Сечение арматуры таблица: Таблица арматуры. Площадь поперечного сечения
Содержание
2.4. Подбор сечения арматуры
Армирование плиты может производиться
в виде отдельных стержней, сварных
рулонных или плоских сеток. Подбор
рабочей продольной арматуры в каждом
сечении плиты определяется по
соответствующим изгибающим моментам,
как для изгибаемых элементов прямоугольного
сечения с одиночной арматурой.
Подбор
сечений арматуры производится в
соответствии с расчетной схемой,
показанной на рис. 2.4, и структурой 2
(рис. 2.6).
Пример
2.4.
Рассчитать количество рабочей продольной
арматуры в первом пролете плиты при ее
армировании индивидуальными плоскими
сетками.
Исходные данные (по примеру 2.2 и 2.3):
кНм;
fcd=10,7 Н/мм2
Рис.
2.6. Структура 2 Подбор площади сечения
арматуры для изгибаемого элемента
прямоугольного сечения с одиночным
армированием
Арматура
класса S400 Н/мм2
Граничное
значение относительной высоты сжатой
зоны бетона
По
таблице П. 4 Приложения по
4 Приложения по
определяем
Требуемая площадь
сечения рабочей арматуры
мм2
Проверяем
По
таблице 2.3 принимаем сварную плоскую
сетку с рабочими стержнями 8
класса S400,
установленными с шагом 150 мм.
Распределительная арматура – 4
класса S500,
устанавливается с шагом 350 мм согласно
таблице 2.4.
Аналогично
рассчитываются площади сечения арматуры
в средних пролетах и на опорах.
Окончательно
площадь сечения арматуры, принятая по
расчету для расчетных полос I
и II
плиты, приведена на рис. 2.7.
По
расчетной площади арматуры Аst
подбирают рабочую и распределительную
арматуру плиты, используя таблицы 2.3 и
2.4. При толщине плиты hs<150 мм
расстояние между осями стержней рабочей
арматуры в средней части пролета плиты
(внизу) и над опорой (вверху) многопролетных
плит должно быть не более 200 мм,
при hs>150 мм
– не более 1,5hs.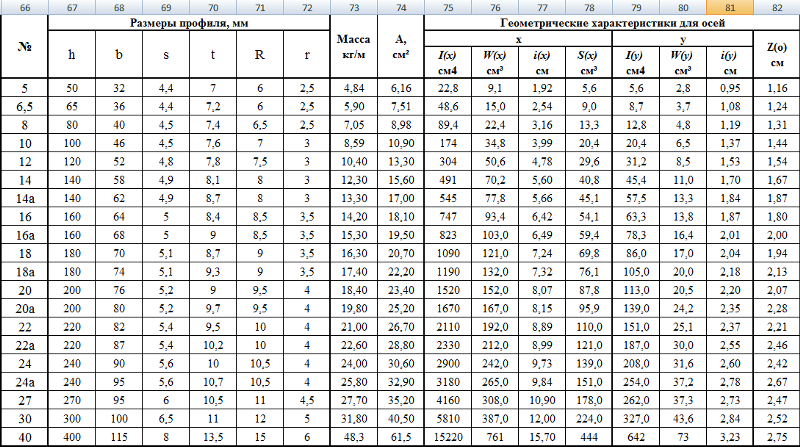
Расстояние
между рабочими стержнями, доводимыми
до опоры плиты, не должно превышать
400 мм,
причем площадь сечения этих стержней
на 1 м
ширины плиты должна составлять не менее
30% площади сечения стержней в пролете,
определенной расчетом по наибольшему
изгибающему моменту.
Площадь
сечения распределительной арматуры в
плитах должна составлять не менее 10%
площади сечения рабочей арматуры в
месте наибольшего изгибающего момента.
Диаметр и шаг стержней этой арматуры,
в зависимости от диаметра и шага стержней
рабочей арматуры, можно принимать по
таблице 2.4.
Рис.
2.7. Площадь арматуры плиты, принятая по
расчету
Таблица
2.3
Площадь
поперечного сечения арматуры на 1 м
ширины плиты, мм2
Шаг | Диаметр | ||||||||
3 | 4 | 5 | 6 | 8 | 10 | 12 | 14 | 16 | |
100 | 71 | 126 | 196 | 283 | 503 | 785 | 1131 | 1539 | 2011 |
125 | 57 | 101 | 157 | 226 | 402 | 628 | 905 | 1231 | 1608 |
150 | 47 | 84 | 131 | 184 | 335 | 523 | 754 | 1026 | 1340 |
200 | 35 | 63 | 98 | 141 | 251 | 393 | 565 | 769 | 1005 |
250 | 28 | 50 | 79 | 113 | 201 | 314 | 452 | 616 | 804 |
300 | 23 | 42 | 65 | 94 | 168 | 261 | 377 | 513 | 670 |
350 | 20 | 36 | 56 | 81 | 144 | 224 | 323 | 444 | 574 |
400 | 18 | 32 | 49 | 71 | 125 | 196 | 282 | 350 | 502 |
Таблица
2. 4
4
Диаметр
и шаг стержней min
распределительной арматуры балочных
плит, мм
Диаметр | Шаг | |||||
100 | 125 | 150 | 200 | 250 | 300 | |
3…4 | ||||||
5 | ||||||
6 | ||||||
8 | ||||||
10 | ||||||
12 | ||||||
14 | ||||||
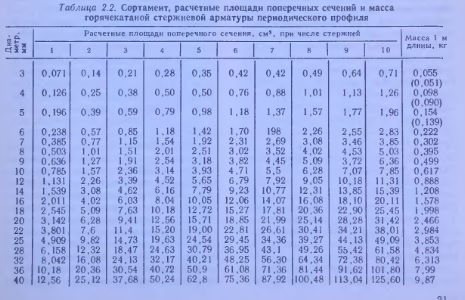
Сортамент арматуры, характеристики, вес погонного метра, таблица
Строительная арматура является популярной разновидностью металлопроката. Ее технические показатели и характеристики регламентируются ГОСТом и находят отражение в соответствующих нормативных таблицах сортамента.
Ее технические показатели и характеристики регламентируются ГОСТом и находят отражение в соответствующих нормативных таблицах сортамента.
Классы стальной арматуры
Изделия из сортового металлопроката разделяют по механическим свойствам и прочности. Для обозначения сортамента применяют литеру «А» с цифровым индексом, указывающим на принадлежность к определенному классу.
- А1 (AI, А240) – монтажный прокат в виде гладкостенного прута с диаметром профиля 6-40 мм. Используется в производстве ЖБИ, монолитных и сварных несущих конструкций. Арматуру всех видов сечения выпускают в стержнях, упакованных в пачки. Изделия до 12 мм также производят в мотках.
- А2 (АII, А300) – с рифленым профилем 10-80 мм. Относится к категории силовых элементов, несущих основную нагрузку конструкции. Применяется в строительстве малоэтажных домов, монолитных сооружений, ремонтных работах.
- А3 (АIII, а400, А500) – прутья с периодическим профилем 6-40 мм. Это наиболее востребованный вид, используется в строительстве объектов жилого, промышленного и коммерческого назначения, производстве ЖБИ, устройстве автомобильных дорог и тротуаров.
 Все диаметры выпускают в стержнях, сечение до 10 мм дополнительно изготавливают в мотках.
Все диаметры выпускают в стержнях, сечение до 10 мм дополнительно изготавливают в мотках. - А4 (АIV, А600) – рабочего типа, 10-32 мм. Применяются в строительстве напряженных элементов. Внешне похожи на А3, но с меньшей частотой ребер.
- А5 (А800) – редкий представитель сортамента арматуры, обладает повышенной прочностью. Используется при сооружении крупногабаритных и сверхтяжелых объектов: метро, морские причалы, ГЭС.
- А6 (А1000) – изготавливается из термоустойчивой стали. Обладает повышенной сопротивляемостью к различным деформациям. Подходит для многоэтажного строительства.
Существует дополнительная маркировка, содержащая информацию об особых свойствах стального сортамента.
- С – возможность сваривания. Литера «С» добавляется в окончание основного шифра, например, а500с.
- К – повышенная стойкость арматуры к коррозийному растрескиванию поверхности при различных напряжениях. Такие пруты покрывают специальным защитным составом, препятствующим окислению металла.
- СК – свариваемые антикоррозийные прутья.
- Т – добавляется в маркировку редких классов (А600, А1000) и свидетельствует о специальной обработке стальной основы.
В конце шифра указывают диаметр, окончательная маркировка выглядит таким образом: а400с Ø14.
Нормативные таблицы
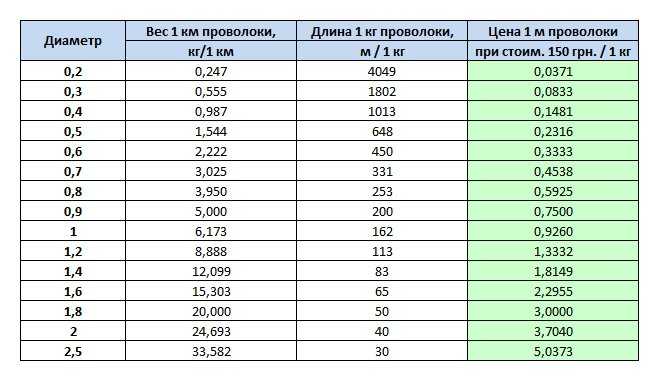
Перед сооружением стального каркаса делают предварительный расчет нагрузки на него, исходя из полученных данных подбирают стержни определенного диаметра. Для этого удобно пользоваться таблицей сечений. Частным застройщикам проще делать расчеты металлопроката в метраже или количестве, а торговые компании зачастую указывают цены за тонну. Для правильного перевода длины в массу можно воспользоваться таблицей веса арматуры.
Чтобы не тратить много времени на поиск прокатной маркировки и сортировку стальных прутьев, их концы покрывают несмываемым красителем. Соответствие цвета каждому классу отражается в специальной таблице.
| Класс | Цвет |
| А400С | Белый |
| А500С | Белый+синий |
| Ат600 | Желтый |
| Ат600С | Желтый+белый |
| Ат600К | Желтый +красный |
| Ат800 | Зеленый |
| Ат800К | Зеленый + красный |
| Ат1000 | Синий |
| Ат1000К | Синий + красный |
| Ат1200 | Черный |
ГОСТы, регламентирующие нормативные характеристики арматуры, содержат перечень разных параметров, объединяемых понятием сортамент. Его представляют в форме таблицы, содержащей данные по площади поперечного сечения и весу погонного метра для всех диаметров металлопроката.
| № профиля (диаметр прута), мм | Площадь поперечного сечения, см2 | Вес, кг/пог.м. |
| 6 | 0,283 | 0,222 |
| 8 | 0,503 | 0,395 |
| 10 | 0,785 | 0,617 |
| 12 | 1,131 | 0,888 |
| 14 | 1,54 | 1,21 |
| 16 | 2,01 | 1,58 |
| 18 | 2,54 | 2,0 |
| 20 | 3,14 | 2,47 |
| 22 | 3,8 | 2,98 |
| 25 | 4,91 | 3,85 |
| 28 | 6,16 | 4,83 |
| 32 | 8,04 | 6,31 |
| 36 | 10,18 | 7,99 |
| 40 | 12,57 | 9,87 |
| 45 | 15,00 | 12,48 |
| 50 | 19,63 | 15,41 |
| 55 | 23,76 | 18,65 |
| 60 | 28,27 | 22,19 |
| 70 | 38,48 | 30,21 |
| 80 | 50,27 | 39,46 |
5.
 1.1 Требуемое армирование поперечным сечением
1.1 Требуемое армирование поперечным сечением
Онлайн-руководства, вводные примеры, учебные пособия и другая документация
Дом
Загрузки и информация
Документы
Онлайн-руководства
RF-/CONCRETE Члены 5/8
5 результатов
5.1 Требуемое усиление
5.1.1 Требуемое армирование по поперечному сечению
Необходимое усиление по поперечному сечению
В таблице показаны максимальные площади армирования всех проанализированных элементов, которые определяются на основе внутренних сил загружений, комбинаций нагрузок и результатов, выбранных для расчетного предельного состояния.
Рисунок 5.2 Окно 2.1 Требуемое усиление по поперечному сечению
Программа отображает максимальные требуемые площади армирования, вытекающие из параметров групп армирования и внутренних сил управляющих воздействий для всех расчетных сечений.
Участки армирования продольной и поперечной арматуры сортируются по поперечным сечениям.
В обеих частях окна отображаются типы армирования и детали конструкции, выбранные в Results to Display диалоговое окно (см. рис. 5.3).
рис. 5.3).
В нижней части окна перечислены все подробных результатов для строки таблицы, выбранной выше.
Эти детали дизайна позволяют проводить конкретную оценку результатов.
Если вы выберете другую строку таблицы в верхней части, подробные результаты будут автоматически обновлены в нижней части.
Усиление
Заданы следующие продольная и поперечная арматуры:
| Армирование | Объяснение |
|---|---|
A с,-z(верхний) | Площадь усиления требуемой верхней продольной арматуры из-за осевой силы или изгиба с осевой силой или без нее |
A с,+z(внизу) | Площадь усиления необходимой нижней продольной арматуры за счет осевой силы или изгиба с осевой силой или без нее |
А с,Т | Площадь усиления торсионной осевой арматуры, если требуется |
a SW, V, стремя | Площадь требуемой поперечной арматуры для поглощения поперечной силы относительно стандартной длины 1 м |
a SW, T, стремя | Площадь требуемой поперечной арматуры для поглощения крутящего момента относительно стандартной длины 1 м |
a sf,-z(сверху) | Площадь требуемой поперечной арматуры для восприятия поперечных усилий между стенкой балки и полками со стороны -z поперечного сечения, относительно стандартной длины 1 м |
a SW, T, стремя | Площадь требуемой поперечной арматуры для поглощения поперечных усилий между стенкой балки и полками со стороны +z относительно стандартной длины 1 м |
Верхняя арматура определяется со стороны элемента в направлении отрицательной локальной оси элемента z (-z), нижняя арматура, соответственно, в направлении положительной оси z (+z). Для отображения осей стержня используйте навигатор Отобразить в графическом пользовательском интерфейсе RFEM или контекстное меню стержня (см. Рисунок 3.32).
Для отображения осей стержня используйте навигатор Отобразить в графическом пользовательском интерфейсе RFEM или контекстное меню стержня (см. Рисунок 3.32).
Нажмите кнопку [Для отображения], чтобы открыть диалоговое окно, в котором можно указать результаты армирования, которые должны отображаться в верхней части окна.
Рисунок 5.3 Диалоговое окно результатов для отображения
Настройки в этом диалоговом окне также управляют выводом результатов в отчет!
Член №
Для каждого поперечного сечения и каждого типа армирования в таблице указано количество стержней с максимальной площадью армирования.
Расположение x
В столбце показано положение x на стержне, для которого программа определила максимальное армирование.
Следующие местоположения членов RFEM x используются для вывода таблицы:
- Начальный и конечный узел
- Точки деления в соответствии с делением стержня, если указано (см.
 таблицу RFEM 1.16)
таблицу RFEM 1.16) - Разделение стержня в соответствии со спецификацией для результатов стержня (вкладка Глобальные параметры расчета диалогового окна Параметры расчета в RFEM)
- Экстремальные значения внутренних сил
LC/CO/RC
В этом столбце показаны номера загружений, нагрузок или расчетных комбинаций, которые являются определяющими для соответствующих расчетов.
Зона усиления
Для каждого типа армирования в столбце E указаны максимальные площади армирования, необходимые для расчетного предельного состояния.
Единиц подкрепления, показанных в столбце F, можно настроить с помощью пункта меню.
- Настройки → Единицы и десятичные разряды .
Откроется диалоговое окно, описанное в главе 8.3.
Сообщение об ошибке или примечание
В последнем столбце указаны ситуации, не подлежащие проектированию, или примечания, относящиеся к проблемам проектирования.
Цифры объясняются в строке состояния.
Используйте кнопку, показанную слева, чтобы просмотреть все [Сообщения] текущего варианта дизайна.
Рисунок 5.4 Сообщения об ошибках или примечания к диалоговому окну Design Process
Краткий обзор этого раздела
- Требуется армирование поперечным сечением
Краткий обзор этого раздела
- Требуется армирование поперечным сечением
- Усиление
- Участник №
- Местоположение х
- ЛК/СО/RC
- Зона усиления
- Сообщение об ошибке или примечание
Обучение с подкреплением с таблицами Q | by Mohit Mayank
Обучение с подкреплением — действие агента и ответ среды
Обучение с подкреплением — это область машинного обучения, связанная с отсроченным вознаграждением.
Что это значит? Ну, просто, поясню на примере. Для этого я предполагаю, что вы слышали (лучше, если знаете) о нейронных сетях или даже базовые знания о регрессии или классификации.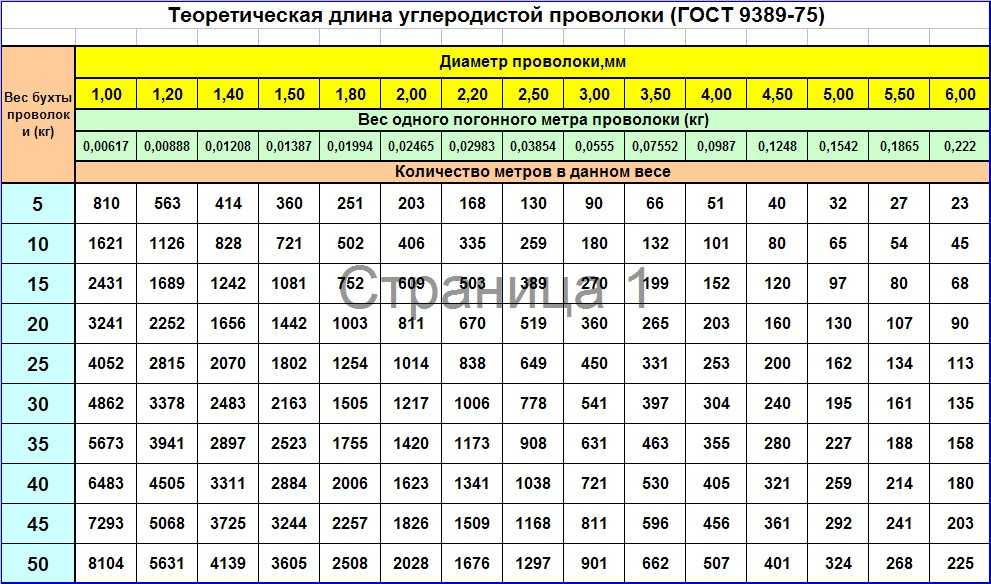 Итак, давайте возьмем пример задачи классификации: вам дан большой кусок изображений собак, и вам нужно разработать систему, которая сможет различать изображения, определяя, принадлежат ли они собакам или нет. Любой, кто хоть немного разбирается в машинном обучении, посоветует вам использовать нейронную сеть свертки и тренироваться с предоставленными изображениями, и да, это сработает. Но как? Ну, не вдаваясь в подробности (может быть, статья об этом позже?!), вы сначала обучаете нейронную сеть на образцах изображений. Во время обучения нейронная сеть изучает маленькие особенности и шаблоны, уникальные для изображения собаки. Во время обучения вы знаете ожидаемый результат, это изображения собак, поэтому всякий раз, когда сеть предсказывает неправильно, мы исправляем это. В некотором смысле, мы знаем вознаграждение за предоставленные изображения: если предсказание верное, мы даем положительное вознаграждение, если предсказание неверное, вознаграждение отрицательное, и принимаются корректирующие меры для обучения и адаптации.
Итак, давайте возьмем пример задачи классификации: вам дан большой кусок изображений собак, и вам нужно разработать систему, которая сможет различать изображения, определяя, принадлежат ли они собакам или нет. Любой, кто хоть немного разбирается в машинном обучении, посоветует вам использовать нейронную сеть свертки и тренироваться с предоставленными изображениями, и да, это сработает. Но как? Ну, не вдаваясь в подробности (может быть, статья об этом позже?!), вы сначала обучаете нейронную сеть на образцах изображений. Во время обучения нейронная сеть изучает маленькие особенности и шаблоны, уникальные для изображения собаки. Во время обучения вы знаете ожидаемый результат, это изображения собак, поэтому всякий раз, когда сеть предсказывает неправильно, мы исправляем это. В некотором смысле, мы знаем вознаграждение за предоставленные изображения: если предсказание верное, мы даем положительное вознаграждение, если предсказание неверное, вознаграждение отрицательное, и принимаются корректирующие меры для обучения и адаптации.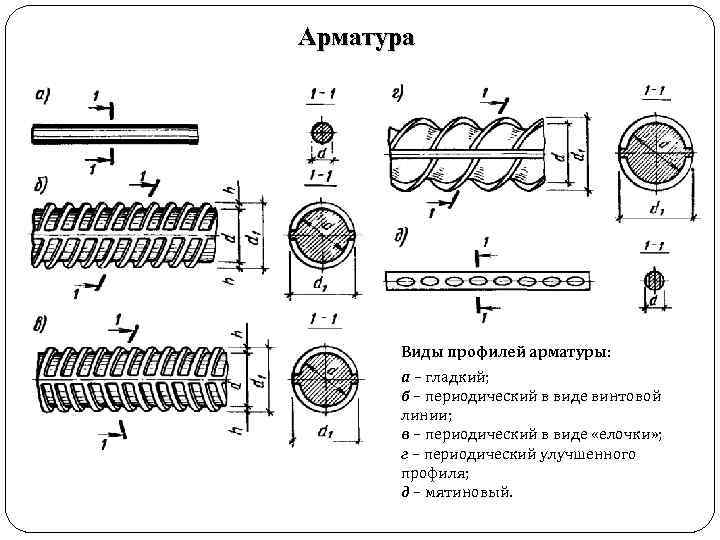 Итак, мы знаем немедленную награду.
Итак, мы знаем немедленную награду.
Но что, если мы не знаем немедленных наград? Здесь на помощь приходит обучение с подкреплением.
Чтобы объяснить это, давайте создадим игру. Игра простая, в ряду 10 плиток. Все плитки не равны, у некоторых есть дырка, куда мы не хотим идти, а у некоторых есть пиво, куда мы определенно хотим идти. Когда игра начинается, вы можете появляться на любой из плиток и идти либо влево, либо вправо. Игра будет продолжаться до тех пор, пока мы не выиграем или игра не закончится, давайте назовем каждую такую итерацию эпизодом.
За пивом!!
Итак, если вы появляетесь на 0-м тайле или каким-то образом перемещаетесь на 0-й тайл, игра окончена, но если мы попадаем на 6-й тайл, мы выигрываем.
Возьмем для примера один простой эпизод. Хорошо, скажем, мы появляемся на плитке 2. Теперь предположим, что я не показывал вам игровую карту, и у вас есть только возможность идти влево или вправо, в какую сторону вы пойдете? Ну, вы не можете сказать, пока не попробуете. Допустим, вы продолжаете идти влево, пока не окажетесь на плитке 0, плитке с дыркой и проиграете. Это не то, чего мы хотим, поэтому давайте назначим отрицательную награду нашему действию по переходу влево от 2 к 1 и 0. В следующем эпизоде вы по какой-то случайности снова появляетесь на плитке 2, на этот раз вы продолжаете двигаться вправо, пока вы достигаете плитки 6. Здесь у нас есть пиво, давайте назначим действия с положительной наградой.
Допустим, вы продолжаете идти влево, пока не окажетесь на плитке 0, плитке с дыркой и проиграете. Это не то, чего мы хотим, поэтому давайте назначим отрицательную награду нашему действию по переходу влево от 2 к 1 и 0. В следующем эпизоде вы по какой-то случайности снова появляетесь на плитке 2, на этот раз вы продолжаете двигаться вправо, пока вы достигаете плитки 6. Здесь у нас есть пиво, давайте назначим действия с положительной наградой.
Что мы узнали? за каждый наш шаг, пока мы не попадем в яму или пиво, мы не знаем о наградах. Задержка вознаграждения, ребята. Нет никого, кто укажет вам правильное направление, после каждого шага нет награды, подсказывающей правильное или неправильное направление. Сейчас нам даже трудно уловить смысл правильных действий, а если мы хотим, чтобы компьютер научился этому? Обучение с подкреплением в помощь.
Что же это за марковский процесс и зачем нам его изучать? Ну, я думал так же, и, чтобы быть ясным, нам не нужно глубоко погружаться в это, достаточно простой интуиции.
Таким образом, марковский процесс принятия решений используется для моделирования принятия решений в ситуациях, когда исходы частично случайны и частично находятся под контролем лица, принимающего решения. Короче говоря, все плитки, левое и правое действия, отрицательное и положительное вознаграждение, которые мы обсуждали, могут быть смоделированы марковским процессом.
Марковский процесс принятия решений состоит из
- Состояние (S) : Это набор состояний. Плитка в нашем примере. Итак, у нас есть 10 состояний в нашей игре.
- Действие (A) : Это набор действий, доступных из состояния
s. Слева и справа от нашей игры. - Вероятность перехода
P(s'|s, a): Это вероятность перехода в состояниеs'в момент времениt+1, если мы предпримем действиеaв состоянииsв моментт. На этом фронте мы были как бы отсортированы, слева от плитки 3 ведет к плитке 2, без вопросов.
- Награда
R(s'|s, a): Это награда, которую мы получаем, если переходим из состоянияsв состояниеs', выполняя действияa. - Скидка (Y) : Коэффициент скидки, который представляет собой разницу в будущих и настоящих вознаграждениях.
Изменение состояния в результате какого-либо действия. Так просто!
Таким образом, марковский процесс можно понимать как набор состояний S с некоторыми действиями A возможно из каждого состояния с некоторой вероятностью P . Каждое такое действие приведет к некоторому вознаграждению R . Если вероятность и вознаграждение неизвестны, проблема заключается в обучении с подкреплением. Здесь мы собираемся решить простую такую проблему, используя Q Learning или, лучше, самую базовую его реализацию, таблицу Q.
Теперь, принимая во внимание всю изученную выше теорию, мы хотим создать агента, который будет проходить нашу игру с пивом и дырками (в поисках лучшего имени), как человек. Для этого у нас должна быть политика, которая говорит нам, что делать и когда. Думайте об этом как о раскрытой карте игры. Чем лучше политика, тем выше наши шансы на победу в игре, отсюда и название Q (качественное) обучение. Качество нашей политики будет улучшаться по мере обучения и будет продолжать улучшаться. Чтобы узнать, мы собираемся использовать уравнение Беллмана, которое выглядит следующим образом:
Для этого у нас должна быть политика, которая говорит нам, что делать и когда. Думайте об этом как о раскрытой карте игры. Чем лучше политика, тем выше наши шансы на победу в игре, отсюда и название Q (качественное) обучение. Качество нашей политики будет улучшаться по мере обучения и будет продолжать улучшаться. Чтобы узнать, мы собираемся использовать уравнение Беллмана, которое выглядит следующим образом:
уравнение Беллмана для дисконтированных будущих вознаграждений
где,
-
Q(s,a)— текущая политика действийaиз штата max(Q(s’,a’)) определяет максимальное будущее вознаграждение. Скажем, мы предприняли действиеaв состоянииs, чтобы достичь состоянияs'. Отсюда у нас может быть несколько действий, каждое из которых соответствует некоторым вознаграждениям. Рассчитывается максимальное вознаграждение. -
Y— коэффициент скидки. Теперь значение варьируется от 0 до 1, если значение близко к 0, предпочтение отдается немедленному вознаграждению, а если значение приближается к 1, важность будущих вознаграждений увеличивается до тех пор, пока при значении 1 оно не будет считаться равным немедленному вознаграждению.
Здесь мы пытаемся сформулировать отсроченное вознаграждение в немедленное вознаграждение. Для каждого действия, которое мы предпринимаем из состояния, мы обновляем нашу таблицу политик, назовем ее Q-таблицей, чтобы включить положительное или отрицательное вознаграждение. Скажем, мы находимся на плитке 4 и собираемся повернуть направо, сделав плитку 5 следующим состоянием, немедленная награда за плитку 4 будет включать некоторый коэффициент (определяемый скидкой) максимального вознаграждения за все возможные действия с плитки. 5. И если вы сверитесь с игровой картой, то право с плитки 5 ведет к плитке 6, которая является конечной целью в нашей игре, поэтому правильное действие с плитки 4 также назначается некоторой положительной наградой.
Ладно, слишком много теории, давайте код.
Позвольте мне определить состояния, действия и награды в виде матрицы. Один из способов сделать это — иметь строки для всех состояний и столбцы для действий, поэтому, поскольку у нас есть 10 состояний и 2 действия, мы определим матрицу 10×2. Для простоты я не использую никакие библиотеки, просто кодирую их списками на python.
Для простоты я не использую никакие библиотеки, просто кодирую их списками на python.
environment_matrix = [[Нет, 0],
[-100, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 100],
[0 , 0],
[100, 0],
[0, 0],
[0, None]]
Как видите, движение вправо от плитки 5 и движение влево от плитки 7 дает высокую награду в 100, так как ведет к плитке 6. Также движение влево от плитки 1 ведет к дыре, поэтому отрицательное вознаграждение. Плитка 0 и 9 имеет левое и правое вознаграждение как Нет , так как нет -1 или 10-й плитки.
Теперь пришло время для нашей волшебной таблицы Q, которая будет обновляться по мере того, как агент узнает в каждом эпизоде.
q_matrix = [[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0]]
Для начала обнулим все.
Определение некоторой функции, помогающей в прохождении игры.
win_loss_states = [0,6]def getAllPossibleNextAction(cur_pos):
step_matrix = [x != Нет для x в environment_matrix[cur_pos]]
action = []
if(step_matrix[0]):
action.append( 0)
if(step_matrix[1]):
action.append(1)
return(action)def isGoalStateReached(cur_pos):
return (cur_pos в [6])def getNextState(cur_pos, action):
if (action == 0):
return cur_pos - 1
else:
return cur_pos + 1def isGameOver(cur_pos):
return cur_pos in win_loss_states
Давайте пройдемся по ним один за другим,
-
getAllPossibleNextActionпередайте ваше текущее состояние, и оно вернет все возможные действия. Обратите внимание, что для плитки 0 есть только правое действие, и то же самое касается плитки 9 только для левой стороны -
isGoalStateReached, если текущий тайл равен 6, он вернетTrue -
getNextStateпередать текущее состояние и действие, и он вернет следующее состояние -
isGameOverесли состояние 0 или 6, игра окончена, это возвращаетTrue
Теперь идет часть обучения,
скидка = 0,9
Learning_rate = 0,1for _ in range(1000):
# получить начальное место
cur_pos = random.choice([0,1,2, 3,4,5,6,7,8,9])
# пока целевое состояние не достигнуто
. выбранное действие
next_state = getNextState(cur_pos, action)
# обновить q_matrix
q_matrix[cur_pos][action] = q_matrix[cur_pos][action] + learning_rate * (environment_matrix[cur_pos][action] +
скидки * max( q_matrix[next_state]) - q_matrix[cur_pos][action])
# перейти к следующему состоянию
cur_pos = next_state
# вывести статус
print("Эпизод", _, "готово")print(q_matrix)
print("Тренировка завершена...")
Поясню,
- Сначала мы определили коэффициент дисконтирования и скорость обучения
- Мы собираемся тренироваться на 1000 эпизодов
- Спавн полностью случайный, это может быть любой из тайлов
- Пока эпизод не закончился, мы продолжаем выполнять случайные действия и обновление таблицы Q
After 1000 episodes, Q table some what looks like this,
[[0, 0], [-99.99999999730835, 65.60999997057485], [59.

