайте новый секретный файл данных пользователя из двух текстовых файлов.
Этот секрет данных пользователя передает дополнительную информацию о разделе узла в файле userData.txt вновь созданному узлу.
$ oc создать секретный универсальный worker-user-data-x5 --from-file=userData=userData.txt --from-file=disableTemplating=disableTemplating.txtСоздайте новый набор машин для нового узла:
Создайте новый файл YAML набора компьютеров, аналогичный следующему, который настроен для AWS. Добавьте необходимые разделы и вновь созданный секрет данных пользователя:
Используйте существующий набор машин в качестве шаблона и измените необходимые параметры для нового узла.
версия API: machine.openshift.io/v1beta1 вид: Машинсет метаданные: этикетки: машина.openshift.io/кластер-апи-кластер: авто-52-92tf4 имя: рабочий-нас-восток-2-nvme1n1 (1) пространство имен: openshift-machine-api спецификация: реплики: 1 селектор: метки соответствия: машина.openshift.io/кластер-апи-кластер: авто-52-92тс4 machine.openshift.io/cluster-api-machineset: auto-52-92tf4-worker-us-east-2b шаблон: метаданные: этикетки: машина.openshift.io/кластер-апи-кластер: авто-52-92tf4 machine.openshift.io/cluster-api-machine-role: рабочий machine.openshift.io/cluster-api-machine-type: рабочий machine.openshift.io/cluster-api-machineset: auto-52-92tf4-worker-us-east-2b спецификация: метаданные: {} Спецификация поставщика: ценность: ами: идентификатор: ami-0c2dbd
- а apiVersion: awsproviderconfig.openshift.io/v1beta1 блочные устройства: - Имя устройства: /dev/nvme1n1 (2) ЭБС: зашифровано: правда операций ввода-вывода: 0 размер тома: 120 тип тома: gp2 - Имя устройства: /dev/nvme1n2 (3) ЭБС: зашифровано: правда операций ввода-вывода: 0 размер тома: 50 тип тома: gp2 секрет секрета: имя: aws-cloud-credentials индекс устройства: 0 iamInstanceProfile: идентификатор: авто-52-92tf4-рабочий профиль instanceType: m6i.
large вид: AWSMachineProviderConfig метаданные: временная метка создания: ноль размещение: зона доступности: us-east-2b регион: us-east-2 группы безопасности: - фильтры: - имя: тег:Имя ценности: - авто-52-92тф4-рабочий-сг подсеть: идентификатор: подсеть-07a90e5db1 теги: - имя: kubernetes.io/cluster/auto-52-92tf4 стоимость: принадлежит секрет данных пользователя: имя: работник-пользователь-данные-x5 (4)
1 Указывает имя для нового узла. 2 Указывает абсолютный путь к блочному устройству AWS, в данном случае зашифрованному тому EBS. 3 Дополнительно. Задает дополнительный том EBS. 4 Задает секретный файл данных пользователя. Создать набор машин:
$ oc create -f <имя-файла>.yamlДоступ к машинам может занять некоторое время.
Убедитесь, что новый раздел и узлы созданы:
Убедитесь, что набор машин создан:
$ oc получить набор машинПример вывода
ИМЯ ЖЕЛАЕМЫЙ ТЕКУЩИЙ ГОТОВ ДОСТУПНЫЙ ВОЗРАСТ ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1a 1 1 1 1 124m ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1b 2 2 2 2 124m рабочий-нас-восток-2-nvme1n1 1 1 1 1 2m35s (1)
1 Это новый комплект машин. Убедитесь, что новый узел создан:
$ oc получить узлыПример вывода
ИМЯ СТАТУС РОЛИ ВОЗРАСТ ВЕРСИЯ ip-10-0-128-78.ec2.internal Готовый рабочий 117m v1.23.0+60f5a1c ip-10-0-146-113.ec2.internal Готовый мастер 127m v1.23.0+60f5a1c ip-10-0-153-35.ec2.internal Готовый рабочий 118m v1.23.0+60f5a1c ip-10-0-176-58.ec2.internal Готовый мастер 126m v1.23.0+60f5a1c ip-10-0-217-135.ec2.internal Готовый рабочий 2m57s v1.23.0+60f5a1c (1) ip-10-0-225-248.ec2.internal Готовый мастер 127m v1.23.0+60f5a1c ip-10-0-245-59.ec2.internal Готовый рабочий 116m v1.23.0+60f5a1c
1 Это новый новый узел. Убедитесь, что пользовательский раздел
/varсоздан на новом узле:$ oc отладочный узел/<имя-узла> -- chroot /host lsblkНапример:
$ oc отладочный узел/ip-10-0-217-135.ec2.internal -- chroot /host lsblkПример вывода
НАЗВАНИЕ MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 202:0 0 120G 0 диск |-nvme0n1p1 202:1 0 1M 0 часть |-nvme0n1p2 202:2 0 127M 0 часть |-nvme0n1p3 202:3 0 384M 0 часть /загрузка `-nvme0n1p4 202:4 0 119.5G 0 часть /sysroot nvme1n1 202:16 0 50G 0 диск `-nvme1n1p1 202:17 0 48.8G 0 часть /var (1)
1 Устройство nvme1n1установлено на/varраздел.Дополнительные ресурсы
Развертывание проверок работоспособности компьютеров
Понимание и развертывание проверок работоспособности компьютеров.
Этот процесс неприменим для кластеров с машинами, подготовленными вручную. Вы можете использовать расширенные возможности управления машинами и масштабирования только в кластерах, где работает Machine API.
О проверках работоспособности машин
Проверки работоспособности машин автоматически восстанавливают неработоспособные машины в определенном пуле машин.
Для мониторинга работоспособности машины создайте ресурс для определения конфигурации контроллера.
Установите условие для проверки, например пребывание в состоянии
NotReadyв течение пяти минут или отображение постоянного состояния в детекторе проблем узла, а также метку для набора компьютеров, которые необходимо отслеживать.
Вы не можете применить проверку работоспособности машины к машине с главной ролью.
Контроллер, который наблюдает за ресурсом
MachineHealthCheck, проверяет определенное условие. Если машина не проходит проверку работоспособности, она автоматически удаляется и вместо нее создается другая. Когда машина удаляется, вы видите событиемашина удалена.Чтобы ограничить разрушительное воздействие удаления машины, контроллер сбрасывает и удаляет только один узел за раз. Если нездоровых машин больше, чем
maxUnhealthyпорог позволяет в целевом пуле компьютеров остановить исправление и, следовательно, разрешить вмешательство вручную.
Внимательно рассмотрите время ожидания с учетом рабочих нагрузок и требований.
Длительные тайм-ауты могут привести к длительным периодам простоя рабочей нагрузки на неисправном компьютере.
Слишком короткие тайм-ауты могут привести к зацикливанию исправления. Например, тайм-аут для проверки
Состояние NotReadyдолжно быть достаточно длинным, чтобы машина могла завершить процесс запуска.Чтобы остановить проверку, удалите ресурс.
Ограничения при развертывании проверок работоспособности компьютеров
Существуют ограничения, которые следует учитывать перед развертыванием проверки работоспособности компьютеров:
Только машины, принадлежащие набору машин, исправляются проверкой работоспособности машины.
Машины уровня управления в настоящее время не поддерживаются и не исправляются, если они неработоспособны.
Если узел для машины удаляется из кластера, проверка работоспособности машины считает машину неработоспособной и немедленно исправляет ее.
Если соответствующий узел для машины не присоединяется к кластеру после
nodeStartupTimeout, машина исправляется.Машина исправляется немедленно, если фаза ресурсов
Машинаимеет значениеСбой.Образец ресурса MachineHealthCheck
Ресурс
MachineHealthCheckдля всех типов облачной установки, кроме «голого железа», похож на следующий файл YAML:apiVersion: machine.openshift.io/v1beta1 вид: MachineHealthCheck метаданные: имя: пример (1) пространство имен: openshift-machine-api спецификация: селектор: метки соответствия: machine.openshift.io/cluster-api-machine-role: <роль> (2) machine.openshift.io/cluster-api-machine-type: <роль> (2) machine.openshift.io/cluster-api-machineset: <имя_кластера>-<метка>-<зона> (3) нездоровые условия: - тип: "Готово" время ожидания: «300 с» (4) статус: "Ложь" - тип: "Готово" время ожидания: «300 с» (4) Статус неизвестен" maxUnhealthy: "40%" (5) nodeStartupTimeout: "10m" (6)
1 Укажите имя развертываемой проверки работоспособности компьютера. 2 Укажите метку для пула машин, который вы хотите проверить. 3 Укажите компьютер для отслеживания в формате <имя_кластера>-<метка>-<зона>. Например,prod-node-us-east-1a.4 Укажите время ожидания для условия узла. Если условие выполняется в течение тайм-аута, машина будет восстановлена. Длительные тайм-ауты могут привести к длительным периодам простоя рабочей нагрузки на неработоспособной машине.
5 Укажите количество машин, которые можно одновременно исправлять в целевом пуле. Это может быть установлено как процент или целое число. Если количество неработоспособных машин превышает предел, установленный параметром maxUnhealthy, исправление не выполняется.6 Укажите продолжительность тайм-аута, в течение которого проверка работоспособности компьютера должна ждать, пока узел не присоединится к кластеру, прежде чем компьютер будет признан неработоспособным.
matchLabelsприведены только в качестве примера; вы должны сопоставить свои группы машин на основе ваших конкретных потребностей.Короткое замыкание Исправление проверки работоспособности машины
Короткое замыкание гарантирует, что проверка работоспособности машины исправит машины только тогда, когда кластер исправен.
Короткое замыкание настраивается с помощью поляmaxUnhealthyв ресурсеMachineHealthCheck.Если пользователь определяет значение для поля
maxUnhealthy, перед исправлением каких-либо машин функцияMachineHealthCheckсравнивает значениеmaxUnhealthyс количеством машин в целевом пуле, которые были определены как неработоспособные. Исправление не выполняется, если количество неработоспособных машин превышает пределmaxUnhealthy.
Если
maxUnhealthyне задано, значение по умолчанию равно100%и машины исправляются независимо от состояния кластера.Соответствующее значение
maxUnhealthyзависит от масштаба кластера, который вы развертываете, и от того, сколько компьютеров охватываетMachineHealthCheck.Например, вы можете использовать значение
maxUnhealthyдля охвата нескольких наборов компьютеров в нескольких зонах доступности, чтобы в случае потери всей зоны параметрmaxUnhealthyпредотвратил дальнейшее исправление в кластере. В глобальных регионах Azure, в которых нет нескольких зон доступности, вы можете использовать группы доступности для обеспечения высокой доступности.В поле
maxUnhealthyможно указать целое число или процентное значение.
Существуют различные реализации исправления в зависимости от значенияmaxUnhealthy.Настройка maxUnhealthy с использованием абсолютного значения
Если для
maxUnhealthyзадано значение2:Эти значения не зависят от того, сколько машин проверяется при проверке работоспособности машины.
Настройка maxUnhealthy с использованием процентов
Если
maxUnhealthyимеет значение40%и проверяются 25 машин:Если для
maxUnhealthyустановлено значение40%и проверяются 6 машин:
2 2
Допустимое количество компьютеров округляется в меньшую сторону, если процентная доля
maxUnhealthyпроверенных машин не является целым числом.Создание ресурса MachineHealthCheck
Вы можете создать 9Ресурс 1152 MachineHealthCheck для всех
MachineSetв вашем кластере.
Не следует создавать ресурсMachineHealthCheck, нацеленный на компьютеры плоскости управления.Предпосылки
Процедура
Создайте файл
healthcheck.yml, содержащий определение проверки работоспособности вашего компьютера.Примените файл
healthcheck.ymlк вашему кластеру:$ oc применить -f Healthcheck.ymlМасштабирование набора машин вручную
Чтобы добавить или удалить экземпляр машины в наборе машин, вы можете масштабировать набор машин вручную.
Это руководство относится к полностью автоматизированным установкам инфраструктуры, предоставляемым установщиком. Настраиваемые, подготовленные пользователем установки инфраструктуры не имеют наборов машин.
Предпосылки
Процедура
Просмотр наборов машин в кластере:
$ oc get machinesets -n openshift-machine-apiНаборы компьютеров перечислены в виде
.-worker- Просмотр машин в кластере:
$ oc get machine -n openshift-machine-apiУстановите аннотацию на машину, которую хотите удалить:
$ oc annotate machine/-n openshift-machine-api machine.openshift.io/cluster-api-delete-machine="true" Оцепить и слить узел, который нужно удалить:
$ oc адм кордон <имя_узла> $ oc адм сливНабор весов для машины:
$ oc scale --replicas=2 machineset <набор машин> -n openshift-machine-apiИли:
$ oc изменить набор машин <набор машин> -n openshift-machine-api
В качестве альтернативы можно применить следующий YAML для масштабирования набора компьютеров:
версия API: machine.openshift.io/v1beta1 вид: Машинсет метаданные: имя: <набор машин> пространство имен: openshift-machine-api спецификация: реплики: 2
Вы можете масштабировать настройку машины вверх или вниз. Доступ к новым машинам занимает несколько минут.
Проверка
Понимание различий между наборами машин и пулом конфигурации машин
Объекты MachineSetописывают узлы OpenShift Container Platform относительно поставщика облака или машины.Объект
MachineConfigPoolпозволяет компонентамMachineConfigControllerопределять и обеспечивать состояние машин в контексте обновлений.Объект
MachineConfigPoolпозволяет пользователям настраивать способ развертывания обновлений для узлов OpenShift Container Platform в пуле конфигурации машин.Объект
NodeSelectorможно заменить ссылкой на объектMachineSet.Рекомендуемые методы работы узла узла
Файл конфигурации узла OpenShift Container Platform содержит важные параметры.
За
например, два параметра управляют максимальным количеством pod’ов, которые можно запланировать.
на узел:podsPerCoreиmaxPods.Когда используются обе опции, меньшее из двух значений ограничивает количество
стручки на узле. Превышение этих значений может привести к:
Повышенная загрузка ЦП.
Медленное планирование pod.
Возможные сценарии нехватки памяти в зависимости от объема памяти в узле.
Исчерпан пул IP-адресов.
Перераспределение ресурсов, что приводит к снижению производительности пользовательских приложений.
В Kubernetes модуль, содержащий один контейнер, на самом деле использует два контейнера.
контейнеры. Второй контейнер используется для настройки сети до
фактический запуск контейнера. Таким образом, система с 10 модулями фактически
запустить 20 контейнеров.
Регулирование дисковых операций ввода-вывода в секунду от облачного провайдера может повлиять на CRI-O и kubelet.
Они могут быть перегружены, когда на них запущено большое количество модулей с интенсивным вводом-выводом.
узлы. Рекомендуется отслеживать дисковый ввод-вывод на узлах и использовать тома.
с достаточной пропускной способностью для рабочей нагрузки.
podsPerCoreустанавливает количество модулей, которые может запускать узел, в зависимости от количества
ядер процессора на узле. Например, еслиpodsPerCoreустановлен на10на
узел с 4 ядрами процессора, максимальное количество модулей, разрешенных на узле, будет
быть40.kubeletConfig: podsPerCore: 10Установка
podsPerCoreна0отключает это ограничение. По умолчанию0.
podsPerCoreне может превышатьmaxPods.
maxPodsзадает количество модулей, которые может запускать узел, равным фиксированному значению, независимо от
свойств узла.kubeletConfig: maxPods: 250Создание CRD KubeletConfig для редактирования параметров kubelet
Конфигурация kubelet в настоящее время сериализована как конфигурация Ignition, поэтому ее можно редактировать напрямую. Однако в Контроллер конфигурации машины (MCC) добавлен новый
kubelet-config-controller. Это позволяет использовать пользовательский ресурс (CR)KubeletConfigдля редактирования параметров kubelet.
Поскольку поля в объекте
kubeletConfigпередаются напрямую в kubelet из вышестоящего Kubernetes, kubelet проверяет эти значения напрямую. Недопустимые значения в объектеkubeletConfigмогут привести к тому, что узлы кластера станут недоступными. Допустимые значения см.в документации Kubernetes.
Обратите внимание на следующие рекомендации:
Создайте один
KubeletConfigCR для каждого пула конфигурации компьютеров со всеми изменениями конфигурации, которые вы хотите для этого пула. Если вы применяете один и тот же контент ко всем пулам, вам нужен только одинKubeletConfigCR для всех пулов.Отредактируйте существующий CR
KubeletConfigCR, чтобы изменить существующие параметры или добавить новые параметры, вместо создания CR для каждого изменения. Рекомендуется создавать CR только для изменения другого пула конфигурации машин или для изменений, которые должны быть временными, чтобы можно было отменить изменения.При необходимости создайте несколько CR
KubeletConfigс ограничением 10 на кластер. Для первыхKubeletConfigCR, оператор конфигурации машины (MCO) создает конфигурацию машины с добавлениемkubelet.С каждым последующим CR контроллер создает еще один конфиг машины
kubeletс числовым суффиксом. Например, если у вас есть конфигурация машиныkubeletс суффиксом-2, к следующей конфигурации машиныkubeletдобавляется-3.Если вы хотите удалить конфигурации машины, удалите их в обратном порядке, чтобы не превысить лимит. Например, вы удаляете
kubelet-3конфигурация машины перед удалениемkubelet-2конфигурация машины.
Если у вас есть конфигурация машины с суффиксом
kubelet-9, и вы создаете другуюKubeletConfigCR, новая конфигурация машины не создается, даже если имеется менее 10 конфигураций машиныkubelet.Пример
KubeletConfigCR$ oc get kubeletconfigИМЯ ВОЗРАСТ set-max-pods 15mПример конфигурации машины
KubeletConfig$ oc get mc | grep кубелет... 99-сгенерированный-рабочим-кубелет-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m ...
Следующая процедура представляет собой пример, показывающий, как настроить максимальное количество модулей pod на узел на рабочих узлах.
Предпосылки
Получить метку, связанную со статическим
MachineConfigPoolCR для типа узла, который вы хотите настроить.
Выполните один из следующих шагов:
Просмотр пула конфигурации машин:
$ oc описать machineconfigpool <имя>Например:
$ oc описать работника machineconfigpoolПример вывода
apiVersion: machineconfiguration.openshift.io/v1 вид: Машинконфигпул метаданные: СозданиеTimestamp: 2019-02-08T14:52:39Z поколение: 1 этикетки: пользовательский кубелет: set-max-pods (1)
1 Если метка была добавлена, она отображается под метками.Если метка отсутствует, добавьте пару ключ/значение:
$ oc label machineconfigpool worker custom-kubelet=set-max-podsПроцедура
Просмотр доступных объектов конфигурации машины, которые можно выбрать:
$ oc получить конфиг машиныПо умолчанию две конфигурации, связанные с kubelet, — это
01-master-kubeletи01-worker-kubelet.Проверьте текущее значение максимального количества модулей на узел:
.
$ oc описать узелНапример:
$ oc описать узел ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94Найдите значение
: pods:в разделеAllocatable:Пример вывода
Распределяемый: присоединяемые-тома-aws-ebs: 25 процессор: 3500 м огромные страницы-1Gi: 0 огромные страницы-2Ми: 0 память: 15341844Ки капсулы: 250Установите максимальное количество модулей на узел на рабочих узлах, создав пользовательский файл ресурсов, содержащий конфигурацию kubelet:
версия API: machineconfiguration.openshift.io/v1 вид: KubeletConfig метаданные: имя: set-max-стручки спецификация: машинаКонфигпулселектор: метки соответствия: пользовательский кубелет: set-max-pods (1) кубелетКонфигурация: maxPods: 500 (2)
1 Введите метку из пула конфигурации машин. 2 Добавьте конфигурацию kubelet. В этом примере используйте maxPods, чтобы установить максимальное количество модулей на узел.
Скорость, с которой kubelet взаимодействует с сервером API, зависит от запросов в секунду (QPS) и значений пакетов. Значения по умолчанию,
50дляkubeAPIQPSи100дляkubeAPIBurstдостаточно, если на каждом узле работает ограниченное количество модулей. Рекомендуется обновлять kubelet QPS и Burst Rate, если на узле достаточно ресурсов ЦП и памяти.версия API: machineconfiguration.openshift.io/v1 вид: KubeletConfig метаданные: имя: set-max-стручки спецификация: машинаКонфигпулселектор: метки соответствия: пользовательский кубелет: set-max-pods кубелетКонфигурация: maxPods:kubeAPIBurst: kubeAPIQPS:
Обновите пул конфигурации машин для рабочих с меткой:
$ oc label machineconfigpool worker custom-kubelet=large-podsСоздайте объект
KubeletConfig:$ oc create -f change-maxPods-cr.yamlУбедитесь, что объект
KubeletConfigсоздан:$ oc получить kubeletconfigПример вывода
ИМЯ ВОЗРАСТ set-max-стручки 15мВ зависимости от количества рабочих узлов в кластере подождите, пока рабочие узлы будут перезагружены один за другим.
Для кластера с 3 рабочими узлами это может занять от 10 до 15 минут.
Убедитесь, что изменения применены к узлу:
Проверить на рабочем узле, что значение
maxPodsизменилось:$ oc описать узелНайдите
выделяемыхстрофа:... Распределяемый: присоединяемые-тома-gce-pd: 127 процессор: 3500 м эфемерное хранилище: 123201474766 огромные страницы-1Gi: 0 огромные страницы-2Ми: 0 память: 14225400Ки капсулы: 500 (1) ...
1 В этом примере параметр podsдолжен сообщать значение, установленное вKubeletConfigобъект.Проверьте изменение в объекте
KubeletConfig:$ oc получить kubeletconfigs set-max-pods -o yamlЭто должно показывать состояние
Trueиtype:Success, как показано в следующем примере:спецификация: кубелетКонфигурация: максимальное количество подов: 500 машинаКонфигпулселектор: метки соответствия: пользовательский кубелет: set-max-pods статус: условия: - lastTransitionTime: "2021-06-30T17:04:07Z" сообщение: Успех статус: "Верно" тип: УспехИзменение количества недоступных рабочих узлов
По умолчанию только одна машина может быть недоступна при применении конфигурации, связанной с kubelet, к доступным рабочим узлам.
Для большого кластера может потребоваться много времени, чтобы изменение конфигурации отразилось. В любое время вы можете настроить количество машин, которые обновляются, чтобы ускорить процесс.
Процедура
Изменить пул конфигурации машин
worker:$ oc edit machineconfigpool workerЗадайте для параметра
maxUnreachableжелаемое значение:.
спецификация: maxUnreachable:
При установке значения учитывайте количество рабочих узлов, которые могут быть
недоступен, не затрагивая приложения, работающие в кластере.Размер узла плоскости управления
Требования к ресурсам узла плоскости управления зависят от количества и типа узлов и объектов в кластере. Следующие рекомендации по размеру узла плоскости управления основаны на результатах тестирования, ориентированного на плотность плоскости управления, или Плотность кластеров .
Этот тест создает следующие объекты в заданном количестве пространств имен:
1 поток изображений
1 сборка
5 развертываний с 2 репликами pod в состоянии
сна, монтирование 4 секретов, 4 карты конфигурации и 1 нисходящий том API каждый5 служб, каждая из которых указывает на порты TCP/8080 и TCP/8443 одного из предыдущих развертываний
1 маршрут, указывающий на первую из предыдущих служб
10 секретов, содержащих 2048 случайных строковых символов
10 карт конфигурации, содержащих 2048 случайных строковых символов
Количество рабочих узлов Плотность кластера (пространства имен) ядер процессора Память (ГБ) 27
500
4
16
120
1000
8
32
252
4000
16
64
501
4000
16
96
В большом и плотном кластере с тремя главными узлами или узлами уровня управления использование ЦП и памяти резко возрастает, когда один из узлов останавливается, перезагружается или выходит из строя.
Сбои могут быть вызваны непредвиденными проблемами с питанием, сетью или базовой инфраструктурой, а также преднамеренными случаями, когда кластер перезапускается после его выключения для экономии средств. Оставшиеся два узла плоскости управления должны обрабатывать нагрузку, чтобы быть высокодоступными, что приводит к увеличению использования ресурсов. Это также ожидается во время обновлений, поскольку главные устройства блокируются, сбрасываются и последовательно перезагружаются для применения обновлений операционной системы, а также обновлений операторов плоскости управления. Чтобы избежать каскадных сбоев, поддерживайте общее использование ресурсов ЦП и памяти на узлах плоскости управления не более 60 % от всей доступной емкости, чтобы справляться с резкими скачками использования ресурсов. Соответственно увеличьте ресурсы ЦП и памяти на узлах плоскости управления, чтобы избежать возможных простоев из-за нехватки ресурсов.
Размер узла зависит от количества узлов и количества объектов в кластере.
Это также зависит от того, активно ли объекты создаются в кластере. Во время создания объекта плоскость управления более активна с точки зрения использования ресурсов по сравнению с тем, когда объекты находятся в
работающей фазе.Диспетчер жизненного цикла оператора (OLM) работает на узлах плоскости управления, и его объем памяти зависит от количества пространств имен и установленных пользователем операторов, которыми OLM должен управлять в кластере. Узлы плоскости управления должны иметь соответствующий размер, чтобы избежать уничтожения OOM. Следующие точки данных основаны на результатах тестирования максимумов кластера.
Количество пространств имен Память OLM в режиме ожидания (ГБ) Память OLM с 5 установленными пользовательскими операторами (ГБ) 500
0,823
1,7
1000
1,2
2,5
1500
1,7
3,2
2000
2
4,4
3000
2,7
5,6
4000
3,8
7,6
5000
4.
2
9.02
6000
5,8
11,3
7000
6,6
12,9
8000
6,9
14,8
9000
8
17,7
10 000
9,9
21,6
Если вы использовали метод установки инфраструктуры, предоставленный установщиком, вы не можете изменить размер узла плоскости управления в работающем кластере OpenShift Container Platform 4.10. Вместо этого вы должны оценить общее количество узлов и использовать предлагаемый размер узла плоскости управления во время установки.
Рекомендации основаны на точках данных, полученных в кластерах OpenShift Container Platform с OpenShift SDN в качестве сетевого подключаемого модуля.
В OpenShift Container Platform 4.10 половина ядра ЦП (500 миллиядер) теперь резервируется системой по умолчанию по сравнению с OpenShift Container Platform 3.11 и предыдущими версиями. Размеры определяются с учетом этого.
Настройка диспетчера ЦП
Процедура
Необязательно: Пометьте узел:
# узел метки oc perf-node.example.com cpumanager=trueОтредактируйте
MachineConfigPoolузлов, на которых должен быть включен диспетчер ЦП. В этом примере у всех воркеров включен диспетчер ЦП:# oc edit machineconfigpool workerДобавить метку в конфигурационный пул рабочих машин:
метаданных: Отметка времени создания: 2020-xx-xxx поколение: 3 этикетки: custom-kubelet: cpumanager-enabledСоздайте
KubeletConfig,cpumanager-kubeletconfig., пользовательский ресурс (CR). Обратитесь к метке, созданной на предыдущем шаге, чтобы обновить правильные узлы с новой конфигурацией kubelet. См. разделyaml
machineConfigPoolSelector:.
версия API: machineconfiguration.openshift.io/v1 вид: KubeletConfig метаданные: имя: с поддержкой cpumanager спецификация: машинаКонфигпулселектор: метки соответствия: custom-kubelet: cpumanager-enabled кубелетКонфигурация: cpuManagerPolicy: статический (1) cpuManagerReconcilePeriod: 5 с (2)
1 Укажите политику:
нет. Эта политика явно включает существующую схему привязки ЦП по умолчанию, не предоставляя привязки, кроме того, что планировщик делает автоматически.
статический. Эта политика позволяет модулям с определенными характеристиками ресурсов предоставлять повышенную привязку ЦП и эксклюзивность на узле.2 Дополнительно. Укажите частоту согласования диспетчера ЦП. По умолчанию 5s.Создайте динамическую конфигурацию кублета:
# oc create -f cpumanager-kubeletconfig.yamlЭто добавляет функцию диспетчера ЦП в конфигурацию kubelet, и, при необходимости, оператор конфигурации машины (MCO) перезагружает узел. Чтобы включить диспетчер ЦП, перезагрузка не требуется.
Проверить объединенную конфигурацию kubelet:
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | ссылка владельца grep -A7Пример вывода
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "вид": "KubeletConfig", "name": "cpumanager-включен", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]Проверить воркер на наличие обновлений
кубелет.:конф
# узел отладки oc/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep менеджер процессораПример вывода
cpuManagerPolicy: static (1) cpuManagerReconcilePeriod: 5 с (1)
1 Эти параметры были определены при создании KubeletConfigCR.Создайте модуль, который запрашивает одно или несколько ядер. И лимиты, и запросы должны иметь значение ЦП, равное целому числу. Это количество ядер, которые будут выделены для этого модуля:
# кошка cpumanager-pod.yamlПример вывода
apiVersion: v1 вид: стручок метаданные: generateName: cpumanager- спецификация: контейнеры: - имя: cpumanager изображение: gcr.io/google_containers/pause-amd64:3.0 Ресурсы: Запросы: процессор: 1 память: "1G" пределы: процессор: 1 память: "1G" селектор узла: cpumanager: "истина"
Создать модуль:
# oc create -f cpumanager-pod.yamlУбедитесь, что модуль запланирован на узел, который вы пометили:
# oc описывает под cpumanagerПример вывода
Имя: cpumanager-6cqz7 Пространство имен: по умолчанию Приоритет: 0 PriorityClassName: <нет> Узел: perf-node.example.com/xxx.xx.xx.xxx ... Ограничения: процессор: 1 память: 1G Запросы: процессор: 1 память: 1G ... Класс QoS: гарантированный Селекторы узлов: cpumanager=trueУбедитесь, что
контрольные группынастроены правильно. Получить идентификатор процесса (PID) процессаpause:# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /пауза
Пакеты уровня качества обслуживания (QoS)
Гарантированныеразмещены в пределахкубеподс.срез. Поды других уровней QoS попадают в дочерние группыcgroupsизкубеподов:# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b812c06f.665c86e958e958 # для i в `ls cpuset.cpus tasks`; выполнить эхо -n "$i"; кот $i ; сделаноПример вывода
cpuset.cpus 1 задачи 32706Проверить список разрешенных процессоров для задачи: 9Cpus_allowed_list /proc/32706/статус
Пример вывода
Cpus_allowed_list: 1Убедитесь, что другой модуль (в данном случае модуль на уровне
с возможностью расширенияQoS) в системе не может работать на ядре, выделенном для модуляGuaranteed:# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0557fac47cafe75434c57abbf99e3849.scope/cpuset.cpus 0 # oc описать узел perf-node.example.com
Пример вывода
... Вместимость: присоединяемые-тома-aws-ebs: 39 процессор: 2 эфемерное хранилище: 124768236Ki огромные страницы-1Gi: 0 огромные страницы-2Ми: 0 память: 8162900Ки стручки: 250 Распределяемый: присоединяемые-тома-aws-ebs: 39 процессор: 1500 м эфемерное хранилище: 124768236Ki огромные страницы-1Gi: 0 огромные страницы-2Ми: 0 память: 7548500Ки стручки: 250 ------- ---- ------------ ---------- --------------- -- ----------- --- cpumanager-6cqz7 по умолчанию 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29м Выделенные ресурсы: (Общие лимиты могут превышать 100 процентов, т. е. превышены лимиты.) Ограничения запросов ресурсов -------- -------- ------ процессор 1440м (96%) 1 (66%)Эта виртуальная машина имеет два ядра ЦП.
Параметр
, зарезервированный системой, резервирует 500 миллиядер, что означает, что половина одного ядра вычитается из общей емкости узла, чтобы получить количествоNode Allocatable. Вы можете видеть, чтоВыделяемый ЦПсоставляет 1500 миллиядер. Это означает, что вы можете запустить один из модулей CPU Manager, поскольку каждый из них будет занимать одно целое ядро. Целое ядро эквивалентно 1000 миллиядрам. Если вы попытаетесь запланировать второй модуль, система примет его, но никогда не запланирует:ИМЯ ГОТОВ СТАТУС ПЕРЕЗАПУСКА ВОЗРАСТ cpumanager-6cqz7 1/1 Бег 0 33м cpumanager-7qc2t 0/1 Ожидание 0 11 сОгромные страницы
Понимать и настраивать огромные страницы.
Что делают огромные страницы
Память управляется блоками, известными как страницы. В большинстве систем страница имеет размер 4Ki. 1Ми
объем памяти равен 256 страницам; 1 гигабайт памяти — это 256 000 страниц и так далее.процессоры
иметь встроенный блок управления памятью, который управляет списком этих страниц в
аппаратное обеспечение. Резервный буфер перевода (TLB) — это небольшой аппаратный кэш
сопоставления виртуальных и физических страниц. Если виртуальный адрес передан аппаратному
Инструкцию можно найти в TLB, отображение можно определить быстро. Если
нет, происходит промах TLB, и система возвращается к более медленному программному
преобразование адресов, что приводит к проблемам с производительностью. Поскольку размер TLB
исправлено, единственный способ уменьшить вероятность промаха TLB — увеличить
размер страницы.Огромная страница — это страница памяти, размер которой превышает 4 КБ. На архитектурах x86_64,
есть два распространенных огромных размера страниц: 2Mi и 1Gi. Размеры варьируются в зависимости от других
архитектуры. Чтобы использовать огромные страницы, код должен быть написан так, чтобы
приложения знают о них. Transparent Huge Pages (THP) пытается автоматизировать
управление огромными страницами без знания приложений, но у них есть
ограничения.В частности, они ограничены размером страницы 2Mi. ТП может привести к
снижение производительности на узлах с высоким использованием памяти или фрагментацией
из-за усилий по дефрагментации THP, которые могут блокировать страницы памяти. Для этого
причине, некоторые приложения могут быть разработаны (или рекомендовать) использование
предварительно выделены огромные страницы вместо THP.Как огромные страницы потребляются приложениями
Узлы должны предварительно выделять огромные страницы, чтобы узел сообщал о своей огромной странице
вместимость. Узел может предварительно выделить огромные страницы только для одного размера.Огромные страницы могут потребляться из-за требований к ресурсам на уровне контейнера с помощью
имя ресурсаhugepages-, где размер — это самый компактный двоичный файл
нотация с использованием целочисленных значений, поддерживаемых на конкретном узле. Например, если
узел поддерживает размеры страниц 2048 КБ, он предоставляет планируемый ресурс
огромные страницы-2Ми.В отличие от процессора или памяти, огромные страницы не поддерживают чрезмерное выделение ресурсов.
APIВерсия: v1 вид: стручок метаданные: generateName: огромные страницы-объем- спецификация: контейнеры: - контекст безопасности: привилегированный: правда изображение: rhel7: последний команда: - спать - инф имя: пример томМаунты: - путь монтирования: /dev/hugepages имя: огромная страница Ресурсы: пределы: огромные страницы-2Ми: 100Ми (1) память: "1Gi" процессор: "1" тома: - имя: огромная страница пустойКаталог: среда: HugePages
1 Укажите объем памяти для огромных страницкак точный объем
выделено. Не указывайте это значение как объем памяти дляогромных страниц
умножается на размер страницы. Например, учитывая огромный размер страницы в 2 МБ,
если вы хотите использовать 100 МБ оперативной памяти с огромным объемом страниц для своего приложения, то вы
выделил бы 50 огромных страниц.Контейнерная платформа OpenShift сделает все за вас. Как в
приведенный выше пример, вы можете указать100 МБнапрямую.Выделение больших страниц определенного размера
Некоторые платформы поддерживают несколько огромных страниц. Чтобы выделить огромные страницы
определенного размера, перед параметрами команды загрузки огромных страниц следует указать огромную страницу
параметр выбора размераhugepagesz=. Значениедолжно быть
указывается в байтах с необязательным суффиксом масштаба [kKmMgG]. По умолчанию огромный
размер страницы можно определить с помощьюdefault_hugepagesz=<размер>параметр загрузки.Требуются огромные страницы
Огромные запросы страниц должны соответствовать ограничениям. Это значение по умолчанию, если ограничения
указано, а запросы нет.Огромные страницы изолированы в области действия модуля.
Изоляция контейнеров планируется
будущая итерация.
Тома EmptyDir, поддерживаемые огромными страницами, не должны занимать больше памяти больших страниц
чем запрос пода.Приложения, потребляющие огромные страницы через
shmget()сSHM_HUGETLB, должны работать
с дополнительной группой, которая соответствует proc/sys/vm/hugetlb_shm_group .Дополнительные ресурсы
Настройка прозрачных огромных страниц
Настройка больших страниц
Узлы должны предварительно выделять огромные страницы, используемые в кластере OpenShift Container Platform. Существует два способа резервирования огромных страниц: во время загрузки и во время выполнения. Резервирование во время загрузки повышает вероятность успеха, поскольку память еще не была значительно фрагментирована. В настоящее время оператор настройки узла поддерживает выделение больших страниц во время загрузки на определенных узлах.
Во время загрузки
Процедура
Чтобы свести к минимуму количество перезагрузок узлов, необходимо соблюдать следующий порядок действий:
Пометьте меткой все узлы, которым требуются одинаковые настройки огромных страниц.
$ oc label nodenode-role.kubernetes.io/worker-hp= Создайте файл со следующим содержимым и назовите его
hugepages-tuned-boottime.yaml:apiVersion: настроенный.openshift.io/v1 вид: Тюнингованный метаданные: имя: огромные страницы (1) пространство имен: openshift-cluster-node-tuning-operator спецификация: профиль: (2) - данные: | [главный] summary=Конфигурация времени загрузки для огромных страниц include=openshift-узел [загрузчик] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50 (3) имя: openshift-node-hugepages рекомендовать: -Машинконфиглабелс: (4) machineconfiguration.openshift.io/role: "рабочий-hp" приоритет: 30 профиль: openshift-node-hugepages
1 Установите имянастроенного ресурса наhugepages.2 Установите раздел профиля для выделения больших страниц.3 Обратите внимание на порядок параметров, так как некоторые платформы поддерживают огромные страницы разных размеров. 4 Включить сопоставление на основе пула конфигурации машин. Создайте объект Tuned
hugepages$ oc create -f hugepages-tuned-boottime.yamlСоздайте файл со следующим содержимым и назовите его
hugepages-mcp.yaml:версия API: machineconfiguration.openshift.io/v1 вид: Машинконфигпул метаданные: имя: рабочий-hp этикетки: рабочий-л.с.: "" спецификация: селектор конфигурации машины: matchExpressions: - {ключ: machineconfiguration.openshift.io/role, оператор: In, значения: [worker,worker-hp]} селектор узла: метки соответствия: node-role.kubernetes.io/worker-hp: ""
Создать пул конфигурации машин:
$ oc create -f hugepages-mcp.yamlПри наличии достаточного количества нефрагментированной памяти всем узлам в пуле конфигурации машин
worker-hpтеперь должно быть выделено 50 огромных страниц размером 2Ми.$ oc получить узел-o jsonpath="{.status.allocatable.hugepages-2Mi}" 100Ми
Подключаемый модуль загрузчика TuneD в настоящее время поддерживается на рабочих узлах Red Hat Enterprise Linux CoreOS (RHCOS) 8.
x. Для рабочих узлов Red Hat Enterprise Linux (RHEL) 7.x подключаемый модуль загрузчика TuneD в настоящее время не поддерживается.
Общие сведения о подключаемых модулях устройств
Подключаемый модуль устройства обеспечивает согласованное и переносимое решение для использования оборудования
устройств в кластерах. Плагин устройства обеспечивает поддержку этих устройств.
через механизм расширения, который делает эти устройства доступными для
Containers, обеспечивает проверку работоспособности этих устройств и безопасно делится ими.
OpenShift Container Platform поддерживает API подключаемого модуля устройства, но подключаемый модуль устройства
Контейнеры поддерживаются отдельными поставщиками.Подключаемый модуль устройства — это служба gRPC, работающая на узлах (внешних по отношению к
kubelet), который отвечает за управление определенными
аппаратные ресурсы.Любой подключаемый модуль устройства должен поддерживать следующую удаленную процедуру
звонки (RPC):service DevicePlugin { // GetDevicePluginOptions возвращает параметры для связи с устройством // Управляющий делами rpc GetDevicePluginOptions(Empty) возвращает (DevicePluginOptions) {} // ListAndWatch возвращает поток List of Devices // Всякий раз, когда изменяется состояние устройства или устройство исчезает, ListAndWatch // возвращает новый список rpc ListAndWatch(Empty) возвращает (поток ListAndWatchResponse) {} // Allocate вызывается во время создания контейнера, чтобы устройство // Подключаемый модуль может выполнять операции, специфичные для устройства, и давать инструкции Kubelet. // из шагов, чтобы сделать Device доступным в контейнере rpc Allocate(AllocateRequest) возвращает (AllocateResponse) {} // PreStartcontainer вызывается, если это указано плагином устройства во время // этап регистрации, перед запуском каждого контейнера.Плагин устройства // может выполнять операции, специфичные для устройства, такие как сброс устройства // прежде чем сделать устройства доступными для контейнера rpc PreStartcontainer(PreStartcontainerRequest) возвращает (PreStartcontainerResponse) {} }
Пример подключаемых модулей
Подключаемый модуль графического процессора Nvidia для операционной системы на основе COS
Официальный подключаемый модуль графического процессора Nvidia
Плагин для устройства Solarflare
Плагины устройств KubeVirt: vfio и kvm
Подключаемый модуль устройства Kubernetes для карт IBM Crypto Express (CEX)
Для простой эталонной реализации подключаемого модуля устройства имеется подключаемый модуль устройства-заглушки.
в коде диспетчера устройств:
поставщик/k8s.io/kubernetes/pkg/kubelet/cm/deviceplugin/device_plugin_stub.go .
Методы развертывания подключаемого модуля устройства
- Наборы демонов
— рекомендуемый подход для развертывания подключаемых модулей устройств.
При запуске подключаемый модуль устройства попытается создать сокет домена UNIX в
/var/lib/kubelet/device-plugin/ на узле для обслуживания RPC из диспетчера устройств.Поскольку подключаемые модули устройств должны управлять аппаратными ресурсами, доступ к хосту
файловой системы, а также создание сокетов, они должны выполняться в привилегированном
контекст безопасности.Более подробные сведения о шагах развертывания можно найти на каждом устройстве.
реализация плагина.Понимание Диспетчера устройств
Диспетчер устройств предоставляет механизм объявления аппаратных ресурсов специализированного узла
с помощью подключаемых модулей, известных как подключаемые модули устройств.Вы можете рекламировать специализированное оборудование, не требуя каких-либо изменений исходного кода.
OpenShift Container Platform поддерживает API подключаемого модуля устройства, но подключаемый модуль устройства
Контейнеры поддерживаются отдельными поставщиками.Диспетчер устройств объявляет устройства как Расширенные ресурсы . Пользовательские модули могут потреблять
устройства, рекламируемые Диспетчером устройств, с использованием того же механизма Limit/Request ,
который используется для запроса любых других Расширенный ресурс .При запуске подключаемый модуль устройства регистрируется в Диспетчере устройств, вызывая
Зарегистрироватьна
/var/lib/kubelet/device-plugins/kubelet.sock и запускает службу gRPC в
/var/lib/kubelet/device-plugins/.sock для обслуживания диспетчера устройств
Запросы.Диспетчер устройств при обработке нового запроса на регистрацию вызывает
ListAndWatchудаленный вызов процедуры (RPC) в службе подключаемого модуля устройства. В
ответ, Диспетчер устройств получает список из Устройство объектов от плагина через
gRPC-поток. Диспетчер устройств будет следить за потоком новых обновлений
из плагина. Со стороны плагина плагин также будет поддерживать поток
открыты и всякий раз, когда происходит изменение состояния любого из устройств, новый
список устройств отправляется в Диспетчер устройств по тому же потоковому соединению.При обработке нового запроса на вход в модуль Kubelet запросил пропуски
Расширенныйв Диспетчер устройств для выделения устройств. Диспетчер устройств регистрируется
Ресурсы
свою базу данных, чтобы проверить, существует ли соответствующий подключаемый модуль или нет. Если плагин существует
и есть свободные выделяемые устройства, а также на локальный кеш,Распределить
RPC вызывается в этом конкретном подключаемом модуле устройства.Кроме того, подключаемые модули устройств также могут выполнять несколько других
операций, таких как установка драйвера, инициализация устройства и
сбрасывает. Эти функции варьируются от реализации к реализации.Включение диспетчера устройств
Включение диспетчера устройств для реализации подключаемого модуля устройства для рекламы специализированных
оборудование без каких-либо изменений исходного кода.Диспетчер устройств предоставляет механизм объявления аппаратных ресурсов специализированного узла.
с помощью подключаемых модулей, известных как подключаемые модули устройств.
Получите метку, связанную со статическим CRD
MachineConfigPoolдля типа узла, который вы хотите настроить.
Выполните один из следующих шагов:
Просмотр конфигурации машины:
# oc описать machineconfig <имя>Например:
# oc описать machineconfig 00-workerПример вывода
Имя: 00-рабочий Пространство имен: Ярлыки: machineconfiguration.openshift.io/role=worker (1)
1 Метка, необходимая для диспетчера устройств. Процедура
Создайте пользовательский ресурс (CR) для изменения конфигурации.
Пример конфигурации для диспетчера устройств CR
apiVersion: machineconfiguration.openshift.io/v1 вид: KubeletConfig метаданные: имя: устройствомгр (1) спецификация: машинаКонфигпулселектор: метки соответствия: machineconfiguration.openshift.io: диспетчер устройств (2) кубелетКонфигурация: особенности-ворота: - DevicePlugins=true (3)
1 Присвойте имя CR. 2 Введите метку из пула конфигурации машин. 3 Установить для DevicePluginsзначение «true».Создать Диспетчер устройств:
$ oc создать -f devicemgr.yamlПример вывода
kubeletconfig.machineconfiguration.openshift.io/devicemgr созданУбедитесь, что диспетчер устройств действительно включен, подтвердив, что
/var/lib/kubelet/device-plugins/kubelet.sock создается на узле. Это
сокет домена UNIX, на котором gRPC-сервер диспетчера устройств прослушивает новые
регистрации плагинов. Этот файл sock создается при запуске Kubelet.
только если включен Диспетчер устройств.Пороки и допуски
Понимание и работа с пометками и допусками.
Понимание пороков и допусков
Помеха позволяет узлу отказать в планировании модуля, если у этого модуля нет соответствующего допуска .
Вы применяете taints к узлу с помощью спецификации
Node(NodeSpec) и применяете допуски к поду с помощью спецификацииPod(PodSpec). Когда вы применяете заражение к узлу, планировщик не может разместить модуль на этом узле, если только модуль не может выдержать заражение.Пример порока в спецификации узла
спецификация: портит: - эффект: NoExecute ключ: ключ1 значение: значение1 ....Пример допуска в
Podспецификацияспецификация: допуски: - ключ: "key1" оператор: "Равно" значение: "значение1" эффект: "Не выполнять" допустимые секунды: 3600 ....Пороки и допуски состоят из ключа, значения и эффекта.
Таблица 1. Компоненты загрязнения и переносимости Параметр Описание Ключ
— любая строка длиной до 253 символов.Ключ должен начинаться с буквы или цифры и может содержать буквы, цифры, дефисы, точки и символы подчеркивания.
Значение
— это любая строка длиной до 63 символов. Значение должно начинаться с буквы или цифры и может содержать буквы, цифры, дефисы, точки и символы подчеркивания.
эффектЭффект может быть одним из следующих:
PreferNoSchedule
Новые модули, которые не соответствуют заражению, могут быть запланированы для этого узла, но планировщик пытается этого не делать.
Существующие модули на узле остаются.
Нет выполнения
оператор
Равный
ключ/значение/эффектпараметры должны совпадать.Это значение по умолчанию.
СуществуетПараметры
клавиши/эффектадолжны совпадать. Необходимо оставить пустымзначение параметра, которое соответствует любому.
Если вы добавите пометку
NoScheduleна узел плоскости управления, этот узел должен иметь пометкуnode-role.kubernetes.io/master=:NoSchedule, которая добавляется по умолчанию.Например:
APIВерсия: v1 вид: узел метаданные: аннотации: machine.openshift.io/машина: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0 machineconfiguration.openshift.io/currentConfig: визуализирован-мастер-cdc1ab7da414629332cc4c3926e6e59c ... спецификация: портит: - эффект: NoSchedule ключ: node-role.kubernetes.io/master ...Допуск соответствует заражению:















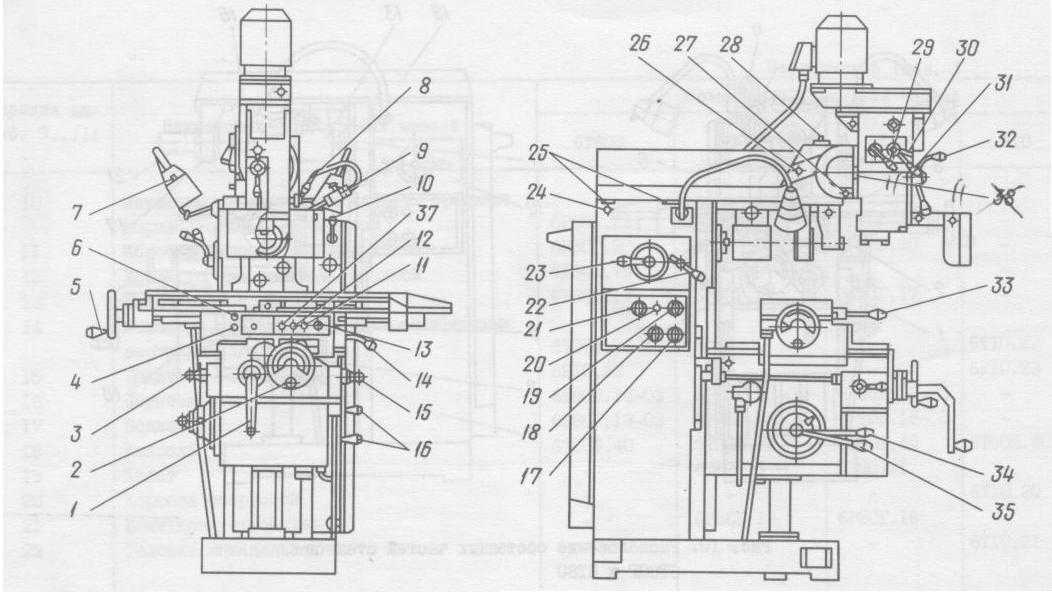
















Если для параметра
оператораустановлено значениеEqual:параметры
ключасовпадают;значение
эффектпараметры одинаковы.
Если параметр
оператораустановлен наExists:
Следующие дефекты встроены в OpenShift Container Platform:
node.kubernetes.io/not-ready: узел не готов. Это соответствует состоянию узлаReady=False.node.kubernetes.io/unreachable: узел недоступен с контроллера узла. Это соответствует условию узлаГотов=Неизвестно.node.kubernetes.io/memory-pressure: У узла проблемы с нехваткой памяти. Это соответствует условию узлаMemoryPressure=True.node.kubernetes.io/disk-pressure: У узла проблемы с давлением на диск. Это соответствует условию узлаDiskPressure=True.node.kubernetes.io/network-unavailable: Сеть узлов недоступна.node.: узел не подлежит планированию. kubernetes.io/unschedulable
kubernetes.io/unschedulable node.cloudprovider.kubernetes.io/uninitialized: когда контроллер узла запускается с помощью внешнего облачного провайдера, эта ошибка устанавливается на узле, чтобы пометить его как непригодный для использования. После того, как контроллер из cloud-controller-manager инициализирует этот узел, kubelet удаляет эту заразу.node.kubernetes.io/pid-pressure: узел имеет давление pid. Это соответствует условию узлаPIDPressure=Истина.OpenShift Container Platform не задает pid по умолчанию. Available
evictionHard.
Понимание того, как использовать допустимые секунды для задержки выселения модулей
Вы можете указать, как долго модуль может оставаться привязанным к узлу, прежде чем будет вытеснен, указав параметр tolerationSeconds в спецификации Pod или MachineSet объект. Если заражение с эффектом
Если заражение с эффектом NoExecute добавляется к узлу, поду, который допускает заражение и имеет параметр tolerationSeconds , под не удаляется до истечения этого периода времени.
Пример вывода
спецификация:
допуски:
- ключ: "key1"
оператор: "Равно"
значение: "значение1"
эффект: "Не выполнять"
tolerationSeconds: 3600 Здесь, если этот модуль работает, но не имеет соответствующего допуска, модуль остается привязанным к узлу в течение 3600 секунд, а затем удаляется. Если заражение удалено до этого времени, модуль не вытесняется.
Понимание того, как использовать несколько taints
Вы можете поместить несколько taints на один и тот же узел и несколько допусков на один и тот же модуль. Платформа контейнеров OpenShift обрабатывает несколько испорченных данных и допусков следующим образом:
Обработка испорченных данных, для которых модуль имеет соответствующий допуск.

Оставшиеся непревзойденные порчи оказывают на капсулу указанные эффекты:
Если есть хотя бы одна непревзойденная порча с эффектом
NoSchedule, OpenShift Container Platform не может запланировать модуль на этот узел.Если нет несопоставленного заражения с эффектом
NoSchedule, но есть хотя бы одно несопоставленное загрязнение с эффектомPreferNoSchedule, OpenShift Container Platform пытается не запланировать модуль на узел.Если имеется хотя бы одно несоответствующее заражение с эффектом
NoExecute, OpenShift Container Platform вытесняет модуль с узла, если он уже запущен на узле, или модуль не запланирован на узле, если он еще не запущен на узле. узел.Поды, которые не переносят заражение, немедленно удаляются.
Поды, которые допускают taint без указания
tolerationSecondsв спецификацииPod, остаются привязанными навсегда.
Поды, допускающие заражение с указанным значением
tolerationSeconds, остаются связанными в течение указанного периода времени.
Например:
Добавьте к узлу следующие дефекты:
$ oc административные узлы node1 key1=value1:NoSchedule
$ oc административные узлы node1 key1=value1:NoExecute
$ oc Административные узлы node1 key2=value2:NoSchedule
Блок имеет следующие допуски:
спецификация: допуски: - ключ: "key1" оператор: "Равно" значение: "значение1" эффект: "Без расписания" - ключ: "key1" оператор: "Равно" значение: "значение1" эффект: "NoExecute"
В этом случае модуль не может быть запланирован на узле, так как нет допуска, соответствующего третьему заражению. Модуль продолжает работать, если он уже запущен на узле, когда добавляется заражение, потому что третье заражение — единственное.
один из трех, который не терпит стручок.
Понимание планирования pod и состояния узлов (заражение узла по условию)
Функция «Заражение узлов по условию», которая включена по умолчанию, автоматически заражает узлы, которые сообщают о таких условиях, как нехватка памяти и нехватка диска. Если узел сообщает о состоянии, пометка добавляется до тех пор, пока условие не будет устранено. Загрязнения имеют Эффект NoSchedule означает, что ни один модуль не может быть запланирован на узле, если модуль не имеет соответствующего допуска.
Планировщик проверяет наличие этих дефектов на узлах перед планированием модулей. Если заражение присутствует, модуль планируется на другом узле. Поскольку планировщик проверяет наличие дефектов, а не фактические условия узла, вы настраиваете планировщик так, чтобы он игнорировал некоторые из этих условий узла, добавляя соответствующие допуски для модулей.
Для обеспечения обратной совместимости контроллер набора демонов автоматически добавляет следующие допуски ко всем демонам:
node.
 kubernetes.io/memory-давление
kubernetes.io/memory-давлениеузел.kubernetes.io/диск-давление
node.kubernetes.io/unschedulable (1.10 или более поздняя версия)
node.kubernetes.io/network-unavailable (только хост-сеть)
Вы также можете добавлять произвольные допуски к наборам демонов.
Плоскость управления также добавляет |
Понимание вытеснения модулей по условию (выселение на основе испорченных данных)
Функция вытеснения на основе испорченных данных, которая включена по умолчанию, вытесняет модули из узла, находящегося в определенных условиях, таких как не готов и недоступны .
Когда узел сталкивается с одним из этих условий, OpenShift Container Platform автоматически добавляет к узлу испорченные объекты и начинает вытеснять и перепланировать модули на разных узлах.
Выселение на основе испорченных данных имеют эффект NoExecute , при котором любой модуль, который не допускает заражения, немедленно удаляется, а любой модуль, допускающий наличие заражения, никогда не будет исключен, если только модуль не использует параметр tolerationSeconds .
Параметр tolerationSeconds позволяет указать, как долго модуль остается привязанным к узлу, имеющему условие узла. Если условие все еще существует после периода 91 152 tolerationSeconds 91 153, заражение остается на узле, а модули с соответствующим допуском удаляются. Если условие устраняется до периода 91 152 tolerationSeconds 91 153, модули с соответствующими допусками не удаляются.
Если вы используете параметр tolerationSeconds без значения, модули никогда не исключаются из-за условий неготовности и недостижимости узла.
OpenShift Container Platform вытесняет модули с ограничением скорости, чтобы предотвратить массовое вытеснение модулей в таких сценариях, как отделение главного узла от узлов. По умолчанию, если более 55 % узлов в данной зоне неработоспособны, контроллер жизненного цикла узла изменяет состояние этой зоны на Дополнительные сведения см. в разделе Ограничения частоты выселения в документации Kubernetes. |
OpenShift Container Platform автоматически добавляет допуск для node.kubernetes.io/not-ready и node.kubernetes.io/unreachable с tolerationSeconds=300 , если в конфигурации Pod не указано одно из допусков.
спецификация: допуски: - ключ: node.kubernetes.io/not-ready оператор: существует эффект: NoExecute терпимостьСекунды: 300 (1) - ключ: node.kubernetes.io/unreachable оператор: существует эффект: NoExecute допустимые секунды: 300
| 1 | Эти допуски гарантируют, что поведение модуля по умолчанию должно оставаться привязанным в течение пяти минут после обнаружения одной из этих проблем с условиями узла. |
Эти допуски можно настроить по мере необходимости. Например, если у вас есть приложение с большим количеством локальных состояний, вы можете захотеть сохранить привязку модулей к узлу в течение более длительного времени в случае сетевого раздела, что позволит восстановить раздел и избежать вытеснения модуля.
Поды, порожденные набором демонов, создаются с допусками NoExecute для следующих испорченных данных без tolerationSeconds :
В результате поды набора демонов никогда не удаляются из-за этих условий узла.
Допуск ко всем порокам
Вы можете настроить модуль так, чтобы он допускал все пороки, добавив оператор : "Существует" допуск без ключа и значения параметров.
Поды с таким допуском не удаляются с узла, имеющего дефекты.
Спецификация Pod для стойкости ко всем загрязнениям
спецификация: допуски: - оператор: «Существует»
Добавление пометок и допусков
Вы добавляете допуски к модулям и пометки к узлам, чтобы позволить узлу контролировать, какие модули должны или не должны быть запланированы для них. Для существующих модулей и узлов вы должны сначала добавить допуск к модулю, а затем добавить пометку к узлу, чтобы избежать удаления модулей с узла до того, как вы сможете добавить допуск.
Процедура
Добавьте допуск к поду, отредактировав спецификацию
пода, включив в нее разделдопусков:.

Пример файла конфигурации модуля со спецификацией оператора Equal
: допуски: - ключ: "key1" (1) значение: "значение1" оператор: "Равно" эффект: "Не выполнять" допустимые секунды: 3600 (2)1 Параметры допуска, как описано в Компоненты порчи и переносимости табл. 2 Параметр tolerationSecondsуказывает, как долго модуль может оставаться привязанным к узлу, прежде чем будет вытеснен.Например:
Пример файла конфигурации pod с оператором Exists
спецификация: допуски: - ключ: "key1" оператор: "Есть" (1) эффект: "Не выполнять" терпимостьСекунды: 36001 Оператор Existsне принимает значение
В этом примере заражение помещается на узел
node1с ключомkey1, значениемvalue1и эффектом зараженияNoExecute.Добавьте заражение к узлу с помощью следующей команды с параметрами, описанными в таблице компонентов заразы и допусков :
$ oc adm taint nodes
= : Например:
$ oc административные узлы node1 key1=value1:NoExecute
Эта команда размещает заражение на
node1с ключомkey1, значениемvalue1и эффектомNoExecute.Если вы добавите пометку
NoScheduleна узел плоскости управления, узел должен иметь роль узла.kubernetes.io/master=:NoScheduletaint, который добавляется по умолчанию.Например:
APIВерсия: v1 вид: узел метаданные: аннотации: machine. openshift.io/машина: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0
machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c
...
спецификация:
портит:
- эффект: NoSchedule
ключ: node-role.kubernetes.io/master
...
openshift.io/машина: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0
machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c
...
спецификация:
портит:
- эффект: NoSchedule
ключ: node-role.kubernetes.io/master
... Допуски на pod совпадают с taint на узле. Модуль с любым допуском может быть запланирован на
узел1.
Добавление пометок и допусков с помощью машинного набора
Вы можете добавлять пометки к узлам с помощью машинного набора. Все узлы, связанные с объектом MachineSet , обновляются с использованием taint. Допуски реагируют на пометки, добавленные машинным набором, так же, как пороки, добавленные непосредственно в узлы.
Процедура
Добавьте допуск к поду, отредактировав спецификацию
пода, чтобы включить допускиПример файла конфигурации модуля с оператором
Equal: допуски: - ключ: "key1" (1) значение: "значение1" оператор: "Равно" эффект: "Не выполнять" допустимые секунды: 3600 (2)1 Параметры допуска, как описано в таблице Компоненты загрязнения и допуска . 
2 Параметр tolerationSecondsуказывает, как долго модуль привязан к узлу, прежде чем будет вытеснен.Например:
Пример файла конфигурации модуля со спецификацией
Existsoperator: допуски: - ключ: "key1" оператор: "Существует" эффект: "Не выполнять" допустимые секунды: 3600Добавьте taint к объекту
MachineSet:Редактировать
MachineSetYAML для узлов, которые вы хотите испортить, или вы можете создать новый объектMachineSet:$ oc редактировать набор машин <набор машин>
Добавьте taint в раздел
spec.template.spec:Пример порчи в спецификации набора машин
спецификация: .... шаблон: .
 ...
спецификация:
портит:
- эффект: NoExecute
ключ: ключ1
значение: значение1
....
...
спецификация:
портит:
- эффект: NoExecute
ключ: ключ1
значение: значение1
.... В этом примере размещается заражение с ключом
key1, valuevalue1и эффект taintNoExecuteна узлах.Уменьшите масштаб машины до 0:
$ oc scale --replicas=0 machineset <набор машин> -n openshift-machine-api
В качестве альтернативы вы можете применить следующий YAML для масштабирования набора машин:
версия API: machine.openshift.io/v1beta1 вид: Машинсет метаданные: имя: <набор машин> пространство имен: openshift-machine-api спецификация: реплики: 0
Подождите, пока машины будут удалены.
Масштабируйте набор машин по мере необходимости:
$ oc scale --replicas=2 machineset <набор машин> -n openshift-machine-api
Или:
$ oc изменить набор машин <набор машин> -n openshift-machine-api
Дождитесь запуска машин.
 Заражение добавляется к узлам, связанным с объектом
Заражение добавляется к узлам, связанным с объектом MachineSet.
Привязка пользователя к узлу с помощью taints и допусков
Если вы хотите выделить набор узлов для исключительного использования определенным набором пользователей, добавьте допуск к их модулям. Затем добавьте к этим узлам соответствующую заразу. Подам с допусками разрешено использовать испорченные узлы или любые другие узлы в кластере.
Если вы хотите, чтобы модули были запланированы только для тех испорченных узлов, также добавьте метку к тому же набору узлов и добавьте привязку узла к модулям, чтобы модули можно было планировать только для узлов с этой меткой.
Процедура
Чтобы настроить узел таким образом, чтобы пользователи могли использовать только этот узел:
Добавить соответствующую заразу к этим узлам:
Например:
$ oc adm taint nodes node1 special=groupName:NoSchedule
В качестве альтернативы вы можете применить следующий YAML, чтобы добавить taint:
вид: узел апиВерсия: v1 метаданные: имя: <имя_узла> этикетки: . ..
спецификация:
портит:
- ключ: выделенный
значение: имя_группы
эффект: NoSchedule
..
спецификация:
портит:
- ключ: выделенный
значение: имя_группы
эффект: NoSchedule Добавьте допуск к модулям, написав настраиваемый контроллер допуска.
Управление узлами со специальным оборудованием с использованием исправлений и допусков
В кластере, где небольшое подмножество узлов имеет специализированное оборудование, вы можете использовать исправления и допуски, чтобы не допускать поды, которым не требуется специализированное оборудование, на этих узлах, оставляя узлы для модулей, которым требуется специализированное оборудование. Вам также могут потребоваться модули, которым требуется специализированное оборудование для использования определенных узлов.
Этого можно добиться, добавив допуск к модулям, которым требуется специальное оборудование, и заражая узлы со специализированным оборудованием.
Процедура
Чтобы убедиться, что узлы со специализированным оборудованием зарезервированы для конкретных модулей:
Добавьте допуск к модулям, которым требуется специальное оборудование.

Например:
спецификация: допуски: - ключ: "тип диска" значение: "ссд" оператор: "Равно" эффект: "Без расписания" терпимостьСекунды: 3600Заразите узлы со специализированным оборудованием с помощью одной из следующих команд:
$ oc adm taint nodes
disktype=ssd:NoSchedule Или:
$ oc adm taint nodes
disktype=ssd:PreferNoSchedule В качестве альтернативы вы можете применить следующий YAML, чтобы добавить taint:
вид: узел апиВерсия: v1 метаданные: имя: <имя_узла> этикетки: ... спецификация: портит: - ключ: тип диска значение: твердотельный накопитель эффект: PreferNoSchedule
Удаление дефектов и допусков
При необходимости можно удалить дефекты из узлов и допуски из модулей. Сначала следует добавить допуск к поду, а затем добавить пометку к узлу, чтобы избежать удаления подов с узла до того, как вы сможете добавить допуск.
Сначала следует добавить допуск к поду, а затем добавить пометку к узлу, чтобы избежать удаления подов с узла до того, как вы сможете добавить допуск.
Процедура
Для удаления загрязнений и допусков:
Чтобы удалить заражение с узла:
$ oc adm taint nodes <имя-узла> <ключ>-
Например:
$ oc узлы администратора ip-10-0-132-248.ec2.internal key1-
Пример вывода
node/ip-10-0-132-248.ec2.internal untainted
Чтобы удалить допуск из модуля, отредактируйте спецификацию
Pod, чтобы удалить допуск:спецификация: допуски: - ключ: "key2" оператор: "Существует" эффект: "Не выполнять" допустимые секунды: 3600
Менеджер топологии
Понимание и работа с менеджером топологии.
Политики менеджера топологии
Менеджер топологии согласовывает ресурсы модуля всех классов качества обслуживания (QoS), собирая подсказки топологии от поставщиков подсказок, таких как диспетчер ЦП и диспетчер устройств, и используя собранные подсказки для согласования пода Ресурсы.
Чтобы согласовать ресурсы ЦП с другими запрошенными ресурсами в спецификации |
Topology Manager поддерживает четыре политики распределения, которые вы назначаете в пользовательском ресурсе с поддержкой cpumanager (CR):
-
нетполитика Это политика по умолчанию, не выполняющая никакого выравнивания топологии.
-
максимальные усилияполитика Для каждого контейнера в модуле с политикой управления топологией
с максимальной эффективностьюkubelet вызывает каждого поставщика подсказок, чтобы обнаружить их ресурс.
доступность. Используя эту информацию, менеджер топологии сохраняет предпочтительное соответствие узлов NUMA для этого контейнера. Если сходство не является предпочтительным, Topology Manager сохраняет его и допускает модуль к узлу.
-
ограниченныйполитика Для каждого контейнера в модуле с ограниченной политикой управления топологией
доступность. Используя эту информацию, менеджер топологии сохраняет предпочтительное соответствие узлов NUMA для этого контейнера. Если близость не
предпочтительнее, Topology Manager отклоняет этот модуль от узла, в результате чего модуль находится в состоянииTerminatedс отказом при допуске модуля.-
политика с одним узлом Для каждого контейнера в модуле с политикой управления топологией
с одним узломkubelet вызывает каждого поставщика подсказок, чтобы узнать о доступности их ресурсов. Используя эту информацию, менеджер топологии определяет, возможно ли соответствие одного узла NUMA. Если это так, модуль допускается к узлу. Если привязка одного узла NUMA невозможна, менеджер топологии отклоняет модуль от узла. Это приводит к тому, что модуль находится в состоянии «Завершено» с ошибкой приема модуля.
Это приводит к тому, что модуль находится в состоянии «Завершено» с ошибкой приема модуля.
Настройка диспетчера топологии
Чтобы использовать диспетчер топологии, необходимо настроить политику выделения в пользовательском ресурсе (CR) с поддержкой cpumanager . Этот файл может существовать, если вы настроили диспетчер ЦП. Если файл не существует, вы можете создать файл.
Предварительные условия
Процедура
Для активации менеджера топологии:
Настройте политику выделения Topology Manager в
cpumanager-enabledпользовательский ресурс (CR).$ oc редактировать KubeletConfig cpumanager с поддержкой
версия API: machineconfiguration.openshift.io/v1 вид: KubeletConfig метаданные: имя: с поддержкой cpumanager спецификация: машинаКонфигпулселектор: метки соответствия: custom-kubelet: cpumanager-enabled кубелетКонфигурация: cpuManagerPolicy: статический (1) cpuManagerReconcilePeriod: 5 с topologyManagerPolicy: одиночный узел (2)1 Этот параметр должен быть статическим.
2 Укажите выбранную политику распределения Topology Manager. Здесь политика single-numa-node.
Приемлемые значения:по умолчанию,максимальные усилия,ограниченные,одиночный узел.
Взаимодействие модулей с политиками Topology Manager
Пример 9Приведенные ниже характеристики модуля 1152 помогают проиллюстрировать взаимодействие модуля с Topology Manager.
Следующий модуль работает в классе QoS BestEffort , поскольку нет запросов ресурсов или
лимиты указаны.
спецификация:
контейнеры:
- имя: nginx
image: nginx Следующий модуль работает в классе QoS Burstable , поскольку запросы меньше лимитов.
спецификация:
контейнеры:
- имя: nginx
изображение: nginx
Ресурсы:
пределы:
память: "200Ми"
Запросы:
память: "100Ми" Если выбрана политика, отличная от нет , Менеджер топологии
не учитывайте ни одну из этих спецификаций Pod .
Последний пример модуля ниже выполняется в гарантированном классе QoS, поскольку запросы равны ограничениям.
спецификация:
контейнеры:
- имя: nginx
изображение: nginx
Ресурсы:
пределы:
память: "200Ми"
процессор: "2"
пример.com/устройство: "1"
Запросы:
память: "200Ми"
процессор: "2"
example.com/device: "1" Менеджер топологии рассмотрит этот модуль. Менеджер топологии консультируется с
Статическая политика диспетчера ЦП, которая возвращает топологию доступных ЦП. Топология
Диспетчер также обращается к Диспетчеру устройств, чтобы узнать топологию доступных устройств.
например.com/устройство.
Менеджер топологии будет использовать эту информацию для хранения наилучшей топологии для данного
контейнер. В случае с этим модулем диспетчер ЦП и диспетчер устройств будут использовать это сохраненное
информация на этапе распределения ресурсов.
Запросы ресурсов и избыточное выделение ресурсов
Для каждого вычислительного ресурса контейнер может указать запрос ресурсов и ограничение.
Решения о планировании принимаются на основе запроса, чтобы убедиться, что узел
достаточная емкость для удовлетворения запрошенного значения. Если контейнер указывает
лимиты, но пропускает запросы, запросы по умолчанию устанавливаются в лимитах. А
контейнер не может превысить указанный лимит на узле.
Применение ограничений зависит от типа вычислительного ресурса. Если
контейнер не делает никаких запросов или ограничений, контейнер запланирован к узлу с
никаких ресурсных гарантий. На практике контейнер способен потреблять столько же
указанный ресурс как доступный с самым низким локальным приоритетом. В малом
ситуации с ресурсами, контейнеры, в которых не указаны запросы на ресурсы, получают
самое низкое качество обслуживания.
Планирование основано на запрошенных ресурсах, а квоты и жесткие ограничения относятся
к ограничениям ресурсов, которые могут быть установлены выше запрашиваемых ресурсов.
разница между request и limit определяет уровень overcommit;
например, если контейнеру дается запрос памяти 1Gi и предел памяти
2Gi, он планируется на основе запроса 1Gi, доступного на узле,
но может использовать до 2Gi; так что это на 200% перегружено.
Превышение фиксации на уровне кластера с использованием оператора переопределения ресурсов кластера
Оператор переопределения ресурсов кластера — это веб-перехватчик допуска, который позволяет вам контролировать уровень переполнения и управлять
плотность контейнеров на всех узлах в вашем кластере. Оператор контролирует, как узлы в конкретных проектах могут превышать установленные пределы памяти и ЦП.
Оператор переопределения ресурсов кластера необходимо установить с помощью консоли OpenShift Container Platform или интерфейса командной строки, как показано в следующих разделах.
Во время установки вы создаете ClusterResourceOverride пользовательский ресурс (CR), где вы устанавливаете уровень чрезмерной фиксации, как показано на
следующий пример:
apiVersion: operator.autoscaling.openshift.io/v1
вид: Кластерресаурцеоверриде
метаданные:
название: кластер (1)
спецификация:
подресурсоверрайд:
спецификация:
memoryRequestToLimitPercent: 50 (2)
cpuRequestToLimitPercent: 25 (3)
limitCPUToMemoryPercent: 200 (4) | 1 | Имя должно быть кластер . |
| 2 | Дополнительно. Если лимит памяти контейнера был указан или установлен по умолчанию, запрос памяти переопределяется до этого процента от лимита в диапазоне от 1 до 100. По умолчанию 50. |
| 3 | Дополнительно. Если лимит ЦП контейнера был указан или установлен по умолчанию, запрос ЦП переопределяется на этот процент ограничения в диапазоне от 1 до 100. По умолчанию 25. |
| 4 | Дополнительно. Если предел памяти контейнера был указан или установлен по умолчанию, предел ЦП переопределяется до процента от предела памяти, если он указан. Масштабирование 1Gi оперативной памяти на 100 процентов равно 1 ядру ЦП. Это обрабатывается до переопределения запроса ЦП (если настроено). По умолчанию 200. |
Переопределение оператора кластерного ресурса не действует, если ограничения не |
 Создать
Создать При настройке переопределения могут быть включены для каждого проекта, применяя следующие
метка к объекту пространства имен для каждого проекта:
apiVersion: v1
вид: пространство имен
метаданные:
....
этикетки:
clusterresourceoverrides.admission.autoscaling.openshift.io/enabled: "true"
.... Оператор наблюдает за ClusterResourceOverride CR и гарантирует, что веб-перехватчик допуска ClusterResourceOverride установлен в том же пространстве имен, что и оператор.
Установка оператора переопределения ресурсов кластера с помощью веб-консоли
Вы можете использовать веб-консоль OpenShift Container Platform для установки оператора переопределения ресурсов кластера, чтобы контролировать перегрузку в вашем кластере.
Предварительные условия
Процедура
Чтобы установить Cluster Resource Override Operator с помощью веб-консоли OpenShift Container Platform:
В веб-консоли OpenShift Container Platform перейдите к Home → Projects
Нажмите Создать проект .
Укажите
clusterresourceoverride-operatorв качестве имени проекта.Нажмите Создать .
Перейдите к Operators → OperatorHub .
Выберите ClusterResourceOverride Operator из списка доступных операторов и нажмите Install .
На странице Install Operator убедитесь, что Определенное пространство имен в кластере выбрано для Режим установки .

Убедитесь, что clusterresourceoverride-operator выбран для Installed Namespace .
Выберите канал обновления и Стратегия одобрения .
Щелкните Установить .
На странице Установленные операторы щелкните ClusterResourceOverride .
На странице сведений ClusterResourceOverride Operator щелкните Create Instance .
На странице Create ClusterResourceOverride отредактируйте шаблон YAML, чтобы задать требуемые значения сверхфиксации:
версия API: operator.autoscaling.openshift.io/v1 вид: Кластерресаурцеоверриде метаданные: название: кластер (1) спецификация: подресурсоверрайд: спецификация: memoryRequestToLimitPercent: 50 (2) cpuRequestToLimitPercent: 25 (3) limitCPUToMemoryPercent: 200 (4)1 Имя должно быть кластер.
2 Дополнительно. Укажите процент переопределения ограничения памяти контейнера, если он используется, в диапазоне от 1 до 100. По умолчанию 50. 3 Дополнительно. Укажите процент переопределения ограничения ЦП контейнера, если он используется, в диапазоне от 1 до 100. По умолчанию 25. 4 Дополнительно. Укажите процент переопределения ограничения памяти контейнера, если оно используется. Масштабирование 1Gi оперативной памяти на 100 процентов равно 1 ядру ЦП. Это обрабатывается перед переопределением запроса ЦП, если он настроен. По умолчанию 200. Нажмите Создать .
Проверьте текущее состояние веб-перехватчика допуска, проверив состояние пользовательского ресурса кластера:
На странице ClusterResourceOverride Operator щелкните кластер .

В возрасте ClusterResourceOverride Details щелкните YAML . Раздел
mutatingWebhookConfigurationRefпоявляется при вызове веб-перехватчика.версия API: operator.autoscaling.openshift.io/v1 вид: Кластерресаурцеоверриде метаданные: аннотации: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.autoscaling.openshift.io/v1","вид":"ClusterResourceOverride","метаданные":{"аннотации":{},"имя":"кластер"},"спецификация": {"podResourceOverride":{"spec":{"cpuRequestToLimitPercent":25,"limitCPUToMemoryPercent":200,"memoryRequestToLimitPercent":50}}}} Отметка времени создания: "2019-12-18T22:35:02Z" поколение: 1 имя: кластер версия ресурса: "127622" selfLink: /apis/operator.autoscaling.openshift.io/v1/clusterresourceoverrides/cluster ИД: 978fc959-1717-4bd1-97d0-ae00ee111e8d спецификация: подресурсоверрайд: спецификация: cpuRequestToLimitPercent: 25 лимит CPUToMemoryPercent: 200 memoryRequestToLimitPercent: 50 статус: . ...
mutatingWebhookConfigurationRef: (1)
apiVersion: допускregistration.k8s.io/v1beta1
вид: MutationWebhookConfiguration
имя: clusterresourceoverrides.admission.autoscaling.openshift.io
версия ресурса: "127621"
UID: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3
....
...
mutatingWebhookConfigurationRef: (1)
apiVersion: допускregistration.k8s.io/v1beta1
вид: MutationWebhookConfiguration
имя: clusterresourceoverrides.admission.autoscaling.openshift.io
версия ресурса: "127621"
UID: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3
.... 1 Ссылка на веб-перехватчик допуска ClusterResourceOverride.
Установка оператора переопределения ресурсов кластера с помощью интерфейса командной строки
Вы можете использовать интерфейс командной строки OpenShift Container Platform для установки оператора переопределения ресурсов кластера, который помогает контролировать перегрузку в вашем кластере.
Предварительные условия
Процедура
Чтобы установить оператор переопределения ресурсов кластера с помощью интерфейса командной строки:
Создайте пространство имен для оператора переопределения ресурсов кластера:
Создайте YAML-файл объекта пространства имен (например,
cro-namespace.) для оператора переопределения ресурсов кластера: yaml
yaml APIВерсия: v1 вид: пространство имен метаданные: имя: оператор-кластерресурсоверрайд
Создать пространство имен:
$ oc create -f <имя-файла>.yaml
Например:
$ oc создать -f cro-namespace.yaml
Создать группу операторов:
Создайте YAML-файл объекта
OperatorGroup(например, cro-og.yaml) для оператора переопределения ресурсов кластера:версия API: operator.coreos.com/v1 вид: группа операторов метаданные: имя: оператор-кластерресурсоверрайд пространство имен: оператор-кластерресурсоверрайд спецификация: целевые пространства имен: - оператор переопределения кластерных ресурсовСоздать группу операторов:
$ oc create -f <имя-файла>.
 yaml
yaml Например:
$ oc create -f cro-og.yaml
Создать подписку:
Создайте файл YAML объекта
Subscription(например, cro-sub.yaml) для оператора переопределения ресурсов кластера:версия API: operator.coreos.com/v1alpha1 вид: подписка метаданные: имя: кластерресурсоверрайд пространство имен: оператор-кластерресурсоверрайд спецификация: канал: "4.10" имя: кластерресурсоверрайд источник: redhat-operators sourceNamespace: openshift-marketplace
Создать подписку:
$ oc create -f <имя-файла>.yaml
Например:
$ oc create -f cro-sub.yaml
Создайте объект пользовательского ресурса (CR)
ClusterResourceOverrideв пространстве именclusterresourceoverride-operator:Изменение на пространство имен
clusterresourceoverride-operator.
$ oc оператор кластерного ресурса переопределения проекта
Создайте файл YAML объекта
ClusterResourceOverride(например, cro-cr.yaml) для оператора переопределения ресурсов кластера:версия API: operator.autoscaling.openshift.io/v1 вид: Кластерресаурцеоверриде метаданные: название: кластер (1) спецификация: подресурсоверрайд: спецификация: memoryRequestToLimitPercent: 50 (2) cpuRequestToLimitPercent: 25 (3) лимит CPUToMemoryPercent: 200 (4)1 Имя должно быть кластер.2 Дополнительно. Укажите процент переопределения ограничения памяти контейнера, если он используется, в диапазоне от 1 до 100. По умолчанию 50. 
3 Дополнительно. Укажите процент переопределения ограничения ЦП контейнера, если он используется, в диапазоне от 1 до 100. По умолчанию 25. 4 Дополнительно. Укажите процент переопределения ограничения памяти контейнера, если оно используется. Масштабирование 1Gi оперативной памяти на 100 процентов равно 1 ядру ЦП. Это обрабатывается перед переопределением запроса ЦП, если он настроен. По умолчанию 200. Создайте объект
ClusterResourceOverride:$ oc create -f <имя-файла>.yaml
Например:
$ oc create -f cro-cr.yaml
Проверьте текущее состояние веб-перехватчика допуска, проверив состояние пользовательского ресурса кластера.
$ oc get clusterresourceoverride cluster -n clusterresourceoverride-operator -o yaml
Раздел
mutatingWebhookConfigurationRefпоявляется при вызове веб-перехватчика.
Пример вывода
apiVersion: operator.autoscaling.openshift.io/v1 вид: Кластерресаурцеоверриде метаданные: аннотации: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.autoscaling.openshift.io/v1","вид":"ClusterResourceOverride","метаданные":{"аннотации":{},"имя":"кластер"},"спецификация": {"podResourceOverride":{"spec":{"cpuRequestToLimitPercent":25,"limitCPUToMemoryPercent":200,"memoryRequestToLimitPercent":50}}}} Отметка времени создания: "2019-12-18Т22:35:02З" поколение: 1 имя: кластер версия ресурса: "127622" selfLink: /apis/operator.autoscaling.openshift.io/v1/clusterresourceoverrides/cluster UID: 978fc959-1717-4bd1-97d0-ae00ee111e8d спецификация: подресурсоверрайд: спецификация: cpuRequestToLimitPercent: 25 лимит CPUToMemoryPercent: 200 memoryRequestToLimitPercent: 50 статус: .... mutatingWebhookConfigurationRef: (1) apiVersion: допускregistration. k8s.io/v1beta1
вид: MutationWebhookConfiguration
имя: clusterresourceoverrides.admission.autoscaling.openshift.io
версия ресурса: "127621"
ИД: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3
....
k8s.io/v1beta1
вид: MutationWebhookConfiguration
имя: clusterresourceoverrides.admission.autoscaling.openshift.io
версия ресурса: "127621"
ИД: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3
.... 1 Ссылка на веб-перехватчик допуска ClusterResourceOverride.
Настройка избыточной фиксации на уровне кластера
Оператору переопределения ресурсов кластера требуется ClusterResourceOverride настраиваемый ресурс (CR)
и метка для каждого проекта, где вы хотите, чтобы Оператор контролировал чрезмерную фиксацию.
Предпосылки
Процедура
Чтобы изменить избыточную фиксацию на уровне кластера:
Изменить
ClusterResourceOverrideCR:версия API: operator.autoscaling.openshift.io/v1 вид: Кластерресаурцеоверриде метаданные: имя: кластер спецификация: подресурсоверрайд: спецификация: memoryRequestToLimitPercent: 50 (1) cpuRequestToLimitPercent: 25 (2) лимит CPUToMemoryPercent: 200 (3)1 Дополнительно.  Укажите процент переопределения ограничения памяти контейнера, если он используется, в диапазоне от 1 до 100. По умолчанию 50.
Укажите процент переопределения ограничения памяти контейнера, если он используется, в диапазоне от 1 до 100. По умолчанию 50.2 Дополнительно. Укажите процент переопределения ограничения ЦП контейнера, если он используется, в диапазоне от 1 до 100. По умолчанию 25. 3 Дополнительно. Укажите процент переопределения ограничения памяти контейнера, если оно используется. Масштабирование 1Gi оперативной памяти на 100 процентов равно 1 ядру ЦП. Это обрабатывается перед переопределением запроса ЦП, если он настроен. По умолчанию 200. Убедитесь, что следующая метка добавлена к объекту пространства имен для каждого проекта, в котором вы хотите, чтобы оператор переопределения ресурсов кластера управлял избыточной фиксацией:
APIВерсия: v1 вид: пространство имен метаданные: ... этикетки: clusterresourceoverrides. admission.autoscaling.openshift.io/enabled: "true" (1)
...
admission.autoscaling.openshift.io/enabled: "true" (1)
... 1 Добавьте эту метку к каждому проекту.
Излишняя фиксация на уровне узла
Можно использовать различные способы контроля избыточной фиксации на определенных узлах, например качество обслуживания (QOS).
гарантии, лимиты ЦП или резервные ресурсы. Вы также можете отключить overcommit для определенных узлов.
и конкретные проекты.
Общие сведения о вычислительных ресурсах и контейнерах
Принудительное поведение узла для вычислительных ресурсов зависит от ресурса
тип.
Понимание запросов ЦП контейнера
Контейнеру гарантируется объем запрашиваемого ЦП, и он дополнительно может
использовать избыточный ЦП, доступный на узле, до любого предела, указанного
контейнер. Если несколько контейнеров пытаются использовать избыточный ЦП, время ЦП
распределяется в зависимости от количества ЦП, запрошенного каждым контейнером.
Например, если один контейнер запросил 500 м процессорного времени, а другой контейнер
запрошено 250 м процессорного времени, то любое дополнительное процессорное время, доступное на узле,
распределяется по контейнерам в соотношении 2:1. Если в контейнере указано
limit, он будет регулироваться, чтобы не использовать больше ЦП, чем указанный лимит.
Запросы ЦП выполняются с помощью поддержки общих ресурсов CFS в ядре Linux. По
по умолчанию ограничения ЦП применяются с помощью поддержки квот CFS в ядре Linux.
с интервалом измерения 100 мс, хотя это можно отключить.
Понимание запросов памяти контейнера
Контейнеру гарантирован объем памяти, который он запрашивает. Контейнер может использовать
больше памяти, чем запрошено, но как только он превысит запрошенный объем, он может
быть завершена в случае нехватки памяти на узле.
Если контейнер использует меньше памяти, чем запрошено, он не будет остановлен, если
системным задачам или демонам требуется больше памяти, чем было учтено в памяти узла.
резервирование ресурсов. Если в контейнере указано ограничение на память,
немедленно прекращается, если она превышает лимитную сумму.
Понимание избыточной нагрузки и классов качества обслуживания
Узел перегружен , когда у него есть запланированный модуль, который не делает запросов, или
когда сумма ограничений по всем модулям на этом узле превышает доступную машину
вместимость.
В среде с чрезмерным выделением ресурсов модули на узле могут
попытаться использовать больше вычислительных ресурсов, чем доступно в любой данный момент в
время. Когда это происходит, узел должен отдавать приоритет одному поду над другим.
средство, используемое для принятия этого решения, называется качеством обслуживания (QoS).
Учебный класс.
Для каждого вычислительного ресурса контейнер делится на один из трех классов QoS.
в порядке убывания приоритета:
| Приоритет | Имя класса | Описание |
|---|---|---|
1 (самый высокий) | Гарантия | Если для всех ресурсов установлены лимиты и опционально запросы (не равные 0) |
2 | Разрывной | Если заданы запросы и опционально лимиты (не равные 0) для всех ресурсов, |
3 (самый низкий) | BestEffort | Если запросы и лимиты не установлены ни для одного из ресурсов, то контейнер |

Память является несжимаемым ресурсом, поэтому при нехватке памяти контейнеры
с наименьшим приоритетом завершаются первыми:
Гарантированные контейнеры считаются высшим приоритетом и гарантированно
быть прекращено только в том случае, если они превышают свои пределы или если в системе недостаточно памяти
давления и нет контейнеров с более низким приоритетом, которые можно выселить.Разрывной 9Контейнеры 0578 при нехватке системной памяти, скорее всего, будут
прекращается, как только они превышают свои запросы, и никакие другие контейнеры BestEffort
существует.
Контейнеры BestEffort обрабатываются с самым низким приоритетом. процессы в
эти контейнеры первыми завершаются, если в системе заканчивается память.
Понимание того, как резервировать память между уровнями качества обслуживания
Вы можете использовать qos-reserved 9Параметр 1153 для указания процента памяти, который необходимо зарезервировать.
модулем на определенном уровне QoS. Эта функция пытается зарезервировать запрошенные ресурсы, чтобы исключить модули.
от более низких классов OoS от использования ресурсов, запрошенных подами в более высоких классах QoS.
OpenShift Container Platform использует параметр qos-reserved следующим образом:
Значение
qos-reserved=memory=100%предотвратит потребление памяти классамиBurstableиBestEffortQOS.
который был запрошен более высоким классом QoS. Это увеличивает риск вызвать OOM
нарабочих нагрузки BestEffortиBurstableв пользу увеличения гарантий ресурсов памяти
дляГарантированныеиВзрывоустойчивые рабочие нагрузки.
Значение
qos-reserved=memory=50%разрешает классыBurstableиBestEffortQOS.
потреблять половину памяти, запрошенной более высоким классом QoS.Значение
qos-reserved=memory=0%
позволитBurstableиКлассы QoS BestEffortдля использования до полного узла
выделяемая сумма, если она доступна, но увеличивает риск того, что рабочая нагрузкаGuaranteed
не будет иметь доступа к запрошенной памяти. Это условие эффективно отключает эту функцию.
Общие сведения о памяти подкачки и QOS
Вы можете отключить подкачку по умолчанию на своих узлах, чтобы сохранить качество
сервис (QOS) гарантирует. В противном случае физические ресурсы на узле могут быть превышены.
влияет на ресурсные гарантии, которые планировщик Kubernetes делает во время пода.
размещение.
Например, если два гарантированных модуля достигли своего предела памяти, каждый
контейнер может начать использовать память подкачки. В конце концов, если не хватает свопа
В конце концов, если не хватает свопа
пространство, процессы в модулях могут быть остановлены из-за того, что система
превышена подписка.
Если не отключить подкачку, узлы не распознают, что они
возникает MemoryPressure , в результате чего модули не получают память, которую они
сделанный в их запросе планирования. В результате дополнительные стручки размещаются на
node для дальнейшего увеличения нагрузки на память, что в конечном итоге увеличивает риск
происходит событие системной нехватки памяти (OOM).
Если подкачка включена, любые пороговые значения вытеснения при обработке нехватки ресурсов для доступной памяти не будут работать, поскольку |
Общие сведения о чрезмерном выделении узлов
В среде с избыточным выделением важно правильно настроить узел, чтобы обеспечить наилучшее поведение системы.
Когда узел запускается, он гарантирует, что настраиваемые флаги ядра для памяти
управление настроено правильно. Ядро никогда не должно прерывать выделение памяти
если не закончится физическая память.
Чтобы обеспечить такое поведение, OpenShift Container Platform настраивает ядро на постоянную избыточную фиксацию
память, установив для параметра vm.overcommit_memory значение 1 , переопределив
настройка операционной системы по умолчанию.
OpenShift Container Platform также настраивает ядро таким образом, чтобы оно не паниковало при нехватке памяти.
установив параметр vm.panic_on_oom на 0 . Значение 0 указывает
ядро для вызова oom_killer в состоянии нехватки памяти (OOM), которое убивает
процессы на основе приоритета
Вы можете просмотреть текущие настройки, выполнив следующие команды на своих узлах:
$ sysctl -a |grep commit
Пример вывода
vm.overcommit_memory = 1
$ sysctl -a |grep panic
Пример вывода
vm.panic_on_oom = 0
Вышеупомянутые флаги уже должны быть установлены на узлах, и никаких дальнейших действий не требуется. |
Вы также можете выполнить следующие настройки для каждого узла:
Отключение или принудительное ограничение ЦП с помощью квот ЦП CFS
Резерв ресурсов для системных процессов
Резервная память для уровней качества обслуживания
Отключение или применение ограничений ЦП с помощью квот ЦП CFS
Узлы по умолчанию применяют указанные ограничения ЦП, используя поддержку квот Completely Fair Scheduler (CFS) в ядре Linux.
Если вы отключите принудительное ограничение ЦП, важно понимать влияние на ваш узел:
Если у контейнера есть запрос ЦП, запрос продолжает выполняться общими ресурсами CFS в ядре Linux.

Если у контейнера нет запроса ЦП, но есть ограничение ЦП, запрос ЦП по умолчанию соответствует указанному ограничению ЦП и применяется общими ресурсами CFS в ядре Linux.
Если у контейнера есть как запрос ЦП, так и ограничение, запрос ЦП обеспечивается общими ресурсами CFS в ядре Linux, и ограничение ЦП не влияет на узел.
Предпосылки
Получите метку, связанную со статическим CRD
MachineConfigPoolдля типа узла, который вы хотите настроить. Выполните один из следующих шагов:Просмотр пула конфигурации машин:
$ oc описать machineconfigpool <имя>
Например:
$ oc описать работника machineconfigpool
Пример вывода
apiVersion: machineconfiguration.openshift.io/v1 вид: Машинконфигпул метаданные: СозданиеTimestamp: 2019-02-08T14:52:39Z поколение: 1 этикетки: custom-kubelet: маленькие стручки (1)1 Если метка была добавлена, она отображается под метками.
Если метка отсутствует, добавьте пару ключ/значение:
$ oc label machineconfigpool worker custom-kubelet=small-pods
В качестве альтернативы вы можете применить следующий YAML для добавления метки:
версия API: machineconfiguration.openshift.io/v1 вид: Машинконфигпул метаданные: этикетки: custom-kubelet: маленькие стручки имя: работник
Процедура
Создайте пользовательский ресурс (CR) для изменения конфигурации.
Пример конфигурации для отключения ограничений ЦП
apiVersion: machineconfiguration.openshift.io/v1 вид: KubeletConfig метаданные: имя: отключить-процессор-единицы (1) спецификация: машинаКонфигпулселектор: метки соответствия: custom-kubelet: маленькие капсулы (2) кубелетКонфигурация: квота процессора: (3) - "ложь"1 Присвойте имя CR. 
2 Укажите метку для применения изменения конфигурации. 3 Задайте для параметра cpuCfsQuotaзначениеfalse.
Резервирование ресурсов для системных процессов
Чтобы обеспечить более надежное планирование и свести к минимуму чрезмерное использование ресурсов узла,
каждый узел может зарезервировать часть своих ресурсов для использования системными демонами
которые необходимы для работы на вашем узле, чтобы ваш кластер функционировал.
В частности, рекомендуется резервировать ресурсы для несжимаемых ресурсов, таких как память.
Процедура
Чтобы явно зарезервировать ресурсы для процессов, не являющихся модулями, выделите ресурсы узла, указав ресурсы
доступны для планирования.
Дополнительные сведения см. в разделе Распределение ресурсов для узлов.
Отключение избыточной фиксации для узла
Если эта функция включена, избыточная фиксация может быть отключена на каждом узле.
Процедура
Чтобы отключить чрезмерное выделение на узле, выполните на этом узле следующую команду:
$ sysctl -w vm.overcommit_memory=0
Ограничения на уровне проекта
Чтобы помочь контролировать чрезмерную фиксацию, вы можете установить диапазоны лимитов ресурсов для каждого проекта,
указание ограничений памяти и ЦП и значений по умолчанию для проекта, который перегружает
не может превышать.
Сведения об ограничениях ресурсов на уровне проекта см. в разделе Дополнительные ресурсы.
Кроме того, вы можете отключить чрезмерное выделение для определенных проектов.
Отключение избыточного выделения для проекта
Если этот параметр включен, избыточное выделение может быть отключено для каждого проекта.
Например, вы можете позволить настраивать компоненты инфраструктуры независимо от чрезмерной фиксации.
Процедура
Чтобы отключить чрезмерное выделение в проекте:
Редактировать объектный файл проекта
Добавьте следующую аннотацию:
quota.
 openshift.io/cluster-resource-override-enabled: «ложь»
openshift.io/cluster-resource-override-enabled: «ложь» Создать объект проекта:
$ oc create -f <имя-файла>.yaml
Освобождение ресурсов узла с помощью сборки мусора
Понимание и использование сборки мусора.
Понимание того, как завершенные контейнеры удаляются с помощью сборки мусора
Сборка мусора контейнеров может выполняться с использованием порогов вытеснения.
Когда для сборки мусора установлены пороги вытеснения, узел пытается сохранить доступ к любому контейнеру для любого модуля из API. Если модуль был удален, контейнеры также будут удалены. Контейнеры сохраняются до тех пор, пока модуль не будет удален и не будет достигнут порог вытеснения. Если узел находится под давлением диска, он удалит контейнеры, и их журналы больше не будут доступны с использованием oc логов .
eviction-soft — Порог мягкого вытеснения сочетает порог вытеснения с требуемым льготным периодом, указанным администратором.

eviction-hard — Порог жесткого вытеснения не имеет льготного периода, и при его соблюдении OpenShift Container Platform предпринимает немедленные действия.
В следующей таблице перечислены пороги вытеснения:
| Состояние узла | Сигнал о выселении | Описание |
|---|---|---|
Давление памяти | | Доступная память на узле. |
Давление диска |
| Доступное дисковое пространство или индексные дескрипторы в корневой файловой системе узла, |

Для evictionHard |
Если узел колеблется выше и ниже порога мягкого вытеснения, но не превышает связанного с ним льготного периода, соответствующий узел будет постоянно колебаться между true и false . Как следствие, планировщик может принимать неверные решения по планированию.
Для защиты от этого колебания используйте флаг eviction-pressure-transition-period , чтобы контролировать, как долго OpenShift Container Platform должна ждать перед переходом из состояния давления. OpenShift Container Platform не будет устанавливать порог вытеснения как удовлетворяющий указанному условию давления на период, указанный до переключения условия обратно на false.
Понимание того, как изображения удаляются с помощью сборки мусора
Сборка мусора изображений зависит от использования диска, как сообщает cAdvisor
узел, чтобы решить, какие изображения удалить из узла.
Политика сбора мусора для изображений основана на двух условиях:
Процент использования диска (выраженный как целое число), который запускает образ
вывоз мусора. По умолчанию 85 .Процент использования диска (выраженный как целое число), которому
коллекция попыток бесплатно. По умолчанию 80 .
Для сборки мусора изображений вы можете изменить любую из следующих переменных, используя
пользовательский ресурс.
| Настройка | Описание |
|---|---|
| Минимальный срок хранения неиспользуемого образа до его удаления при сборке мусора. |
| Процент использования диска, выраженный целым числом, при котором запускается образ |
| Процент использования диска, выраженный целым числом, на |
 По умолчанию 2м .
По умолчанию 2м .Два списка изображений извлекаются при каждом запуске сборщика мусора:
Список изображений, запущенных в настоящее время по крайней мере в одном модуле.
Список изображений, доступных на хосте.
При запуске новых контейнеров появляются новые образы. Все изображения отмечены временем
печать. Если образ запущен (первый список выше) или обнаружен недавно (первый список
второй список выше), он отмечен текущим временем. Остальные изображения
Остальные изображения
уже отмечены с предыдущих спинов. Затем все изображения сортируются по времени
печать.
После запуска коллекции сначала удаляются самые старые изображения, пока не
Критерий остановки соблюден.
Настройка сборки мусора для контейнеров и образов
Как администратор вы можете настроить, как OpenShift Container Platform выполняет сборку мусора, создав объект kubeletConfig для каждого пула конфигурации машин.
OpenShift Container Platform поддерживает только один |
Можно настроить любое сочетание следующих параметров:
Предварительные условия
Получите метку, связанную со статическим CRD
MachineConfigPoolдля типа узла, который вы хотите настроить.
Выполните один из следующих шагов:Просмотр пула конфигурации машин:
$ oc описать machineconfigpool <имя>
Например:
$ oc описать работника machineconfigpool
Пример вывода
Имя: рабочий Пространство имен: Ярлыки: custom-kubelet=small-pods (1)
1 Если метка была добавлена, она отображается в разделе Ярлыки.
Если метка отсутствует, добавьте пару ключ/значение:
$ oc label machineconfigpool worker custom-kubelet=small-pods
В качестве альтернативы вы можете применить следующий YAML для добавления метки:
версия API: machineconfiguration.openshift.io/v1 вид: Машинконфигпул метаданные: этикетки: custom-kubelet: маленькие стручки имя: работник
Процедура
Создайте пользовательский ресурс (CR) для изменения конфигурации.
Если файловая система одна или
/var/lib/kubeletи/var/lib/containers/находятся в одной и той же файловой системе, настройки с наибольшими значениями вызывают выселение, так как они встречаются первыми. Файловая система инициирует вытеснение.
Пример конфигурации для сборки мусора контейнера CR:
apiVersion: machineconfiguration.openshift.io/v1 вид: KubeletConfig метаданные: имя: рабочий-кубеконфиг (1) спецификация: машинаКонфигпулселектор: метки соответствия: custom-kubelet: маленькие стручки (2) кубелетКонфигурация: evictionSoft: (3) доступная память: "500Ми" (4) nodefs.доступно: "10%" nodefs.inodesFree: "5%" imagefs.доступно: "15%" imagefs.inodesFree: "10%" evictionSoftGracePeriod: (5) память.доступно: "1м30с" nodefs.доступно: "1м30с" nodefs.inodesFree: "1м30с" imagefs.доступно: "1м30с" imagefs.inodesFree: "1м30с" выселениеHard: (6) память.доступно: "200Ми" nodefs.доступно: "5%" nodefs.inodesFree: "4%" imagefs. доступно: "10%"
imagefs.inodesFree: "5%"
evictionPressureTransitionPeriod: 0 с (7)
imageМинимальныйGCAВозраст: 5 мес. (8)
imageGCHighThresholdPercent: 80 (9)
imageGCLowThresholdPercent: 75 (10)
доступно: "10%"
imagefs.inodesFree: "5%"
evictionPressureTransitionPeriod: 0 с (7)
imageМинимальныйGCAВозраст: 5 мес. (8)
imageGCHighThresholdPercent: 80 (9)
imageGCLowThresholdPercent: 75 (10) 1 Имя объекта. 2 Метка выбора. 3 Тип выселения: evictionSoftилиevictionHard.4 Пороги вытеснения на основе определенного триггерного сигнала вытеснения. 5 Льготный период для мягкого выселения. Этот параметр не относится к eviction-hard.6 Пороги вытеснения на основе определенного триггерного сигнала вытеснения. 
Для evictionHard7 Продолжительность ожидания перед переходом из условия принудительного выселения. 8 Минимальный срок хранения неиспользуемого образа до его удаления при сборке мусора. 9 Процент использования диска (выраженный как целое число), который запускает сборку мусора изображений. 10 Процент использования диска (выраженный как целое число), который пытается освободить сборщик мусора образов. Создать объект:
$ oc create -f <имя-файла>.yaml
Например:
$ oc create -f gc-container.
 yaml
yaml Пример вывода
kubeletconfig.machineconfiguration.openshift.io/gc-container создан
Убедитесь, что сборка мусора активна. Пул конфигурации машин, указанный вами в пользовательском ресурсе, отображается с
UPDATINGкак «true», пока изменение не будет полностью реализовано:$ oc получить machineconfigpool
Пример вывода
НАЗВАНИЕ КОНФИГУРАЦИЯ ОБНОВЛЕНО ОБНОВЛЕНИЕ master rendered-master-546383f80705bd5aeaba93 True False рабочий визуализированный рабочий-b4c51bb33ccaae6fc4a6a5 False True
Использование оператора настройки узла
Понимание и использование оператора настройки узла.
Оператор настройки узла помогает управлять настройкой на уровне узла, управляя демоном TuneD. Большинство высокопроизводительных приложений требуют определенного уровня настройки ядра. Node Tuning Operator предоставляет унифицированный интерфейс управления для пользователей sysctl на уровне узла и большую гибкость для добавления пользовательской настройки в соответствии с потребностями пользователя.
Оператор управляет контейнерным демоном TuneD для OpenShift Container Platform как набором демонов Kubernetes. Это гарантирует, что спецификация пользовательской настройки будет передана всем контейнерным демонам TuneD, работающим в кластере, в формате, понятном этим демонам. Демоны работают на всех узлах кластера, по одному на каждый узел.
Настройки на уровне узла, примененные демоном TuneD в контейнере, откатываются при событии, которое запускает изменение профиля, или когда демон TuneD в контейнере корректно завершается путем получения и обработки сигнала завершения.
Оператор настройки узлов является частью стандартной установки OpenShift Container Platform версии 4.1 и более поздних.
Доступ к примеру спецификации оператора настройки узла
Используйте этот процесс для доступа к примеру спецификации оператора настройки узла.
Процедура
Прогон:
$ oc get Tuned/default -o yaml -n openshift-cluster-node-tuning-operator
CR по умолчанию предназначен для предоставления стандартной настройки на уровне узла для платформы OpenShift Container Platform, и его можно изменить только для установки состояния управления оператором. Любые другие пользовательские изменения CR по умолчанию будут перезаписаны Оператором. Для индивидуальной настройки создайте собственные настроенные CR. Вновь созданные CR будут объединены с CR по умолчанию и пользовательской настройкой, применяемой к узлам OpenShift Container Platform на основе меток узлов или модулей и приоритетов профиля.
Любые другие пользовательские изменения CR по умолчанию будут перезаписаны Оператором. Для индивидуальной настройки создайте собственные настроенные CR. Вновь созданные CR будут объединены с CR по умолчанию и пользовательской настройкой, применяемой к узлам OpenShift Container Platform на основе меток узлов или модулей и приоритетов профиля.
Хотя в определенных ситуациях поддержка меток модулей может быть удобным способом автоматической доставки необходимой настройки, такая практика не рекомендуется и настоятельно рекомендуется, особенно в крупномасштабных кластерах. Tuned CR по умолчанию поставляется без сопоставления меток модулей. Если настраиваемый профиль создан с сопоставлением меток модулей, тогда эта функция будет включена в это время. Функциональность метки модуля может быть объявлена устаревшей в будущих версиях оператора настройки узлов. |
Спецификация пользовательской настройки
Пользовательский ресурс (CR) для оператора состоит из двух основных разделов. Первый раздел,
Первый раздел, profile:, представляет собой список профилей TuneD и их названия. Второй, рекомендует: , определяет логику выбора профиля.
Несколько пользовательских спецификаций настройки могут сосуществовать как несколько CR в пространстве имен оператора. Наличие новых CR или удаление старых CR выявляется Оператором. Все существующие спецификации пользовательской настройки объединяются, а соответствующие объекты для контейнерных демонов TuneD обновляются.
Состояние управления
Состояние управления оператором задается путем настройки настроенного CR по умолчанию. По умолчанию оператор находится в состоянии Managed, а поле spec.managementState отсутствует в настроенном CR по умолчанию. Допустимые значения для состояния управления оператором:
Управляемый: Оператор будет обновлять свои операнды по мере обновления ресурсов конфигурации
Неуправляемый: Оператор игнорирует изменения ресурсов конфигурации
Удалено: Оператор удалит свои операнды и ресурсы, предоставленные Оператором
Данные профиля
В разделе профиля : перечислены профили TuneD и их имена.
профиль:
- имя: настроенный_профиль_1
данные: |
# Спецификация профиля TuneD
[главный]
summary=Описание профиля tuning_profile_1
[sysctl]
сеть.ipv4.ip_forward=1
# ... другие sysctl или другие подключаемые модули демона TuneD, поддерживаемые контейнерным TuneD
# ...
- имя: tuning_profile_n
данные: |
# Спецификация профиля TuneD
[главный]
summary=Описание профиля tuning_profile_n
# настройки профиля tuning_profile_n Рекомендуемые профили
Логика выбора профиля : определяется разделом рекомендовать: CR. Раздел рекомендует: представляет собой список элементов, рекомендуемых для профилей на основе критериев выбора.
рекомендуем: <рекомендуемый элемент-1> # ...
Отдельные элементы списка:
- machineConfigLabels: (1)
(2) г.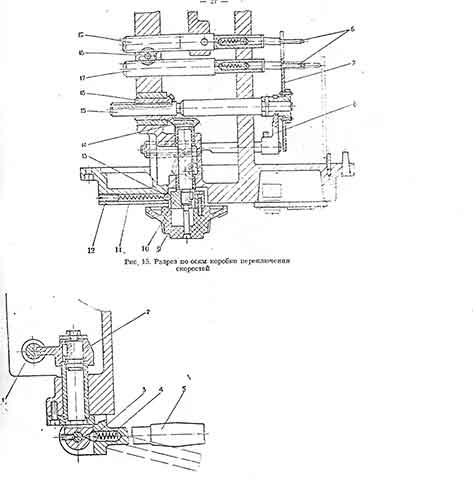 совпадение: (3)
<совпадение> (4)
приоритет: <приоритет> (5)
профиль: <настроенное_имя_профиля> (6)
операнд: (7)
отладка:
совпадение: (3)
<совпадение> (4)
приоритет: <приоритет> (5)
профиль: <настроенное_имя_профиля> (6)
операнд: (7)
отладка: (8) | 1 | Дополнительно. |
| 2 | Словарь меток ключ/значение MachineConfig . Ключи должны быть уникальными. |
| 3 | Если этот параметр опущен, предполагается совпадение профиля, за исключением случаев, когда профиль с более высоким приоритетом соответствует первому или если не задан параметр machineConfigLabels . |
| 4 | Необязательный список. |
| 5 | Приоритет заказа профилей. Меньшие числа означают более высокий приоритет ( Меньшие числа означают более высокий приоритет ( 0 — наивысший приоритет). |
| 6 | Профиль TuneD для применения к матчу. Например tuning_profile_1 . |
| 7 | Необязательная конфигурация операнда. |
| 8 | Включить или отключить отладку для демона TuneD. Возможные варианты: true для включения или false для выключения. По умолчанию false . |
— необязательный список, рекурсивно определяемый следующим образом:
- метка: <имя_метки> (1) значение:(2) тип: (3) (4)
| 1 | Имя метки узла или модуля. |
| 2 | Необязательное значение метки узла или модуля. Если опущено, для совпадения достаточно наличия . |
| 3 | Необязательный тип объекта ( узел или модуль ). Если опущено, предполагается узел . |
| 4 | Необязательный список . |
Если не опущено, все вложенные разделы также должны оцениваться как true . В противном случае предполагается false и профиль с соответствующими Раздел не будет применяться или рекомендоваться. Следовательно, вложенность (дочерние секции) работает как логический оператор И. И наоборот, если какой-либо элемент списка совпадает, весь список оценивается как true . Таким образом, список действует как логический оператор ИЛИ.
Таким образом, список действует как логический оператор ИЛИ.
Если определено machineConfigLabels , сопоставление на основе пула конфигураций машин включается для данного рекомендует: элемента списка. указывает метки для конфигурации компьютера. Конфигурация машины создается автоматически для применения настроек хоста, таких как параметры загрузки ядра, для профиля <настроенное_имя_профиля> . Это включает в себя поиск всех пулов конфигурации машин с селектором конфигурации машин, соответствующим , и установку профиля на всех узлах, которым назначены найденные пулы конфигурации машин. Для целевых узлов, имеющих как главную, так и рабочую роли, вы должны использовать главную роль.
Элементы списка соответствуют , а machineConfigLabels связаны логическим оператором ИЛИ. Элемент , соответствующий элементу , сначала оценивается методом короткого замыкания. Поэтому, если он оценивается как
Поэтому, если он оценивается как true , элемент machineConfigLabels не рассматривается.
При использовании сопоставления на основе пула конфигурации машин рекомендуется сгруппировать узлы с одинаковой конфигурацией оборудования в один и тот же пул конфигурации машин. Несоблюдение этой практики может привести к тому, что операнды TuneD будут вычислять конфликтующие параметры ядра для двух или более узлов, совместно использующих один и тот же пул конфигурации машины. |
Пример: сопоставление на основе метки узла или модуля
- совпадение:
- метка: tuning.openshift.io/elasticsearch
соответствие:
- метка: node-role.kubernetes.io/master
- метка: node-role.kubernetes.io/infra
тип: стручок
приоритет: 10
профиль: openshift-control-plane-es
- соответствие:
- метка: node-role.kubernetes.io/master
- метка: node-role.kubernetes. io/infra
приоритет: 20
профиль: openshift-control-plane
- приоритет: 30
profile: openshift-node
io/infra
приоритет: 20
профиль: openshift-control-plane
- приоритет: 30
profile: openshift-node Приведенный выше CR переведен для контейнеризованного демона TuneD в его рекомендовать.conf на основе приоритетов профиля. Профиль с
наивысший приоритет ( 10 ) равен openshift-control-plane-es и поэтому считается первым. Контейнерный демон TuneD, работающий на заданном узле, проверяет, работает ли на том же узле модуль с установленной меткой tuningd.openshift.io/elasticsearch . В противном случае весь раздел оценивается как false . Если есть такой стручок с этикеткой, то для для оценки true , метка узла также должна быть node-role.kubernetes.io/master или node-role.kubernetes.io/infra .
Если метки для профиля с приоритетом 10 совпадают, применяется профиль openshift-control-plane-es и никакие другие профили не рассматриваются. Если комбинация меток узла/пода не совпадает, рассматривается профиль со вторым наивысшим приоритетом (
Если комбинация меток узла/пода не совпадает, рассматривается профиль со вторым наивысшим приоритетом ( openshift-control-plane ). Этот профиль применяется, если контейнерный модуль TuneD работает на узле с метками 9.1152 node-role.kubernetes.io/master или node-role.kubernetes.io/infra .
Наконец, профиль openshift-node имеет самый низкий приоритет 30 . В нем отсутствует раздел , поэтому совпадение будет всегда. Он действует как универсальный профиль для установки профиля openshift-node , если на данном узле нет другого профиля с более высоким приоритетом.
Пример: сопоставление на основе пула конфигурации машины
apiVersion: tuning.openshift.io/v1
вид: Тюнингованный
метаданные:
имя: openshift-node-custom
пространство имен: openshift-cluster-node-tuning-operator
спецификация:
профиль:
- данные: |
[главный]
summary=Пользовательский профиль узла OpenShift с дополнительным параметром ядра
include=openshift-узел
[загрузчик]
cmdline_openshift_node_custom=+skew_tick=1
имя: openshift-node-custom
рекомендовать:
- метки конфигурации машины:
machineconfiguration. openshift.io/role: "рабочий-пользовательский"
приоритет: 20
профиль: openshift-node-custom
openshift.io/role: "рабочий-пользовательский"
приоритет: 20
профиль: openshift-node-custom Чтобы свести к минимуму количество перезагрузок узлов, пометьте целевые узлы меткой, которой будет соответствовать селектор узлов пула конфигурации машин, затем создайте настроенный CR выше и, наконец, создайте сам настраиваемый пул конфигурации машин.
Профили по умолчанию, установленные в кластере
Ниже приведены профили по умолчанию, установленные в кластере.
версия API: tuning.openshift.io/v1
вид: Тюнингованный
метаданные:
имя: по умолчанию
пространство имен: openshift-cluster-node-tuning-operator
спецификация:
рекомендовать:
- профиль: "openshift-control-plane"
приоритет: 30
соответствие:
- метка: "node-role.kubernetes.io/master"
- метка: "node-role.kubernetes.io/infra"
- профиль: "openshift-узел"
приоритет: 40 9{} \; Поддерживаемые подключаемые модули демона TuneD
За исключением раздела [main] , следующие подключаемые модули TuneD поддерживаются при
используя пользовательские профили, определенные в разделе profile: Tuned CR:
аудио
процессор
диск
eeepc_she
модуля
крепления
нетто
планировщик
scsi_host
селинукс
sysctl
системная файловая система
USB
видео
вм
загрузчик
Некоторые из этих подключаемых модулей предоставляют некоторые функции динамической настройки.
что не поддерживается. Следующие плагины TuneD в настоящее время не поддерживаются:
скрипт
системд
Подключаемый модуль загрузчика TuneD в настоящее время поддерживается на рабочих узлах Red Hat Enterprise Linux CoreOS (RHCOS) 8.x. Для рабочих узлов Red Hat Enterprise Linux (RHEL) 7.x подключаемый модуль загрузчика TuneD в настоящее время не поддерживается. |
См.
Доступный
Плагины TuneD и
Получающий
Начал с TuneD для получения дополнительной информации.
Настройка максимального количества модулей на узел
Два параметра управляют максимальным количеством модулей, которые могут быть запланированы для узла: podsPerCore и maxPods . Если вы используете оба параметра, нижний из двух ограничивает количество модулей на узле.
Например, если для podsPerCore установлено значение 10 на узле с 4 процессорными ядрами, максимальное количество pod, разрешенное на узле, будет равно 40.
Предварительные условия
Получить метку, связанную со статическим
MachineConfigPoolCRD для типа узла, который вы хотите настроить.
Выполните один из следующих шагов:Просмотр пула конфигурации машин:
$ oc описать machineconfigpool <имя>
Например:
$ oc описать работника machineconfigpool
Пример вывода
apiVersion: machineconfiguration.openshift.io/v1 вид: Машинконфигпул метаданные: СозданиеTimestamp: 2019-02-08T14:52:39Z поколение: 1 этикетки: custom-kubelet: маленькие стручки (1)1 Если метка была добавлена, она отображается под метками.Если метка отсутствует, добавьте пару ключ/значение:
$ oc label machineconfigpool worker custom-kubelet=small-pods
В качестве альтернативы вы можете применить следующий YAML для добавления метки:
версия API: machineconfiguration.
 openshift.io/v1
вид: Машинконфигпул
метаданные:
этикетки:
custom-kubelet: маленькие стручки
имя: рабочий
openshift.io/v1
вид: Машинконфигпул
метаданные:
этикетки:
custom-kubelet: маленькие стручки
имя: рабочий
Процедура
Создайте пользовательский ресурс (CR) для изменения конфигурации.
Пример конфигурации для
max-podsCRapiVersion: machineconfiguration.openshift.io/v1 вид: KubeletConfig метаданные: имя: set-max-pods (1) спецификация: машинаКонфигпулселектор: метки соответствия: custom-kubelet: маленькие капсулы (2) кубелетКонфигурация: podsPerCore: 10 (3) maxPods: 250 (4)1 Присвойте имя CR. 2 Укажите метку для применения изменения конфигурации. 3 Укажите количество модулей, которые может запускать узел, в зависимости от количества ядер процессора на узле. 
4 Укажите фиксированное количество модулей, которые может запускать узел, независимо от свойств узла. Установка
podsPerCoreна0отключает это ограничение.В приведенном выше примере значение по умолчанию для
podsPerCore—10, а значение по умолчанию дляmaxPods—250. Это означает, что если узел не имеет 25 ядер или более, по умолчанию ограничивающим фактором будетpodsPerCore.Список
MachineConfigPoolCRD, чтобы проверить, применено ли изменение. СтолбецОБНОВЛЕНИЕсообщаетTrue, если изменение принимается Контроллером конфигурации машины:$ oc получить пулы конфигурации машин
Пример вывода
НАЗВАНИЕ КОНФИГУРАЦИЯ ОБНОВЛЕНО ОБНОВЛЕНИЕ ДЕГРАДИРОВАНО master master-9cc2c72f205e103bb534 Ложь Ложь Ложь рабочий worker-8cecd1236b33ee3f8a5e False True False
После завершения изменения
ОБНОВЛЕНОстолбец сообщаетTrue.
$ oc получить пулы конфигурации машин
Пример вывода
НАЗВАНИЕ КОНФИГУРАЦИЯ ОБНОВЛЕНО ОБНОВЛЕНИЕ ДЕГРАДИРОВАНО master master-9cc2c72f205e103bb534 False True False рабочий worker-8cecd1236b33ee3f8a5e Верно Ложно Ложно
Mamiya-Sekor Z 127 мм F/3,8 Вт
Стабилизатор изображения
Технология, используемая для уменьшения или даже устранения эффекта дрожания камеры. Гироскопические датчики внутри объектива обнаруживают дрожание камеры и передают данные на микрокомпьютер. Затем группа элементов стабилизации изображения, управляемая микрокомпьютером, перемещается внутри объектива и компенсирует дрожание камеры, чтобы изображение оставалось статичным на датчике изображения или пленке.
Технология позволяет увеличить выдержку на несколько ступеней и снимать с рук в таких условиях освещения и на таких фокусных расстояниях, когда без стабилизатора изображения приходится использовать штатив, уменьшать выдержку и/или увеличивать значение ISO, что может привести к размытые и шумные изображения.
Формат
Формат относится к форме и размеру пленки или датчика изображения.
35 мм — это общее название формата пленки 36×24 мм или формата датчика изображения. Он имеет соотношение сторон 3:2 и размер по диагонали примерно 43 мм. Название происходит от общей ширины пленки 135, которая была основным носителем формата до изобретения полнокадровой цифровой зеркальной фотокамеры. Исторически формат 35 мм иногда называли малым форматом, чтобы отличить его от среднего и большого форматов.
APS-C — это формат датчика изображения, примерно эквивалентный по размеру пленочным негативам 25,1×16,7 мм с соотношением сторон 3:2.
Средний формат — это пленочный формат или формат датчика изображения размером больше 36×24 мм (35 мм), но меньше 4×5 дюймов (большой формат).
Угол обзора
Угол обзора описывает угловой размер данной сцены, отображаемой камерой. Он используется взаимозаменяемо с более общим термином поле зрения.
При изменении фокусного расстояния изменяется и угол обзора. Чем короче фокусное расстояние (например, 18 мм), тем шире угол обзора. И наоборот, чем больше фокусное расстояние (например, 55 мм), тем меньше угол обзора.
Чем короче фокусное расстояние (например, 18 мм), тем шире угол обзора. И наоборот, чем больше фокусное расстояние (например, 55 мм), тем меньше угол обзора.
Угол обзора камеры зависит не только от объектива, но и от сенсора. Датчики изображения иногда меньше кадра 35-мм пленки, и это приводит к тому, что объектив имеет более узкий угол обзора, чем с 35-мм пленкой, на определенный коэффициент для каждого датчика (называемый коэффициентом обрезки).
Этот веб-сайт не использует углы обзора, предоставляемые производителями объективов, а рассчитывает их автоматически по следующей формуле: 114,6 * арктангенс (21,622 / CF * FL),
, где:
CF – кроп-фактор сенсора,
FL – фокусное расстояние объектива.
Крепление
Крепление объектива — это интерфейс — механический, а часто и электрический — между корпусом камеры и объективом.
Крепление объектива может быть резьбовым, байонетным или затворным. Современные крепления объектива камеры относятся к байонетному типу, потому что байонетный механизм точно выравнивает механические и электрические характеристики между объективом и корпусом, в отличие от креплений с резьбой.
Байонеты конкурирующих производителей (Canon, Nikon, Pentax, Sony и т.д.) всегда несовместимы. В дополнение к различным механическим и электрическим интерфейсам, фокусное расстояние фланца также может быть различным.
Фокусное расстояние фланца (FFD) — это расстояние от механической задней торцевой поверхности крепления объектива до фокальной плоскости.
Конструкция линзы
Конструкция линзы – определенное расположение элементов и групп, составляющих оптическую схему, включая тип и размер элементов, тип используемых материалов и т. д.
Элемент – отдельный кусок стекла, составляющий один компонент фотообъектива. Фотообъективы почти всегда состоят из нескольких таких элементов.
Группа – склеенные между собой куски стекла, образующие единое целое или отдельное стекло. Преимущество в том, что между склеенными между собой кусками стекла нет стекловоздушной поверхности, что снижает отражения.
Скорость
Наибольшее открытие или диафрагма, при которой можно использовать объектив, называется светосилой объектива. Чем больше максимальная диафрагма, тем светосильнее считается объектив. Объективы с большой максимальной апертурой обычно называют светосильными, а линзы с меньшей максимальной апертурой считаются медленными.
Чем больше максимальная диафрагма, тем светосильнее считается объектив. Объективы с большой максимальной апертурой обычно называют светосильными, а линзы с меньшей максимальной апертурой считаются медленными.
В условиях низкой освещенности более широкая максимальная диафрагма означает, что вы можете снимать с более короткой выдержкой или работать с более низким значением ISO, или и то, и другое.
Количество лепестков
Как правило, чем больше лепестков используется для создания отверстия диафрагмы в объективе, тем более круглыми будут блики вне фокуса.
Некоторые объективы имеют изогнутые лепестки диафрагмы, поэтому округлость диафрагмы достигается не количеством лепестков, а их формой. Однако чем меньше лепестков у диафрагмы, тем сложнее сформировать круг, независимо от закругленных краев.
При максимальной диафрагме отверстие будет круглым независимо от количества лепестков.
Максимальный диаметр x длина
За исключением футляра или чехла, крышек и других съемных аксессуаров (бленда объектива, адаптер для макросъемки, адаптер для штатива и т. д.).
д.).
Для объективов разборной конструкции длина указана для рабочего (убранного) состояния.
Бленда объектива
Бленда объектива или бленда объектива — это устройство, используемое на конце объектива для защиты от солнца или другого источника света, чтобы предотвратить блики и блики объектива. Блик возникает, когда рассеянный свет попадает на передний элемент объектива, а затем отражается внутри объектива. Этот рассеянный свет часто исходит от очень ярких источников света, таких как солнце, яркий студийный свет или яркий белый фон.
Геометрия бленды объектива может варьироваться от простой цилиндрической или конической формы до более сложной формы, иногда называемой лепестком, тюльпаном или цветочной блендой. Это позволяет бленде объектива блокировать рассеянный свет с помощью более высоких частей бленды объектива, в то же время позволяя большему количеству света попадать в углы изображения через опущенные части бленды.
Бленды более заметны в длиннофокусных объективах, поскольку они имеют меньший угол обзора, чем широкоугольные объективы.
